C语言研讨会:键盘缓冲区、延时与程序控制
需积分: 0 176 浏览量
更新于2024-06-30
收藏 318KB DOCX 举报
"C语言研究七、八研讨会报告"
在本次C语言的研究研讨会中,讨论了多个关键主题,涉及程序控制结构、系统级编程以及单片机延时处理等多个方面。以下是对这些知识点的详细说明:
1. **循环中的break与return**:
- `return`语句用于立即结束整个函数的执行,并返回一个指定的值(在无返回值函数中,仅表示结束)。在嵌套循环中,`return`会跳出整个函数,而不仅仅是当前的循环。
- `break`语句用于退出最内层的循环,不会结束整个函数,而是继续执行循环之后的代码。
- `continue`语句则用于跳过当前循环体的剩余部分,直接进入下一次迭代。
- 比较它们的影响范围,可以认为`continue` < `break` < `return`,而`exit()`(稍后讨论)具有更大的影响力。
2. **exit()函数**:
- `exit()`函数是C标准库中的一个函数,用于终止整个程序的执行。与`return`不同,`exit()`不仅结束当前函数,还会清理全局变量和栈空间,并返回一个状态码给操作系统。状态码通常用于表示程序的退出状态,例如错误代码。
- 在比较`return`和`exit()`时,`exit()`具有更广泛的影响力,因为它可以结束整个程序,而`return`仅限于函数级别。
3. **键盘缓冲区处理**:
- 当用户按下键盘上的键时,字符会被存储在键盘缓冲区中。在编写程序时,如果不处理缓冲区,可能会导致输入的延迟或意外的行为。通常需要通过读取缓冲区来确保及时处理用户的输入。
4. **延时及时响应问题**:
- 使用`for`循环实现延时可能导致CPU资源浪费,因为循环会一直占用处理器,无法处理其他任务。解决方法包括:
- 重写中断服务程序,使得中断可以被及时响应,从而提高系统的实时性。
- 采用非阻塞的延时函数,让系统在等待期间能够检查其他条件,但这种方法可能不保证精确的延时。
- 多进程处理,但51单片机由于资源限制可能难以实现。
5. **内联汇编的优势与应用**:
- 内联汇编允许在C/C++代码中插入汇编指令,提供更高的性能和硬件控制。它可以用于优化关键代码段,访问特定硬件寄存器,或者执行某些C/C++不支持的操作。
- 但是,过度使用内联汇编可能导致代码可读性和可维护性降低,且编译器可能无法有效优化。
6. **extern与static**:
- `extern`关键字用于声明一个外部变量或函数,表明它在其他源文件中定义。这允许在多个文件间共享变量或函数。
- `static`关键字用于变量声明时,表示变量是局部的,其作用域限制在当前文件或函数内。对于函数,静态修饰符意味着函数仅在当前编译单元可见,提供了封装。
7. **不通过内联汇编实现功能**:
- 虽然内联汇编可以提供一些优势,但在某些情况下,可以利用C/C++的高级特性如指针、结构体、位运算等来实现类似的功能,以保持代码的可读性和平台独立性。
通过理解和掌握这些知识点,开发者可以更好地控制程序流程,优化系统响应,以及处理底层硬件交互,从而提升软件的质量和效率。在实际编程中,需根据具体需求和环境灵活运用这些技巧。
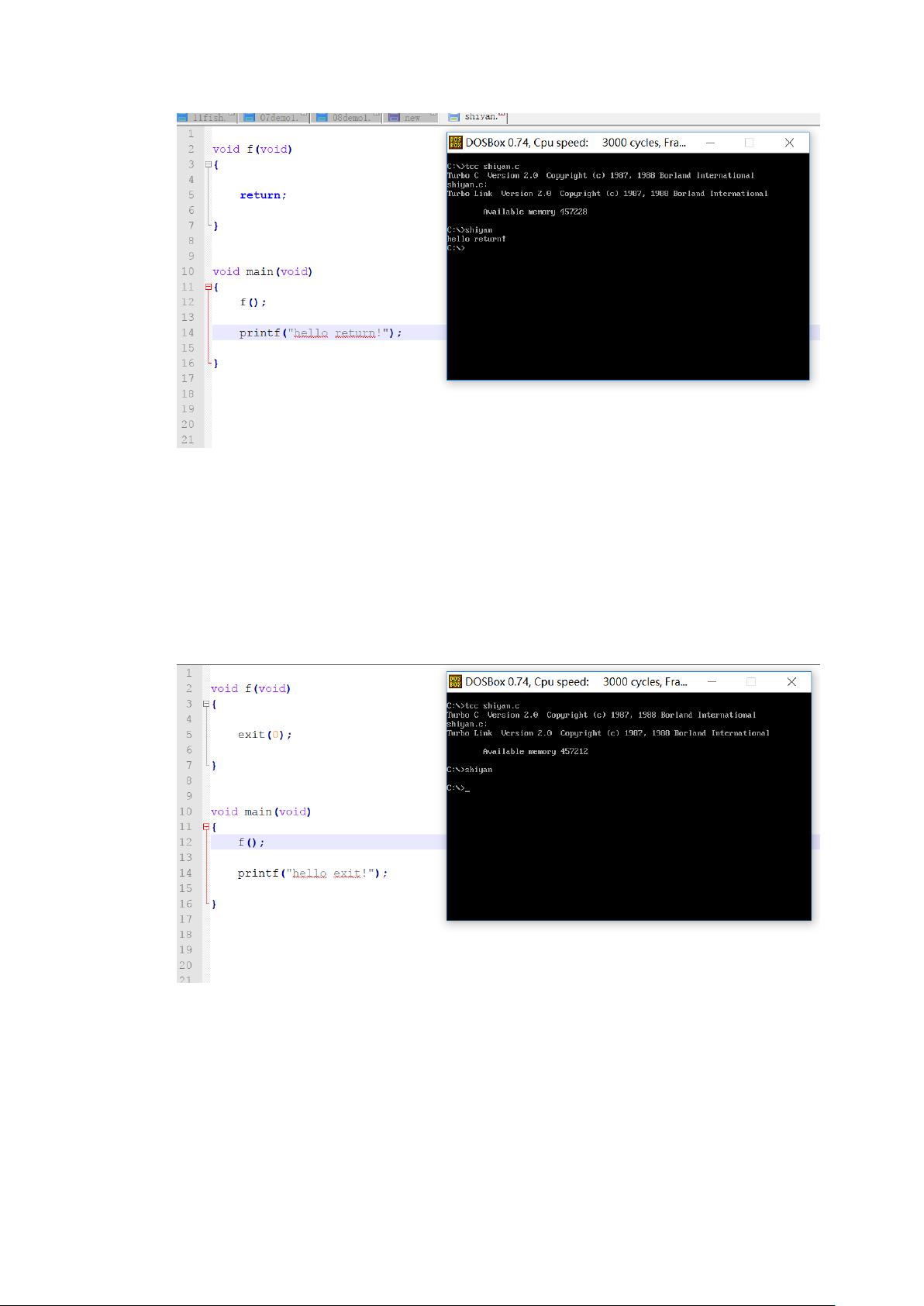
在一个 f()中使用 exit:
哦呦,本来以为 return 这个“转世神童”就够厉害了,没想到啊没想到,exit
(0)竟然拥有毁灭世界的力量,行吧行吧,厉害死你们了。
剩余16页未读,继续阅读
2022-08-08 上传
2024-09-06 上传
2024-09-06 上传

LauraKuang
- 粉丝: 22
- 资源: 334
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
