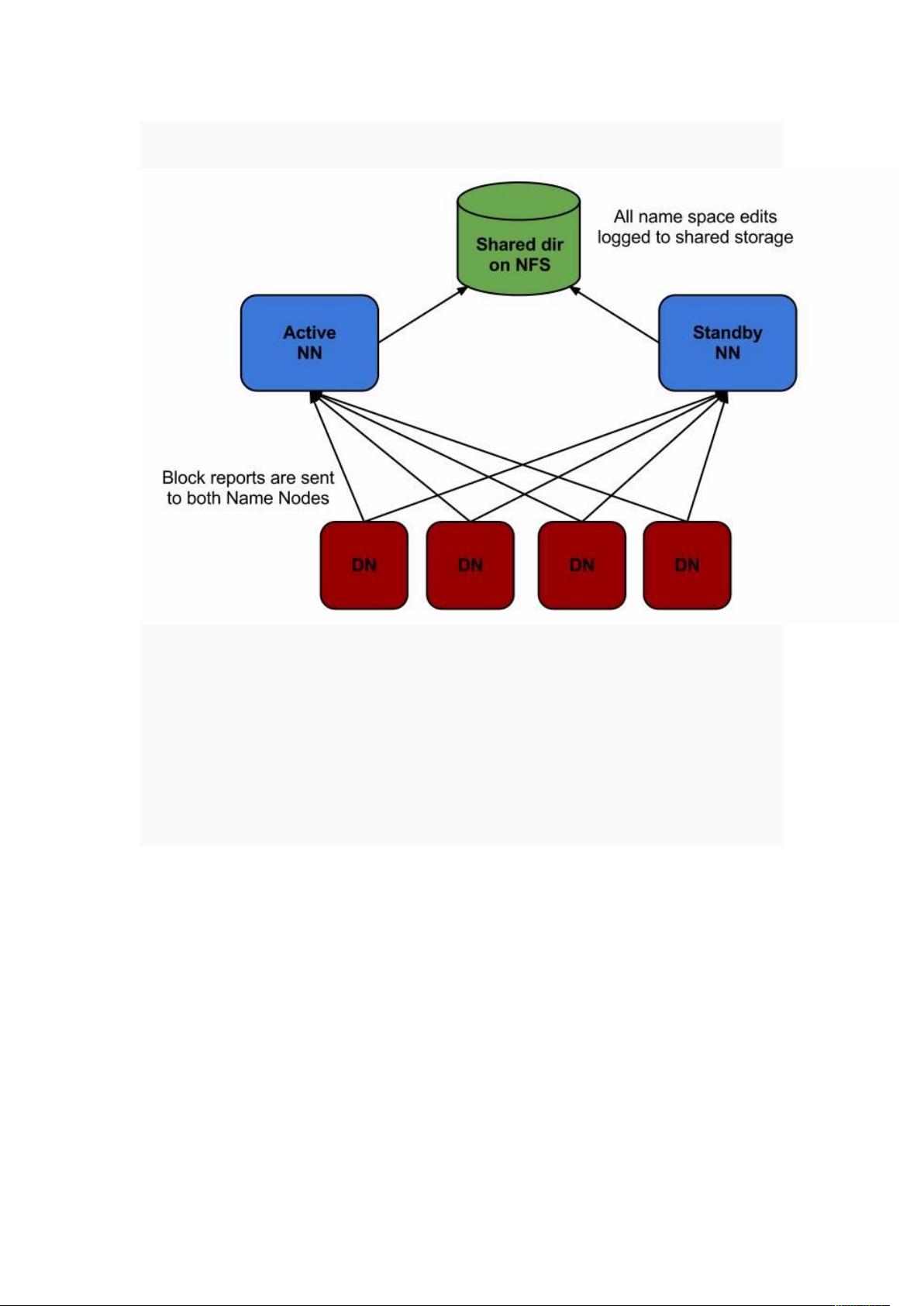
"Hadoop HA 高可用性部署" Hadoop HA(高可用性)部署旨在解决Hadoop 1.0架构中的单点故障问题,即当NameNode或JobTracker停机时,整个集群会瘫痪,这对7×24小时运行的生产环境构成极大风险。为了解决这个问题,Hadoop引入了多种高可用性策略。 ### 第一部分:Hadoop 1.0的问题 在Hadoop 1.0中,NameNode是集群的关键组件,它负责元数据管理和集群的状态。如果NameNode发生故障,整个系统无法运行。同样,JobTracker的失效也会导致任务调度和集群资源管理中断。 ### 第二部分:常见HA方案 #### 1. NFS共享目录方案 一种解决方案是通过NFS(网络文件系统)共享目录,存储实时的fsimage(文件系统镜像)和editlog(元数据修改日志)。在NameNode故障后,可以通过这些备份文件恢复服务,但这种方法需要时间进行数据同步,无法快速切换。 #### 2. Secondary NameNode Secondary NameNode用于定期合并fsimage和editlog,以减轻NameNode的压力。但在故障发生时,它并不能立即接管服务,因为它不是真正的热备份。 #### 3. Facebook的AvatarNode方案 Facebook提出了AvatarNode,它包含两个角色:Primary Avatar和Standby Avatar。通过虚拟IP,两台AvatarNode可以互相切换。Primary Avatar提供服务,而Standby Avatar通过NFS目录获取并同步数据,始终保持在安全模式,以便随时接管。 ### 第三部分:Hadoop 0.23的HA解决方案 Hadoop 0.23引入了双机热备机制,有Active和Standby两个NameNode节点。仅Active节点对外提供服务,元数据存储在共享存储中。Standby节点持续同步共享存储中的元数据,确保切换时不会丢失数据。DataNode同时向两个NameNode报告状态,同时还需要Secondary NameNode处理editlog过大的问题。 ### Hadoop的HA集群配置与管理 配置HDFS HA集群涉及以下几个关键步骤: 1. **设置两个NameNode**:一个作为Active,一个作为Standby。 2. **共享存储**:元数据存储在可访问的共享存储中。 3. **心跳检测**:确保Active节点的健康状态,并在故障时自动切换。 4. **Zookeeper**:用于协调和决策NameNode的切换。 5. **客户端配置**:客户端需配置为使用Zookeeper Failover Controller (ZKFC),以在NameNode切换时自动调整连接。 在实际操作中,还需要考虑监控、故障检测、数据一致性保证以及性能优化等问题。Hadoop HA的实现提供了对生产环境的保护,降低了由于单点故障导致的系统中断风险。 请注意,以上内容是基于Hadoop 0.23版本的描述,随着Hadoop版本的更新,其HA机制也有所改进和完善。最新的Hadoop发行版可能包含更多的优化和增强功能。建议参考最新的官方文档以获取最准确的信息。
剩余14页未读,继续阅读