本文档是关于在Mac操作系统上安装Hadoop 1.2.1的详细步骤,适合初学者及对新版本Hadoop教程感到困惑的用户。文档中提到,由于Hadoop的新版本变动较大,相关教程可能已过时,因此选择较为稳定的1.2.1版本进行学习。
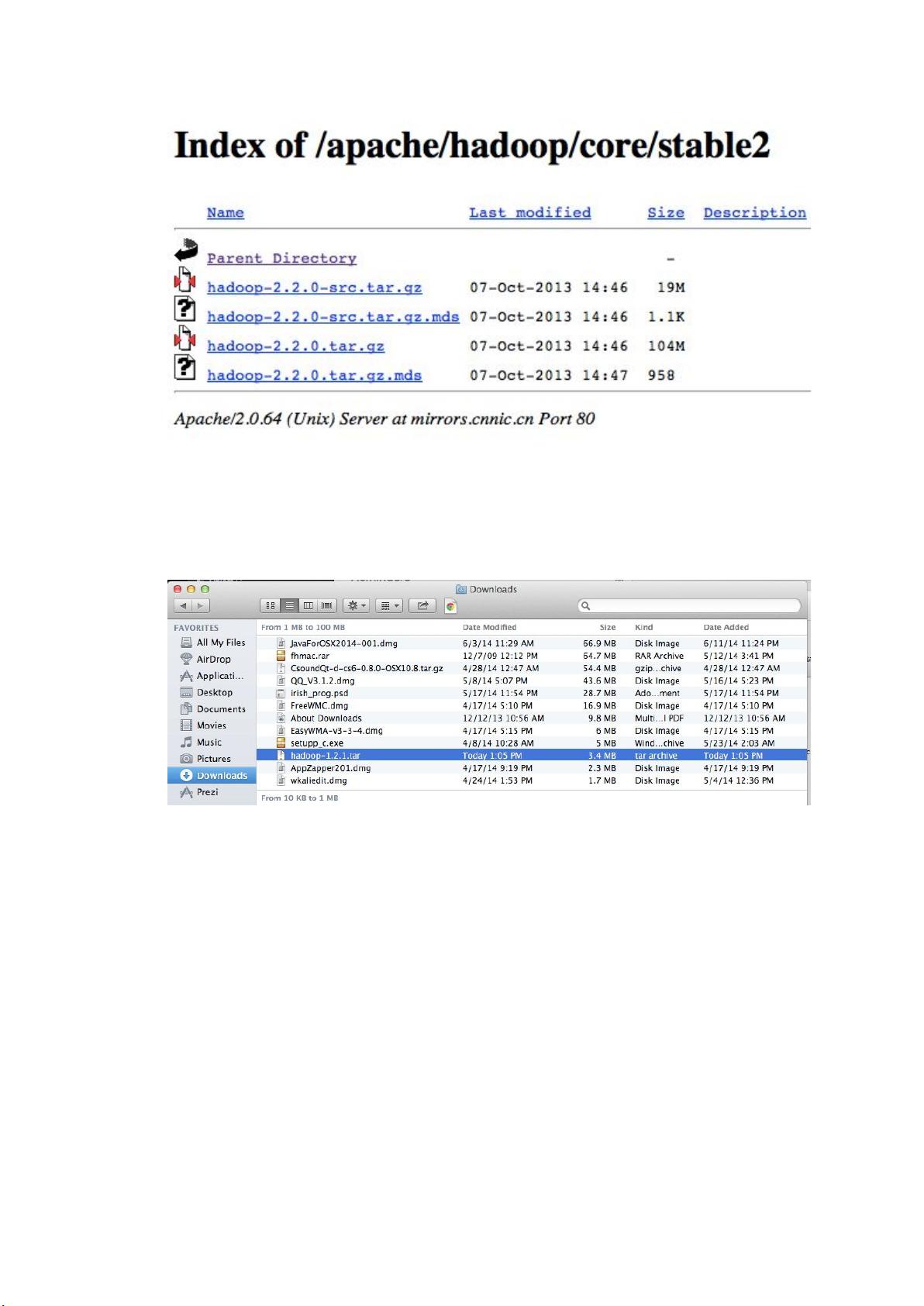
在开始安装之前,首先需要从Apache Hadoop的官方下载页面获取Hadoop的稳定版本。在本例中,推荐下载的是hadoop-1.2.1-bin.tar.gz,这是一个适用于各种系统的二进制压缩包,尤其适合非RPM或DEB包管理系统的平台,如Mac OS X。下载完成后,确保同时获取相应的mds(Message Digest Sync)文件,以验证下载的完整性。
安装Hadoop的伪分布式模式意味着在单个节点上模拟分布式环境,这对于学习和测试Hadoop的功能非常有用。以下是安装步骤:
1. 解压Hadoop: 将下载的tar.gz文件解压缩到你想要的目录,例如 `/usr/local/`,这将创建一个名为 `hadoop-1.2.1` 的目录。
2. 配置环境变量: 打开`~/.bash_profile`或`~/.zshrc`(取决于你的Shell),添加以下行来设置Hadoop的环境变量:
```
export HADOOP_HOME=/usr/local/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
```
然后运行 `source ~/.bash_profile` 或 `source ~/.zshrc` 来使更改生效。
3. 配置Hadoop: 在解压后的目录中,编辑 `etc/hadoop/core-site.xml` 和 `etc/hadoop/hdfs-site.xml` 文件。这两个文件定义了Hadoop集群的基本配置和HDFS(Hadoop Distributed File System)的设置。对于伪分布式安装,你需要在`hdfs-site.xml`中设置:
```xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
```
这将确保所有数据仅复制一次,因为在单机环境中不需要多副本。
4. 格式化HDFS: 使用以下命令初始化HDFS的名称节点:
```
hdfs namenode -format
```
5. 启动Hadoop服务: 运行以下命令启动DataNode和NameNode:
```
sbin/start-dfs.sh
```
6. 验证安装: 你可以通过检查Hadoop的Web界面来确认安装成功,NameNode的默认端口是50070。在浏览器中输入 `http://localhost:50070` 应该能看到Hadoop的监控界面。
7. 测试Hadoop: 创建一个测试文件并将其上传到HDFS,然后使用Hadoop的命令行工具读取它:
```
echo "Hello Hadoop" > test.txt
hadoop fs -put test.txt /user/your_username
hadoop fs -cat /user/your_username/test.txt
```
8. 关闭Hadoop服务: 当你完成测试或学习后,使用以下命令停止所有Hadoop进程:
```
sbin/stop-dfs.sh
```
在Mac上安装Hadoop可能会遇到一些与Unix/Linux系统不同的问题,如权限、依赖库或Java版本等。确保你的系统已经安装了Java 6或更高版本,因为Hadoop 1.2.1可能不支持更新的Java版本。如果遇到问题,查阅官方文档、社区论坛或在线教程可以帮助解决问题。在进一步探索Hadoop生态系统时,理解MapReduce、YARN和HBase等组件的工作原理也是十分重要的。


 我的内容管理
收起
我的内容管理
收起
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助 






