C++实现堆栈算法:LIFO数据结构详解及应用示例
需积分: 0 39 浏览量
更新于2024-07-27
1
收藏 805KB PDF 举报
堆栈算法描述与C++实现
堆栈和队列是基础的数据结构,它们源于线性表,但各自有特定的操作限制。堆栈遵循“后进先出”(LIFO)原则,允许只在一端进行插入(添加)和删除操作。这种特性使得堆栈在编程中广泛应用,如表达式匹配、汉诺塔问题、火车车厢调度、电子布线分析、离线等价类问题和迷宫路径寻找等。
在C++中,堆栈可以通过两种方式实现:一是基于数组的公式描述,二是基于链表的结构。直接定义堆栈类,而非从其他类派生,可以提高执行效率,因为这样避免了额外的派生开销。例如,可以创建一个名为Stack的类,其包含基本的push(添加元素)、pop(移除顶部元素)、top(查看顶部元素)和empty(检查是否为空)方法。
C++中的抽象数据类型(Abstract Data Type, ADT)在堆栈的实现中起着关键作用。ADT描述了一组操作和这些操作的接口,而不关心其实现细节。对于堆栈,ADT包括像stack.push(e)(将元素e添加到顶部)、stack.pop()(移除并返回顶部元素)这样的操作。
图5-1展示了堆栈的基本概念,其中栈顶(top)是元素的最新添加位置,栈底(bottom)则是最早添加的位置。当添加元素E时,它会替换当前栈顶D,形成一个新的堆栈状态,如图5-1b所示。
C++的新特性如派生类和继承在这部分也有所体现。通过派生,我们可以创建一个继承自LinearList或Chain的堆栈类,这有助于简化代码,但可能牺牲一部分执行效率。在实际编程中,开发者需要根据具体需求权衡性能和代码组织的便利性。
学习堆栈算法描述和C++实现有助于理解如何在软件开发中有效地管理数据流和处理问题,特别是涉及到递归和层次结构的问题。掌握这些基础知识对于提高编程技能和设计高效算法至关重要。
克服这种缺陷的一种方法是在创建堆栈时取 M a x To p = 0。如果在 A d d 操作期间没有可用的空间
来容纳新的元素,可将M a x To p变成2 * M a x To p + 1,然后分配一个新的大小为M a x To p + 1的数组,
并将原数组中的元素复制到新数组中,最后删除原数组。类似地,在删除操作期间,如果表的
大小变成数组容量的 1 / 4 ,则可以分配一个容量为原数组一半的新数组,并将原数组中的元素
复制到新数组中,最后删除原数组。
1) 采用上述思想重新实现自定义S t a c k 。构造函数不带参数,其任务是置 M a x To p = 0,分配
一个容量为1的数组,并置t o p为-1。
2) 考察从一个空堆栈开始,连续执行n 个添加和删除操作。假定采用原来的方法时总的执
行步数为f (n)。证明对于新的方法,执行步数最多为 cf (n),其中c 为常量。
5.4 链表描述
虽然上一节给出的用数组实现堆栈的方法既优雅又高效,但若同时使用多个堆栈,这种方
法将浪费大量的空间。其原因与3 . 3 . 4节所分析的线性表(用单个数组实现)空间利用率不高的
原因相同。不过,若仅同时使用两个堆栈,则是一种例外。可以让一个堆栈从数组的起始位置
向后延伸,而让另一个堆栈从数组的结束位置( M a x S i z e - 1 )向前延伸,这样可以保持空间的
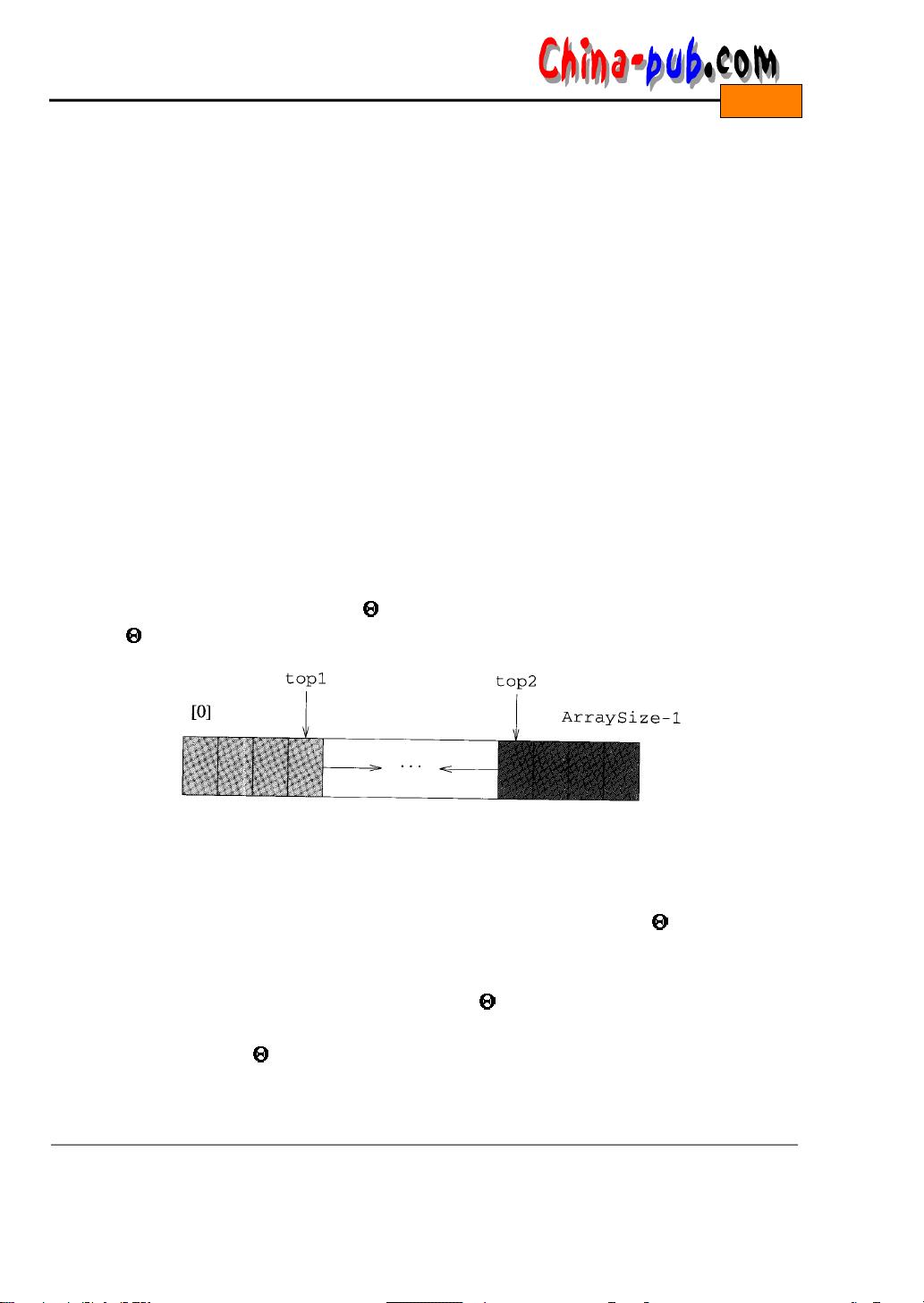
利用率和运行效率。两个堆栈都向数组的中部延伸(如图5 - 2所示)。在描述两个以上的堆栈时,
可以借鉴在一个数组中描述多个线性表的方法。不过,这样做在提高空间利用率的同时,却使
A d d 操作在最坏情况下的时间复杂性从 ( 1 ) 变成了O ( A r r a y S i z e )。D e l e t e操作的时间复杂性仍
然保持为 ( 1 )。
图5-2 一个数组中的两个堆栈
可以采用一个堆栈对应一个链表的方法来高效地描述多个堆栈。这种描述方法使每个堆栈
元素多用了一个额外的指针空间。不过,每个堆栈操作的时间复杂性均变为 ( 1 )。
在使用链表来表示堆栈时,必须确定链表的哪一端对应于栈顶。如果把链表的右端作为栈
顶,那么可以利用链表操作 I n s e r t ( n , x ) 和D e l e t e ( n , x ) 来实现堆栈的插入和删除操作,其中 n为链
表中的节点数目。这两种链表操作的时间复杂性均为 ( n ) 。另一方面,如果把链表的左端作
为栈顶,则可以利用链表操作I n s e r t ( 0 , x )和D e l e t e ( 1 , x )来实现堆栈的插入和删除操作。这两种链
表操作的时间复杂性均为 ( 1 )。以上分析表明,应该把链表的左端作为栈顶。
程序5 - 3给出了从C h a i n类派生而来的链表形式的堆栈。链表的左端为栈顶,右端为栈底。
程序5-3 从C h a i n 派生的链表形式的堆栈
template<class T>
class LinkedStack : private Chain<T> {
p u b l i c :
1 6 6 第二部分 数 据 结 构
下载
堆栈1 堆栈2
剩余27页未读,继续阅读
2012-05-03 上传
213 浏览量
2013-06-12 上传
2012-03-27 上传
2012-11-17 上传
点击了解资源详情
2009-05-29 上传
2012-12-09 上传
2022-06-22 上传









