
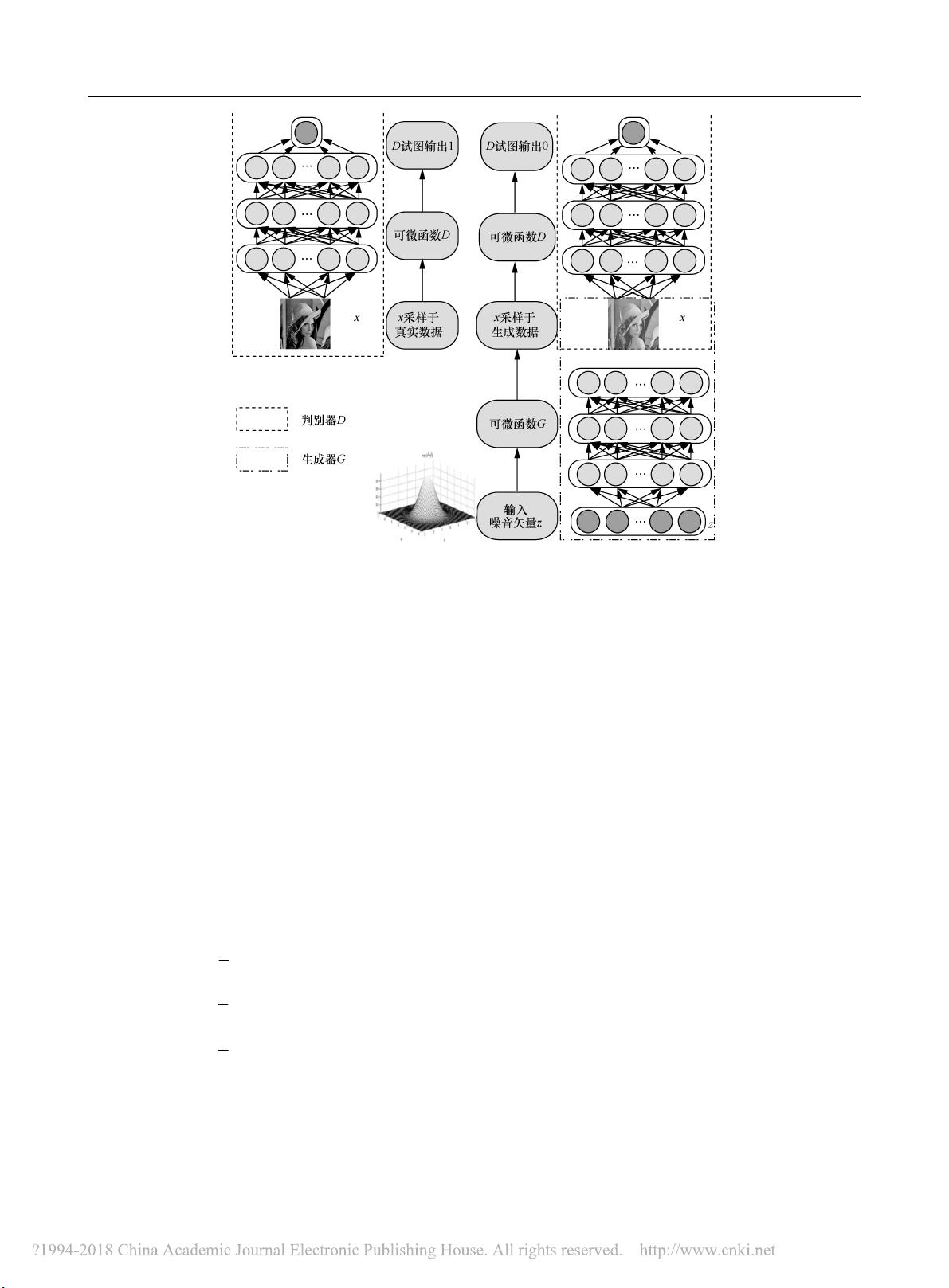
第 2 期 王万良等:生成式对抗网络研究进展 ·137·
成器 G 的目标函数 () ()JG JD=− 。因此,GAN 的
优化问题可描述为如下极大极小博弈问题。
(
)
(
)
()
()
()
()
data
~()
~
min max , E log
Elog1
xp x
G
D
p
VDG Dx
DG
=+⎡⎤
⎣⎦
⎡⎤
−
⎣⎦
z
zz
z
(2)
由于在训练初期缺乏足够训练,G 所生成的数
据不够逼真,因此,D 很容易就能将生成数据与真
实数据区分开来,导致 G 得不到足够梯度。因此,
文献[22]提出,通过最大化 logD(G(z))而不是最小化
log(1−D(G(z))来训练 G 是一个更好的策略。
2) 非饱和博弈
为了解决生成器的弱梯度问题,除了采用文
献[22]的方法外,还可以把极大极小博弈替换成非
饱和博弈,即
()
[]
()
[]
()
data
~
~
~
1
() E log()
2
1
E log(1 ( ( )))
2
1
() E log (())
2
xp x
p
p
JD Dx
DG
JG DG
⎧
=− −
⎪
⎪
⎪
−
⎨
⎪
⎪
=−
⎪
⎩
z
z
zz
zz
z
z
(3)
换言之,G 用自己的伪装能力来表示自己的目标
函数,而不是简单直接地取 J(D)的相反数。从而均衡
不再完全由价值函数 min max V(G,D)决定,即使 D 准
确地拒绝了所有生成样本,G 仍可以继续学习。
2.3 泛化模型
Goodfellow 等
[22]
从博弈论的角度阐释了 GAN
的思想,即 GAN 的训练目标是使生成器 G 与判别
器 D 达到纳什均衡,此时,生成模型 G 产生的数
据分布完全拟合真实数据分布。若从信息论角度理
解,GAN 所最小化的实际上是真实数据分布和生成
分布之间的 Jensen-Shannon 散度。Goodfellow
[37]
认
为 Kullback-Leibler 散度比 Jensen-Shannon 散度更
适用于 GAN 的目标函数构建,Sønderby 等
[38]
和
Kim 等
[39]
基于 Kullback-Leibler 散度对 GAN 进行建
模,通过最小化两者之间的交叉熵进行训练。文献[40]
对此进行拓展,提出的 f-GAN 将基于 Jensen-
Shannon 散度的 GAN 建模泛化为基于 f -散度的优化
目标,从而将 Kullback-Leibler 等经典散度度量也包
含在 f-散度中。
2.4 网络结构实现
在生成器 G 和判别器 D 的网络结构方面,朴
素生成式对抗网络
[22]
通过多层感知机(MLP, mul-
ti-layer perceptron)来实现。由于卷积神经网络
(CNN, convolutional neural network)较 MLP 有更
好的抽象能力,DCGAN
[28]
将朴素生成式对抗网络
的 MLP 结构替换为 CNN 结构,考虑到传统 CNN
所包含的池化层并不可微,DCGAN 用步进卷积网
络(strided convolution)及其转置结构分别实现判
图 1 GAN 示意
2018032-3
剩余13页未读,继续阅读

weixin_40673048
- 粉丝: 3
- 资源: 7
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 利用迪杰斯特拉算法的全国交通咨询系统设计与实现
- 全国交通咨询系统C++实现源码解析
- DFT与FFT应用:信号频谱分析实验
- MATLAB图论算法实现:最小费用最大流
- MATLAB常用命令完全指南
- 共创智慧灯杆数据运营公司——抢占5G市场
- 中山农情统计分析系统项目实施与管理策略
- XX省中小学智慧校园建设实施方案
- 中山农情统计分析系统项目实施方案
- MATLAB函数详解:从Text到Size的实用指南
- 考虑速度与加速度限制的工业机器人轨迹规划与实时补偿算法
- Matlab进行统计回归分析:从单因素到双因素方差分析
- 智慧灯杆数据运营公司策划书:抢占5G市场,打造智慧城市新载体
- Photoshop基础与色彩知识:信息时代的PS认证考试全攻略
- Photoshop技能测试:核心概念与操作
- Photoshop试题与答案详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


