基于注意力机制的行人属性分析
需积分: 10 128 浏览量
更新于2024-07-15
收藏 3.38MB PDF 举报
"《基于注意力的行人属性分析》(Attention-Based Pedestrian Attribute Analysis)是一篇发表在2019年12月《IEEE Transactions on Image Processing》第28卷第12期的研究论文。该论文针对视频监控中行人属性识别这一具有挑战性的任务进行了深入探讨,尤其是在行人图像存在大幅度的姿态变化、复杂背景以及多角度摄像头拍摄的情况下。
论文主要关注如何通过注意力机制来解决这些挑战。首先,作者提出了三种关键的注意力模型:解析注意力、标签注意力和空间注意力。解析注意力不仅关注在哪里集中注意力,还学习如何从人体不同语义区域(如头部和上身)有效地整合特征,从而提取出区分度高的特征。这种方法有助于处理姿势变化带来的影响,确保信息的准确性。
其次,标签注意力特别设计用于有针对性地收集每个属性的区分特征。它针对每个特定属性进行定向聚焦,强化了对关键属性特征的抽取,提高了识别精度。
空间注意力则关注图像中的局部和全局关系,通过调整不同位置的权重,帮助模型更好地理解行人属性与周围环境的关系,增强特征的上下文依赖性。
这三者结合,使得模型能够在复杂场景下选择重要的、有区分度的特征区域或像素,从而提高行人属性分析的鲁棒性和准确性。通过这三个机制,研究者旨在建立一个更加智能的行人属性识别系统,为视频监控中的行人行为理解和分析提供强有力的技术支持。这篇论文对于计算机视觉领域,特别是在行人分析领域的深度学习方法有着重要的理论贡献和实践价值。"
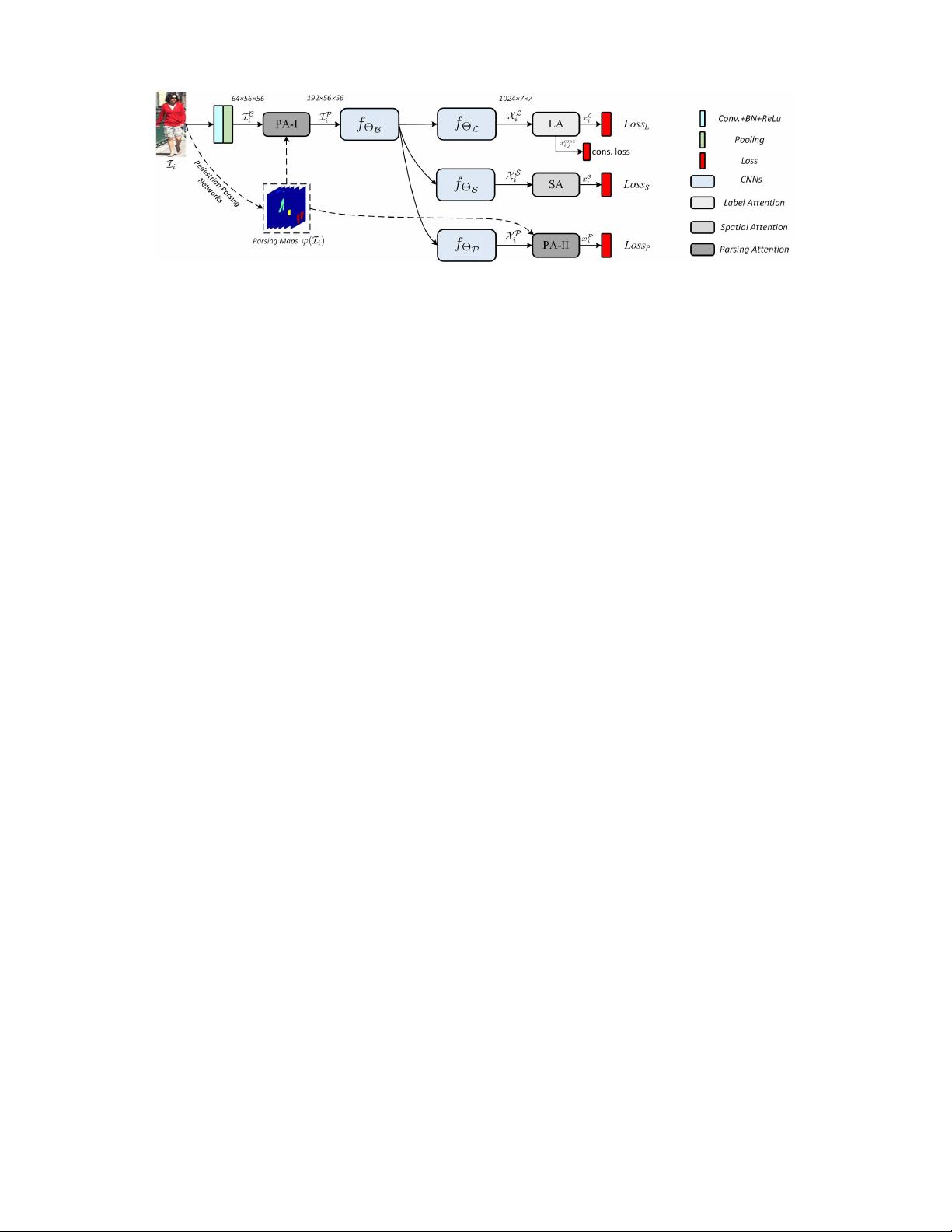
6128 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 28, NO. 12, DECEMBER 2019
Fig. 1. The overview of the proposed network architecture. The network consists of three branches, where each branch is incorporated with a specific attention
mechanism, including parsing attention (PA), label attention (LA) and spatial attention (SA). The network is constructed based on the SE-BN-Inception [24],
which is a light CNN architecture in the SE-Net family [24]. More detailedly, the CNNs module f
B
consists of nine inception blocks [31] and nine SE
blocks [24] with each inception block followed by a SE block. The module f
L
, f
S
, f
P
have the same structure, where a inception block followed by
a SE block are included in each module. To the end, all three branches are jointly learned concurrently with each branch followed by a loss layer.
to explore attribute context and correlation. Lin et al. [5]
propose a discriminative CNN embedding for both person
re-identification and attributes recognition, yielding promising
performance in both tasks. Moreover, Liu et al. [6] pro-
pose a m ulti-directional attention mechanism for fine-grained
pedestrian analysis. In this study, we establish another atten-
tion based method which is different from Liu’s work [6].
Furthermore, three different concurrently learned attention
mechanisms are proposed to consider the prediction problem
from different perspectives.
2) Pedestrian Parsing: Methods [29], [39]–[41] proposed
for pedestrian parsing in the early stage rely heavily on training
set and lack the ability of accurately fitting object boundaries.
However, the present Fully Convolutional Networks (FCNs)
which was a category of network architectures has shown its
effectiveness and efficiency for segmentation tasks [42]–[47].
When it comes to the specific networks in this category,
Long et al. [42] first propose a Fully Convolutional Net-
works (FCNs) for pixel-wise prediction which is originally
used in sematic segmentation, and improve the state-of-the-
art performance by a big margin at that time. More recently,
Zhao et al. [45] propose another network in this category
named as the Pyramid Scene Parsing Network (PSPNet) for
scene parsing which ranks the 1st place in ImageNet Scene
Parsing Challenge 2016. Considering how FCNs category
achieves a great performance in the segmentation tasks, we are
encouraged to construct our pedestrian parsing network based
on FCNs. Nevertheless, we are aware of the fact that the low
resolutio n of pedestrian images in surveillance scenes will
have a negative influence on the performance of the FCNs. For
example, Xia et al. [30] employ FCN-32 and FCN-16 [42] for
pedestrian parsing while get low performance. As a result, it is
inappropriate to directly apply those existing frameworks to
pedestrian parsing and some adjustments should be appended
to those frameworks.
3) Attention: Attention models [19]–[27], [48] have aroused
great enth usiasm in recent years. In the literature, a recurrent
attention convolutional neural network architecture to detect
the discriminative regions for fine-grained imag e reco gnition is
proposed by Fu et al. [21]. Wang et al. [22] propose a residual
attention network th at is constructed b y stacking multiple
attention modules. Moreover, a various of experiments are
also conducted in their work to show the effectiveness of
the proposed network. Li et al. [23] propose an attention
mechanism that consists of spatial and temporal attention for
person re-identification. In more recent work, Hu et al. [24]
propose Squeeze-and-Excitation Networks (SE-Net) for image
classification, where a channels attention mechanism is pro-
posed to recalibrate channel-wise feature responses. With
its superior performance, the SE-Net won first place in
ILSVRC 2017. Shen et al. [48] propose sharp attention
networks for person re-identification, and achieve promising
performance. Inspired by these works, we establish a new
attention network which is expected to achieve better perfor-
mances. Specially, one of our innovations lies in the adoption
of three different kinds of attention mechanisms with two of
which are newly developed. The three attention mechanisms
are not only incorporated into a unified network and learned
jointly, but also, extract the most discriminative features from
different views and reach a mutual complementary to obtain
better prediction performances.
III. O
UR APPROACH
A. The Overall Design
The overview of the proposed network architecture for
pedestrian attributes analysis is shown in Fig. 1. The pro-
posed network architecture is constructed based on the
SE-BN-Inception [24], which is a light CNN architecture in
the SE-Net family. As is presented in the overview, the pro-
posed network architecture utilizes a parallel structure where
each of the three branches is incorporated with a specific
attention mechanism from parsin g attention, label attention
and spatial attention. Since different attention mechanisms
have different perspectives, they are expected to capture the
correlated complementary inf ormation and discover optimal
per-branch discriminative feature representations. To this end,
we formulate a joint learning sch eme with the following
principles: (1) low-level features are shared for all branches.
It can be seen from the Fig. 1 that all three branches
receive common low-level features before performing the
respective CNNs. This shared learning inspired by multi-task
leaning [49], [50] can facilitate not only the inter-attention
common learning, but also the knowledge transfer between
different attentions. Nevertheless, it also helps to reduce the
剩余14页未读,继续阅读
2021-05-10 上传
2020-07-06 上传
2023-05-30 上传
2023-05-30 上传
2023-05-30 上传
2023-05-22 上传
2023-04-23 上传
2023-05-10 上传
2023-02-10 上传

佑林杉
- 粉丝: 10
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
