使用Keras处理Quora问题对:特征选择与加权损失函数
需积分: 0 142 浏览量
更新于2024-08-05
收藏 1.2MB PDF 举报
"16337341朱志儒"
本文主要介绍了一位名为朱志儒的IT从业者的工作,他使用Windows 10 64位操作系统,配备Intel Core i5-6300HQ处理器,8GB内存以及NVIDIA GeForce GTX 950M显卡。他在Python环境中进行开发,利用了多个库,包括pandas 0.24.2、numpy 1.16.4、gensim 3.7.3、Keras 2.2.4、sklearn 0.21.2、nltk 3.4.3以及matplotlib 3.0.2,这些库广泛应用于数据处理、自然语言处理(NLP)和机器学习领域。
朱志儒的工作内容涉及了一个Quora问题相似性判断的项目。Quora训练集包含大约40万个可能相似的问题对,每个问题对由四个部分组成:问题对ID(qid1和qid2)、问题内容(question1和question2)以及一个标识符(is_duplicate),用于标记问题是否重复。在分析数据时,他发现训练集中的正样本(表示问题重复的样本)占比为0.3692,而基于这个比例在测试集上预测的logloss为0.55,但训练集的logloss为0.6585,这表明训练集和测试集的数据分布存在差异。
为了解决这个问题,朱志儒采用了Keras的`class_weight`参数,在模型训练过程中动态调整损失函数,使得模型能够更均衡地对待不同类别的样本。在特征工程阶段,他删除了停用词,并统计了训练集和测试集中问题对的单词数量,以便于进一步分析和处理文本数据。具体代码如下:
```python
train_sentences = pd.Series(train_set['question1'].tolist() + train_set['question2'].tolist()).astype(str)
test_sentences = pd.Series(test_set['question1'].tolist() + test_set['question2'].tolist()).astype(str)
train_lens = train_sentences.apply(lambda x: len([i for i in x.split() if i not in stop]))
test_lens = test_sentences.apply(lambda x: len([i for i in x.split() if i not in stop]))
print("训练集平均值:", np.mean(train_lens))
print("测试集平均值:", np.mean(test_lens))
```
这段代码首先将问题1和问题2的文本合并成一个序列,并将它们转换为字符串类型。然后,通过`apply()`函数对每个问题进行处理,计算去除停用词后的单词数量。最后,计算训练集和测试集中问题对的平均单词数,以了解文本的长度分布情况,这对于文本相似性计算至关重要。
通过这样的方法,朱志儒能够更好地理解和调整模型,以适应数据集的特性,从而提高模型在测试集上的性能。他的工作展示了在处理不平衡数据集时如何运用机器学习策略,以及如何利用Python和相关库进行有效的NLP任务处理。
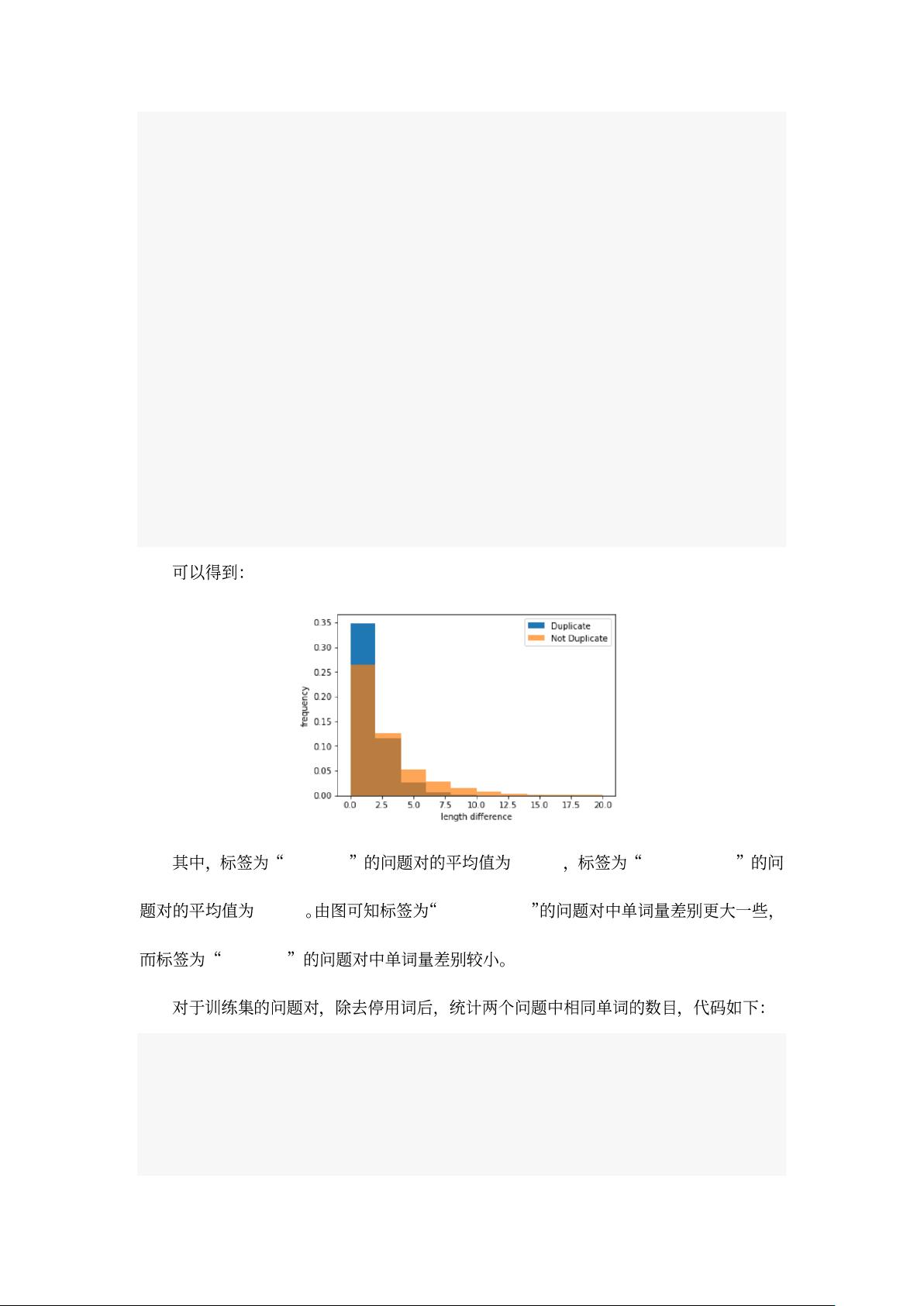
question2.append(word)
return abs(len(question1) - len(question2))
train_length_difference = train_set.apply(length_difference, axis=1,
raw=True)
print("Duplicate 平均值:", np.mean(train_length_difference[train_set
['is_duplicate'] == 1]))
print("Not Duplicate 平均值:", np.mean(train_length_difference[train_set
['is_duplicate'] == 0]))
plot.hist(train_length_difference[train_set['is_duplicate'] == 1],
range=[0, 20], normed=True, label='Duplicate')
plot.hist(train_length_difference[train_set['is_duplicate'] == 0],
range=[0, 20], normed=True, alpha=0.7, label='Not Duplicate')
plot.xlabel("length difference")
plot.ylabel("frequency")
plot.legend()
def find_same(row):
question1 = []
question2 = []
for word in str(row['question1']).lower().split(' '):
if word not in stop:
question1.append(word)
剩余12页未读,继续阅读
2022-08-08 上传
点击了解资源详情
2023-10-09 上传
2023-05-24 上传
2023-07-10 上传
2023-05-26 上传
2023-06-13 上传
2023-05-27 上传

深层动力
- 粉丝: 24
- 资源: 318
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
