
2017/10/8 Tensorflow下构建LSTM模型进行序列化标注-深语人工智能 DeepNLP
http://www.deepnlp.org/blog/tensorflow-lstm-pos/ 1/6
推荐文章
API 调 用 教 程
www.deepnlp.org
Tensorflow下构建LSTM模
型进行序列化标注
Tensorflow 并 行 : 多 核
(multicore) , 多 线 程
(multi-thread)
基 于 Seq2Seq+Attention
模型的Textsum文本自动摘
要
Tensorflow C++ API 调 用
预训练模型和生产环境编译
Tensorflow下构建LSTM模型进行序列化标注
1,October 15th
Github下载完整代码
简介
这篇文章中我们将基于Tensorflow的LSTM模型来实现序列化标注的任务,以NLP中的POS词性标注为例实现一个深度学习
的POS Tagger。文中具体介绍如何基于Tensorflow的LSTM cell单元来构建多层LSTM、双向Bi-LSTM模型,以及模型的训练和
预测过程。对LSTM模型的基本结构和算法不熟悉的可以参考拓展阅读里的一些资料。 完整版代码可以在Github上找
到:https://github.com/rockingdingo/deepnlp/tree/master/deepnlp/pos
数据和预处理
我们使用的词性标注POS的训练集来源是url [人民日报1998年的新闻语料],格式为”充满/v 希望/n 的/u 新/a 世纪/n
——/w 一九九八年/t”。具体的预处理过程包含以下步骤:
读取训练集数据:得到两个列表word和tag,其中word保存分词,Tag保存对应的标签;
构建词典:对词进行Count并且按照出现频率倒叙排列,建立字典表:word_to_id和tag_to_id 保存词和标签的id,未知词的标
签即为UNKNOWN = "*";
分别读取训练集train, dev和test数据集,将数据集的word列表和tag列表分别转化为其对应的id列表。
构建一个迭代器iterator, 每次返回读取batch_size个词和标签的Pair对 (x,y)作为LSTM模型的输入。 x代表词ID的矩阵,y代表标
签ID的矩阵,形状均为[batch_size, num_steps],代表batch_size组长度为num_steps的序列;矩阵中元素代表第x[i,j] 代表第i
个batch下第j个词的ID,如“132”(面条),y[i,j] 为其对应标签的ID,如”3 ”(NN-名词)。
模型
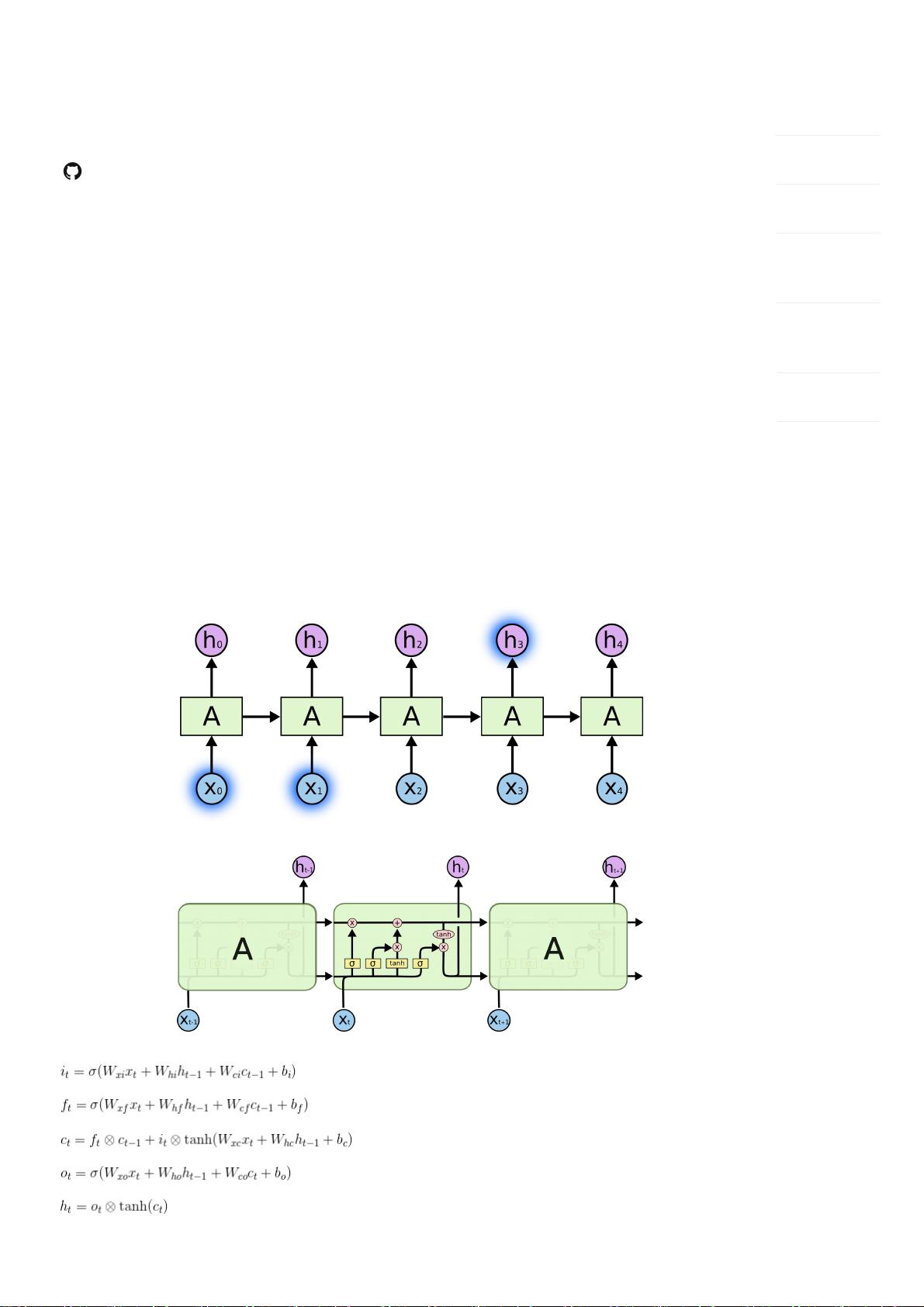
图1 LSTM链式展开
图2 LSTM内部结构 LSTM前向传播公式 input 门
forget 门
cell 状态更新
output 门
ht 隐藏层更新
实现
主页 在线演示 篇章分析 技术博客 API接口 文档 关于

spanel
- 粉丝: 5
- 资源: 14
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


