Spark编程题解析:RDD特性与操作实战
需积分: 45 88 浏览量
更新于2024-08-05
1
收藏 2.58MB PDF 举报
"Spark编程题笔记,主要涵盖RDD的基本概念、获取数据的方式以及RDD的操作"
在Spark编程中,RDD(Resilient Distributed Dataset)是核心数据结构,它提供了一种高度容错、并行处理数据的方式。RDD具有五个关键特性:
1. 分区列表:每个RDD由多个分区组成,这些分区分布在集群的不同节点上,分区数量决定了并行计算的程度。如果从集合创建RDD,其默认分区数等于程序分配到的CPU核心数;若从HDFS文件创建,则默认为文件的Block数量。
2. 计算函数:每个分区都有相应的计算逻辑,使得数据处理可以在分布式环境中执行。
3. 依赖关系:RDD通过转换操作(transformations)产生新的RDD,新RDD依赖于之前的RDD,形成计算依赖链。
4. Partitioner:仅对于(Key, Value)类型的RDD,存在Partitioner,用于控制数据的分布,优化数据局部性。非Key-Value RDD的Partitioner为None。
5. 优先位置列表:遵循“移动数据不如移动计算”的原则,Spark尽可能在数据所在节点上执行计算,以减少网络传输。
获取RDD数据通常有以下方式:
1. 从集合创建:使用`sc.parallelize`或`sc.makeRDD`,可以指定分区数。
2. 从文件读取:`sc.textFile`用于读取文本文件,`sc.wholeTextFiles`则用于读取整个文件内容,两者均可指定分区数。
例如,从本地目录"D:/datas"读取所有文件到RDD并打印:
```scala
val rdd = sc.textFile("file:///D:/datas/*")
rdd.foreach(println)
```
了解RDD的分区数,可以使用`getNumPartitions`或`partitions.length`方法:
```scala
val numPartitions = rdd.getNumPartitions // 或 rdd.partitions.length
```
RDD的主要操作分为两类:
1. 转换操作(Transformations):如`map`、`flatMap`等,返回新的RDD但不会立即执行,直到遇到行动操作。例如:
- `map`函数用于对每个元素应用函数,如将每个单词转化为`(单词, 1)`的元组。
- `flatMap`类似,但会将结果扁平化,例如将字符串数组中的每个单词拆分成单个字符。
2. 行动操作(Actions):如`count`、`first`、`collect`、`take`等,它们会触发实际的计算并可能返回结果。例如,计算RDD元素总数或取出前n个元素。
在实践中,合理使用RDD的各种操作,结合Spark的分布式计算能力,可以高效地处理大规模数据。
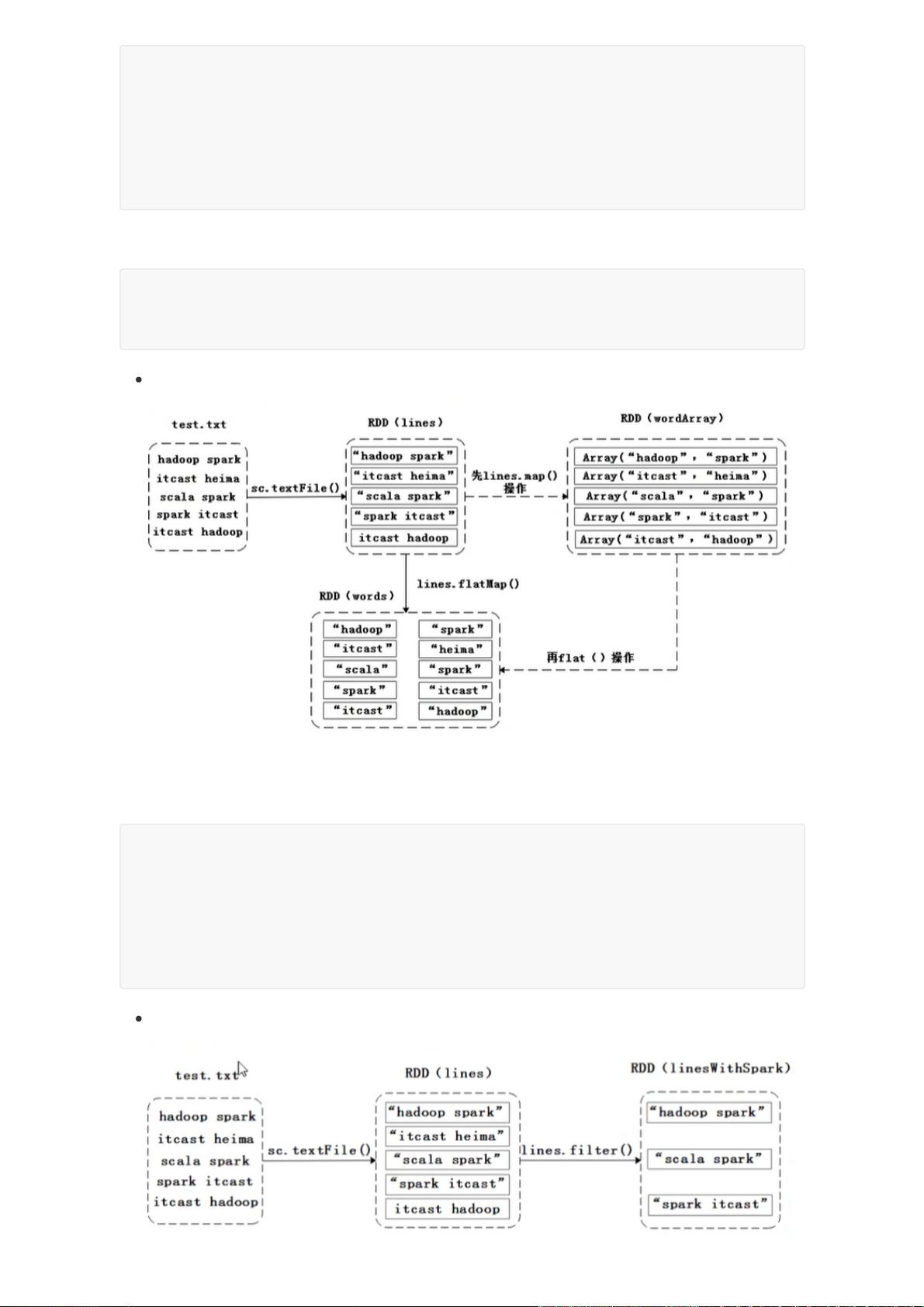
例:截取每个单词的前2个字符
flatMap:对每个元素进行操作后,扁平化集合
语法:rddobj.flatMap(a=>对a操作 )
例:将数组中单词分割,并扁平化为一维
filter:筛选出符合条件的元素
val
arr=Array("hello","java","scala","scala","python","hello","java","python","pycha
rm")
val rddObj: RDD[String] = sc.parallelize(arr)
rddObj.map(a=>(a,1)).foreach(println)
// 简化参数名
rddObj.map((_,1)).foreach(println)
rddObj.map(a=>a.substring(0,2)).foreach(println)
// 简化参数名
rddObj.map(_.substring(0,2)).foreach(println)
var arr=Array("hello java scala","scala python hello java","python hello scala
demo","demo hello java")
val rddObj: RDD[String] = sc.parallelize(arr)
rddObj.flatMap(a => a.split(" ")).foreach(println)
// 简化参数名
rddObj.flatMap(_.split(" ")).foreach(println)
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-18 上传
2021-05-18 上传
2021-05-18 上传
2022-04-29 上传
2018-12-31 上传
2020-08-05 上传

霸敛
- 粉丝: 257
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
