

DRAFT
Speech and Language Processing: An introduction to natural language processing,
computational linguistics, and speech recognition. Daniel Jurafsky & James H. Martin.
Copyright
c
2006, All rights reserved. Draft of February 21, 2007. Do not cite
without permission.
6
HIDDEN MARKOV AND
MAXIMUM ENTROPY
MODELS
Numquam ponenda est pluralitas sine necessitat
‘Plurality should never be proposed unless needed’
William of Occam
Tatyana was her name... I own it,
self-willed it may be just the same;
but it’s the first time you’ll have known it,
a novel graced with such a name
Pushkin, Eugene Onegin
In this chapter we introduce two important classes of statistical models for pro-
cessing text and speech, the Hidden Markov Model (HMM) and the Maximum En-
tropy model (MaxEnt), particularly a variant of MaxEnt called the Maximum En-
tropy Markov Model (MEMM). All of these are machine learning models. We have
already touched on some aspects of machine learning; indeed we briefly introduced the
Hidden Markov Model in the previous chapter, and we have introduced the N-gram
model in the chapter before. In this chapter we give a more complete and formal intro-
duction to these two important models.
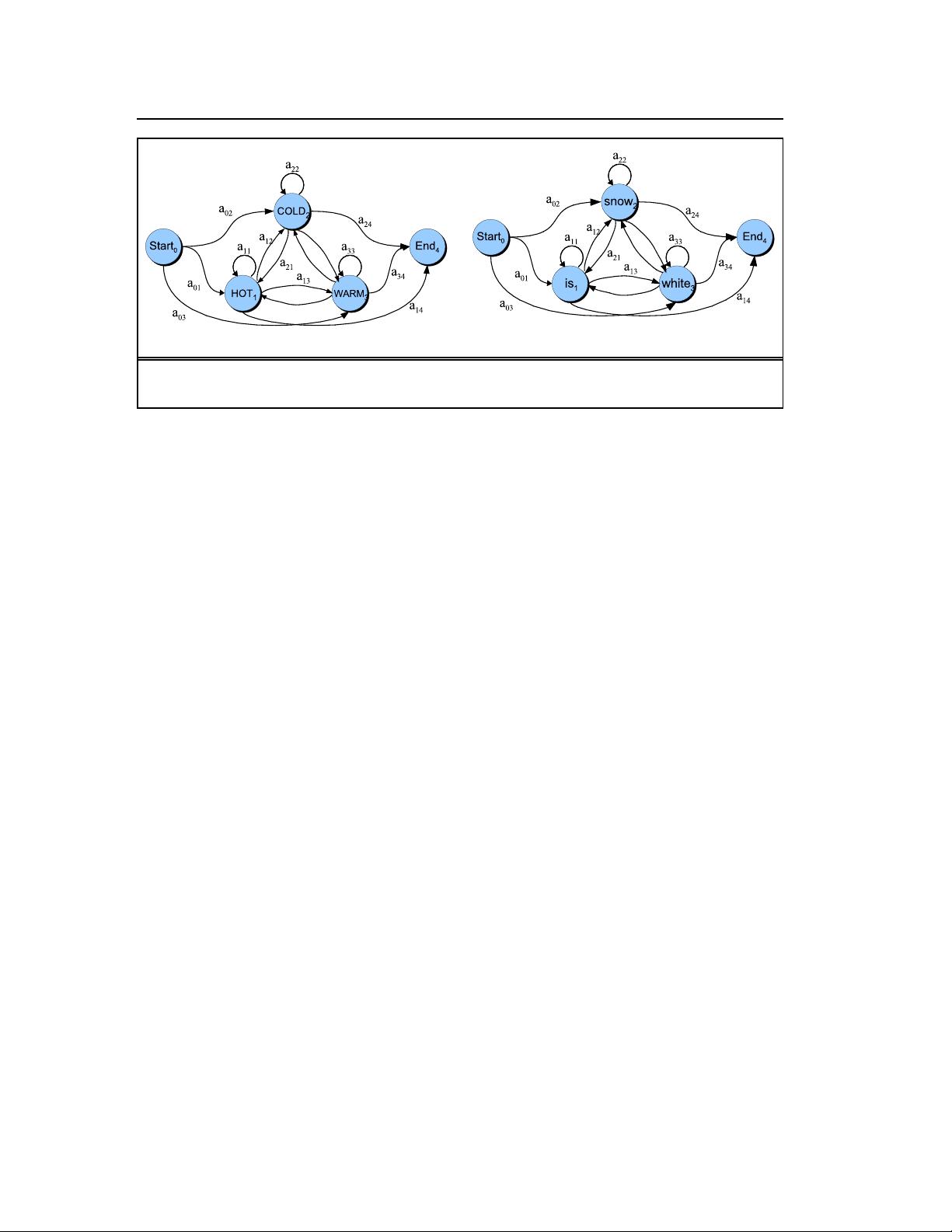
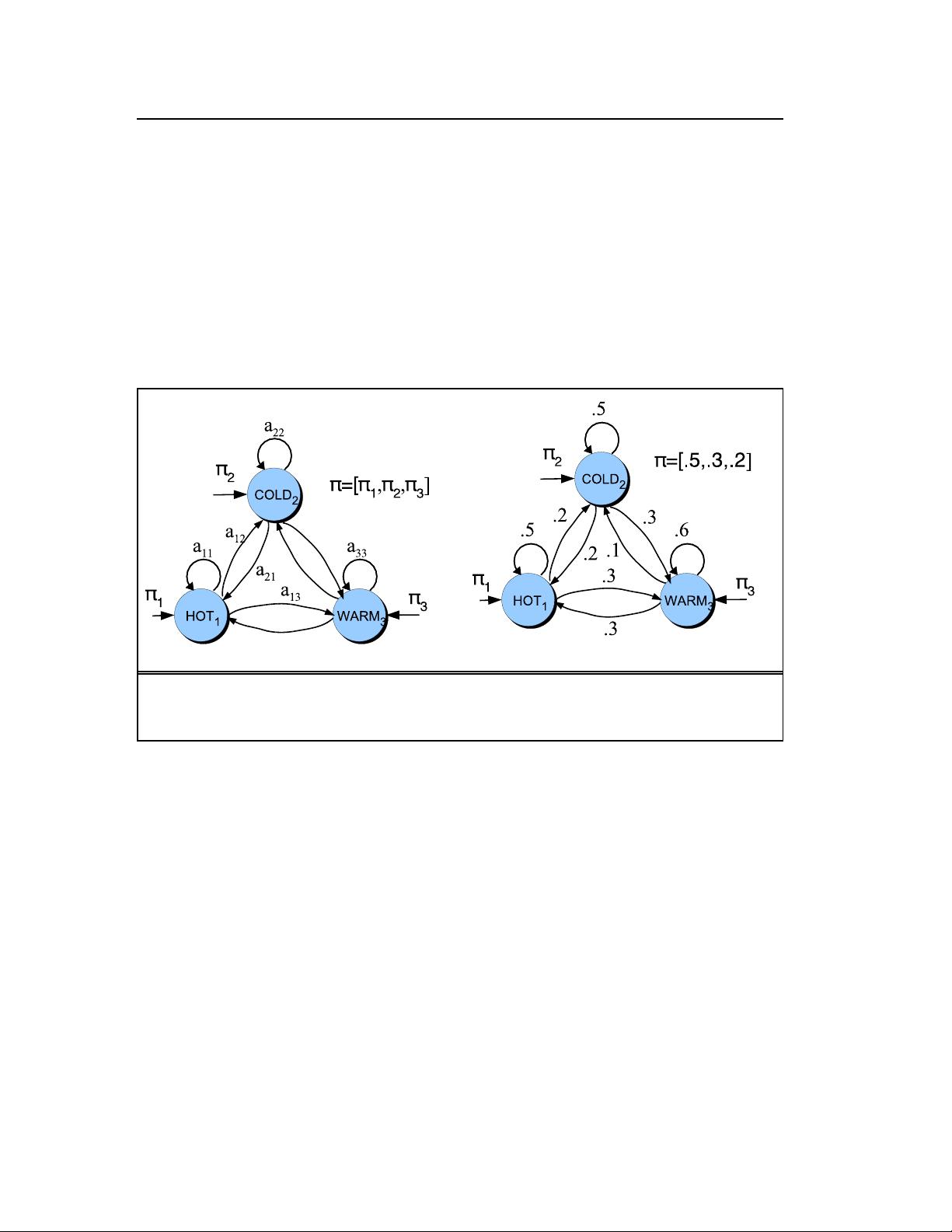
HMMs and MEMMs are both sequence classifiers. A sequence classifier or
SEQUENCE
CLASSIFIERS
sequence labeler is a model whose job is to assign some label or class to each unit in a
sequence. The finite-state transducer we studied in Ch. 3 is a kind of non-probabilistic
sequence classifier, for example transducing from sequences of words to sequences of
morphemes. The HMM and MEMM extend this notion by being probabilistic sequence
classifiers; given a sequence of units (words, letters, morphemes, sentences, whatever)
their job is to compute a probability distribution over possible labels and choose the
best label sequence.
We have already seen one important sequence classification task: part-of-speech
tagging, where each word in a sequence has to be assigned a part-of-speech tag. Sequence-
labeling tasks come up throughout speech and language processing, a fact that isn’t too
surprising if we consider that language consists of sequences at many representational


剩余41页未读,继续阅读















