揭秘Sql Server聚集索引的工作原理与效率提升
58 浏览量
更新于2024-09-01
收藏 449KB PDF 举报
在SQL Server数据库管理系统中,聚集索引是一个至关重要的概念,它对提高查询性能起着关键作用。本文将深入探讨聚集索引的概念、作用、运行原理以及其在实际应用中的表现。
首先,聚集索引的核心作用在于优化数据存储和查询效率。当我们在一个表上创建一个聚集索引时,SQL Server会将索引列的数据按照指定的排序方式存储,并形成一棵B树结构。这种结构的特点使得数据在物理存储上变得有序,从而减少了查找特定记录所需的时间。相比于没有索引的情况,使用聚集索引可以显著降低逻辑读(I/O 操作)次数,特别是对于范围查询,其复杂度从O(N)降低到O(log N),极大地提高了查询性能。
当一个表中只有一个聚集索引时,这是SQL Server的一个设计限制。这是因为每个表的主键默认就是聚集索引,但如果需要额外的聚集索引,必须选择非主键列,并且不能包含NULL值,因为NULL值在B树中无法正确排序。
文章通过实例演示了无索引和拥有聚集索引时的不同情况。在无索引的情况下,查询可能需要遍历整个数据表,导致大量的物理读(I/O),逻辑读次数也非常高。而在拥有聚集索引时,即使数据量很大,查询也能快速定位到所需记录,逻辑读仅需几次操作,这体现了聚集索引在减少磁盘I/O上的巨大优势。
进一步探索聚集索引的工作原理,涉及到B树的数据结构。聚集索引的每个叶子节点包含了索引列的值和对应的行指针,这些行指针指向存储完整数据行的物理位置。当我们进行查询时,数据库系统首先在聚集索引的B树中根据搜索条件找到叶子节点,再通过行指针找到实际的数据行,这便是逻辑读操作。由于B树的高效性,即使数据量庞大,查找过程依然迅速。
文章中提到的dbccind工具是一个用于查看和分析索引结构的实用工具,通过它我们可以观察聚集索引的实际分布情况,这对于理解和优化查询性能至关重要。
理解SQL Server中的聚集索引不仅需要掌握其基本概念,还要深入理解B树的数据结构以及其在查询执行过程中的角色。通过实践和对索引机制的深入剖析,数据库管理员和开发者可以更有效地设计和维护高效的数据库,提升应用程序的响应速度和整体性能。
理解理解Sql Server中的聚集索引中的聚集索引
主要介绍了理解Sql Server中的聚集索引,本文讲解了聚集索引的作用、聚集索引的运行原理等内容,需要的朋友
可以参考下
说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只
能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆。。。。问题就在这里,我们不是学文科,,,不需要去死记硬
背,,,我们需要的就是能看到在眼里面的真实东西。。。。。我们都喜欢聚集索引,因为它能够把无序的堆表记录变成有
序,还玩起了B树。。。这样就把复杂度从N降低到了LogMN。。。
这样的话逻辑读,物理读就下来了。
一:现象一:现象
1:无索引的情况:无索引的情况
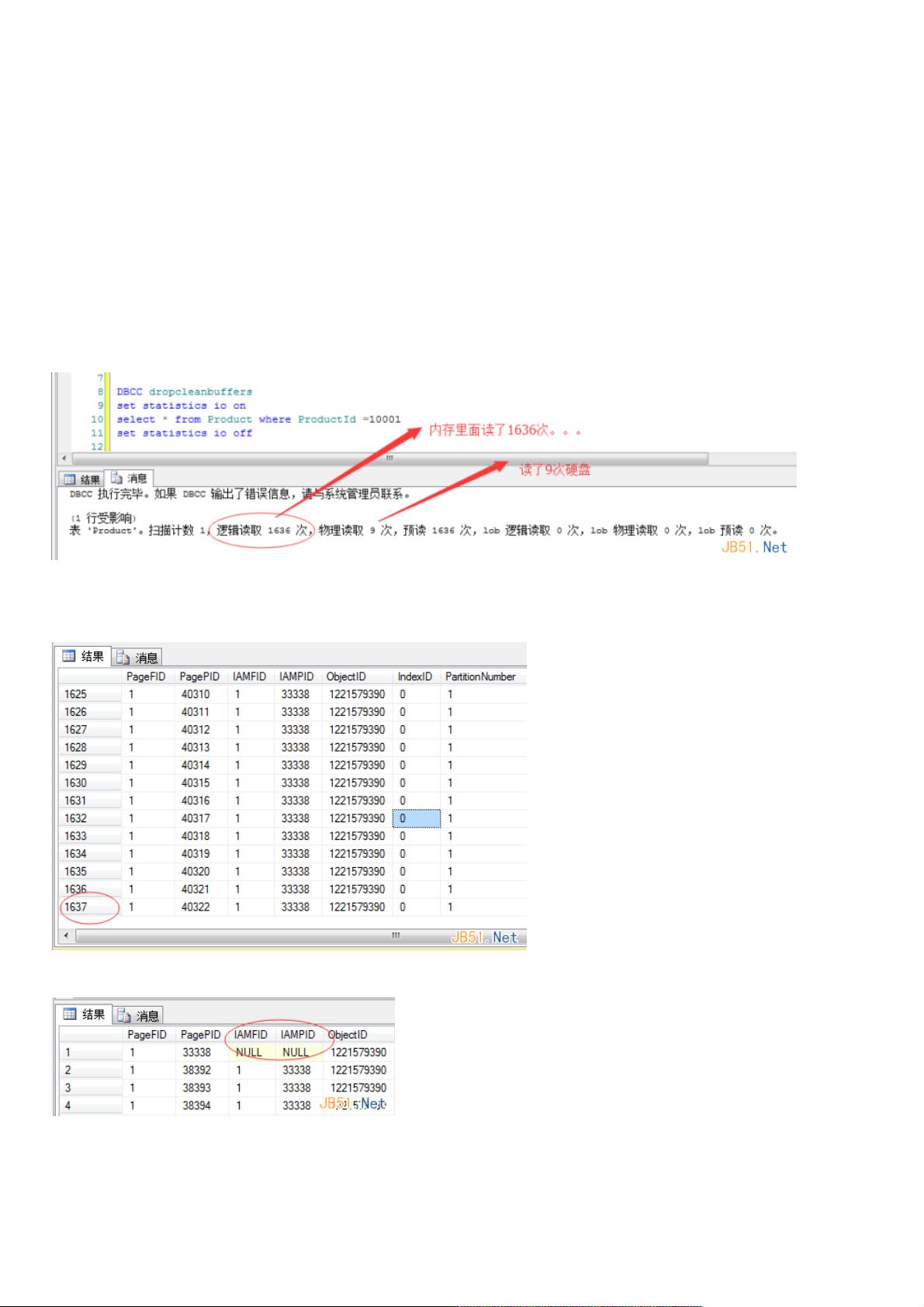
还是老规矩,看个例子感受下,首先我有一个Product表,里面没有任何索引,如下图:
从上图中,我悲剧的看到了,物理读是9次,也就说明走了9次硬盘,你也可以想到,走硬盘的目的是为了拿数据,逻辑读有
1636次,要注意的是这里的”次“是“页”的意思,也就是在内存中走了1636个数据页,我用dbcc ind 给你看一下,是不是有
1636个表数据页。
这里有1637个数据页的原因是第一个是IAM跟踪页。
2:有聚集索引的情况:有聚集索引的情况
下面我在Product表中建一个product_idx_productid的聚集索引,然后再次看看io情况,如下图:
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-12-02 上传
2023-12-01 上传
2020-12-15 上传
2020-12-15 上传
2020-12-15 上传
点击了解资源详情

weixin_38748580
- 粉丝: 6
- 资源: 941
 我的内容管理
展开
我的内容管理
展开







