微软语音AI技术演进与实战解析
需积分: 14 27 浏览量
更新于2024-07-16
收藏 3.42MB PDF 举报
"这份文件是赵晟在2018年4月18日AI开发者万人大会第一场前瞻峰会上的演讲PPT,主题聚焦微软的语音AI技术进展与实践,由微软(亚洲)互联网工程院的专家分享,主要涵盖了微软在语音识别、语音合成服务及其解决方案上的突破和发展。"
微软作为全球领先的科技公司,其在语音AI领域的研究和开发具有重要意义。在2016年至2018年间,微软在语音识别技术上取得了显著进步,其在Switchboard会话数据集上的识别率达到了94.9%,并在中英机器翻译方面也表现出色,达到98.6%的准确度。这些技术的提升对于语音交互的自然性和准确性至关重要。
语音合成服务是微软认知服务的重要组成部分,经历了多个发展阶段。从早期的Articulatory Synthesis、DecTalk到后来的HMM synthesis,再到基于深度学习的Neural TTS,自然度显著提升。微软在业界率先将接近人声的Neural TTS技术产品化,如Microsoft Anna和Microsoft Zira,提供更流畅、自然的语音体验。Neural TTS模型通过简化流程、使用高质量的神经网络Vocoder和基于注意力的声学模型,减少了人工特征的依赖,让系统能自我学习并生成更为真实的语音。
Tacotron和Transformer TTS是微软在这一领域的重要贡献。Tacotron是一种端到端的语音合成系统,它简化了传统合成过程,但需要大量计算资源。而Transformer TTS的出现,主要是为了克服基于循环神经网络(RNN)的TTS在处理长依赖性时的不足,Transformer架构在自然语言处理任务中展现出的强大性能,使得它在语音合成中也能有效提高效率和模型质量。
此外,FastSpeech是另一个值得一提的模型,它在NIPS 2019上提出,旨在解决TTS的速度问题,提供更快的推理速度,同时保持高质量的语音输出。其他如WaveNet、Parallel Wavenet、WaveRNN等也是近年来在语音生成领域的重要技术,它们通过不同的方式优化了声音合成的效率和质量。
这份PPT揭示了微软在语音AI领域的深厚积累和技术前沿,展示了微软如何通过不断的技术创新,推动语音识别和合成服务的进步,为AI开发者和行业应用提供了强大的工具和解决方案。
Transformer TTS - Results
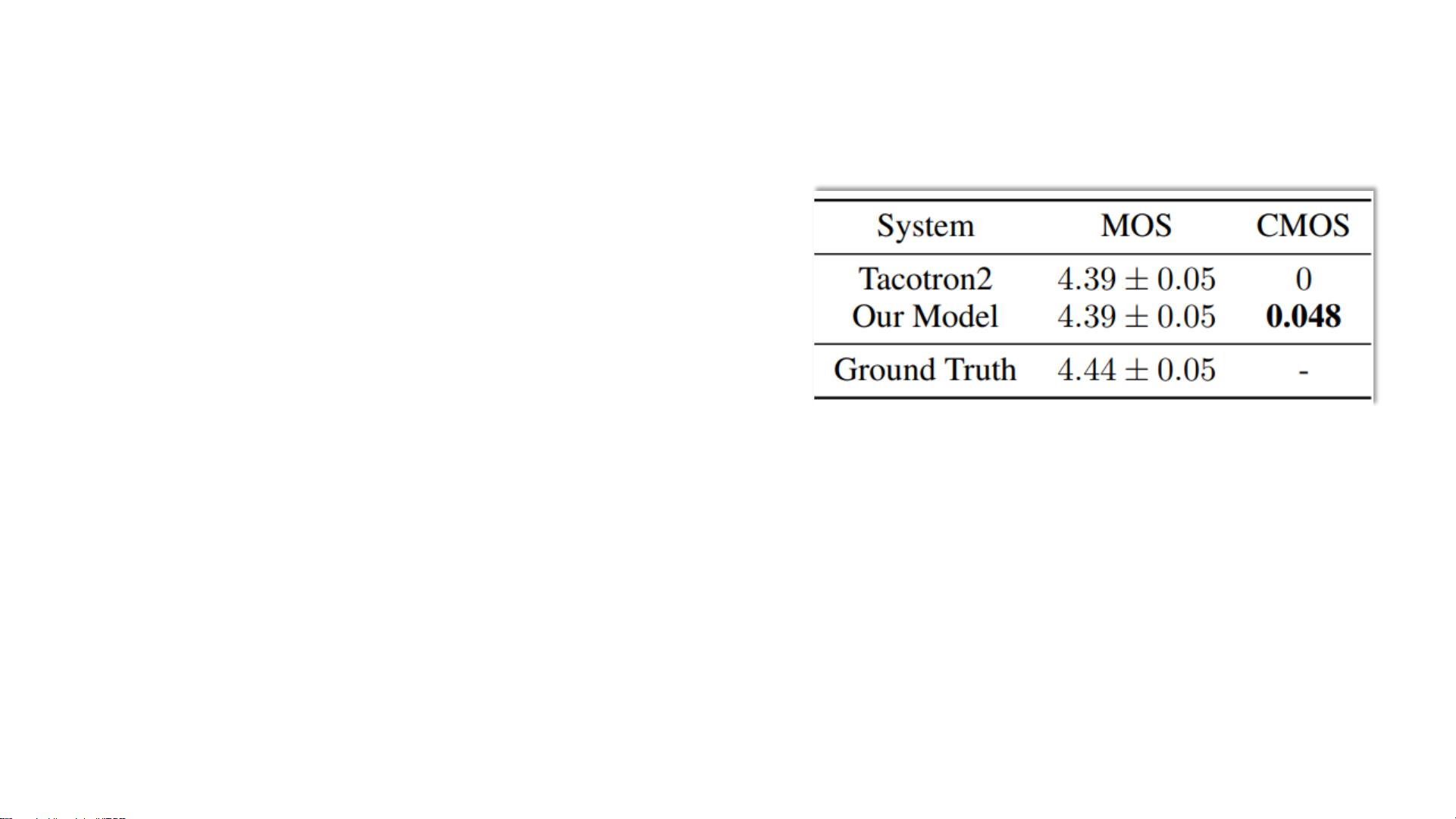
• 结果
• 实现与Tacotron2同等质量
• 训练速度约为3倍
• 问题
• Transformer TTS仍然可以有像Tacotron一样
的坏输出
• 重复/跳过单词
• 不能停止的情况
• 不稳定的根本原因
Unconstrained Encoder-decoder Attention
Imprecise Stop Prediction
Unseen context
CMOS
CMOS: comparison mean option score. Testers listen to two audios
each time and evaluates how the latter feels comparing to the
former using a score in [−3, 3] with intervals of 1
Baseline model: Tacotron2
• Use phone sequence as inputs
• Other structure are same as Google’s version
CSDN
剩余34页未读,继续阅读
2024-11-23 上传
2024-11-23 上传
2024-11-23 上传
2024-11-23 上传
2024-11-23 上传
2024-11-23 上传

诺亚方包
- 粉丝: 782
- 资源: 256
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
