
基于基于python实现实现ROC曲线绘制广场解析曲线绘制广场解析
ROC
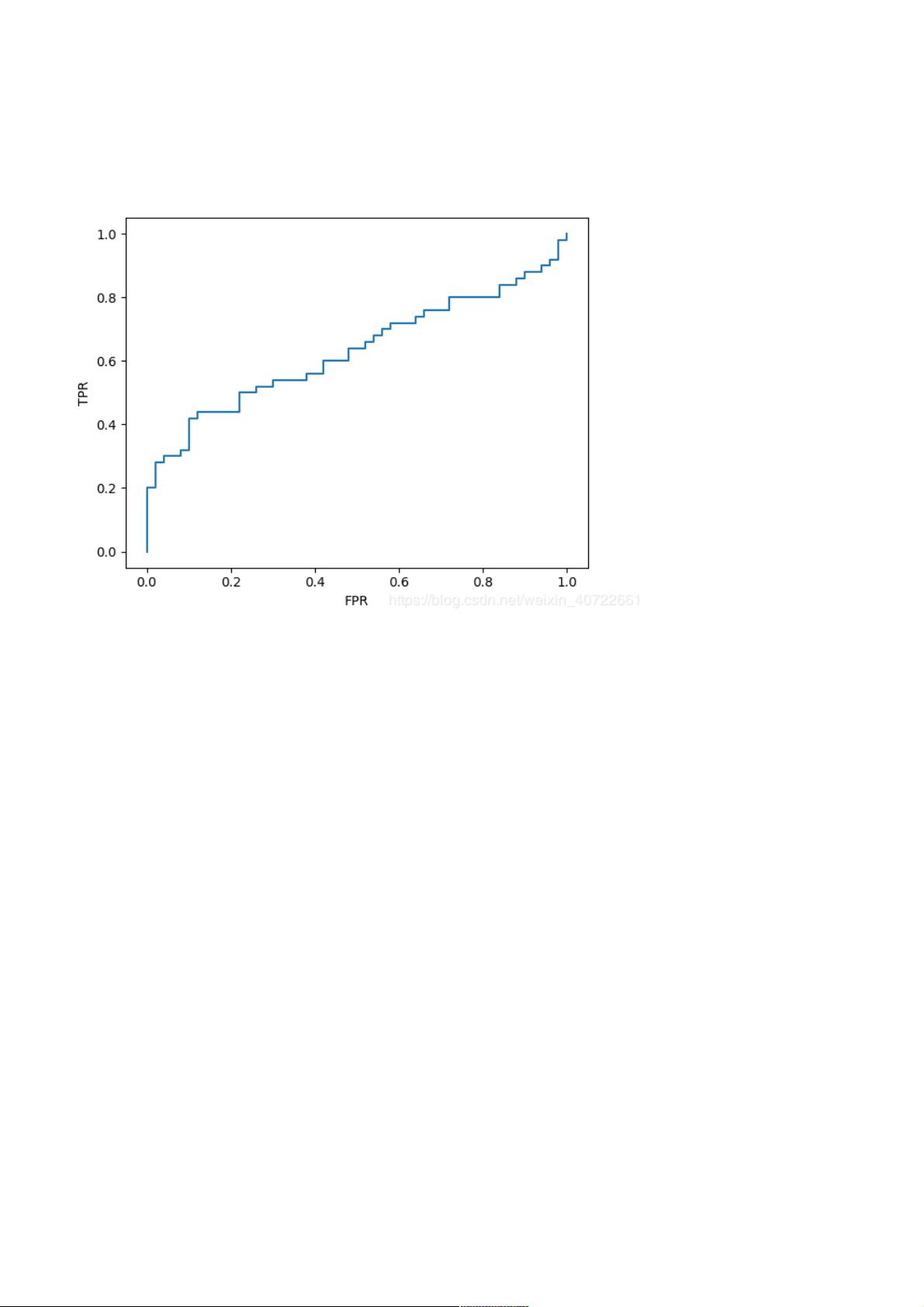
结果结果
源数据:鸢尾花数据集(仅采用其中的两种类别的花进行训练和检测)
Summary
features:[‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’]
实例:[5.1, 3.5, 1.4, 0.2] target:’setosa’ ‘versicolor’ (0 , 1)
采用回归方法进行拟合得到参数和bias
model.fit(data_train, data_train_label)
对测试数据进行预测得到概率值
res = model.predict(data[:100])
与训练集labels匹配后进行排序(从大到小)
pred labels
68 0.758208 1
87 0.753780 1
76 0.745833 1
50 0.743156 1
65 0.741676 1
75 0.739117 1
62 0.738255 1
54 0.737036 1
52 0.733625 1
77 0.728139 1
86 0.727547 1
74 0.726261 1
58 0.725150 1
71 0.724719 1
36 0.724142 0
14 0.723990 0
31 0.721648 0
41 0.720308 0
72 0.717723 1
79 0.712833 1
97 0.705148 1















