薛毅、陈立萍《统计建模与R软件》第4章课后习题解答:数据描述与R函数演示
版权申诉
45 浏览量
更新于2024-07-02
收藏 325KB PDF 举报
薛毅和陈立萍合著的《统计建模与R软件》一书中,第4章涵盖了丰富的统计建模理论和实践应用。本章节主要聚焦于数据描述性分析,通过R语言实现对数据集的理解和评估。
在课后的第3.1部分,作者提供了一个名为`myfunction`的函数,用于计算一组数据的多个统计量,如平均值(mean)、方差(variance)、标准差(standard deviation, sd)、中位数(median)、变异系数(coefficient of variation, CV)、偏度(skewness)和峰度(kurtosis)。这个函数接收一个数据向量作为输入,首先读取外部文本文件"data3.1.txt"中的数据,通过`read.table`和`scan`函数处理可能存在的警告,并计算出各种描述性统计指标。结果以数据框的形式返回,包括样本数量(N)、均值、方差、标准误差(std_mean)、变异系数、累积平方和(CSS)、总和平方和(USS)、极差(R)、四分位差(R1)、偏度和峰度。
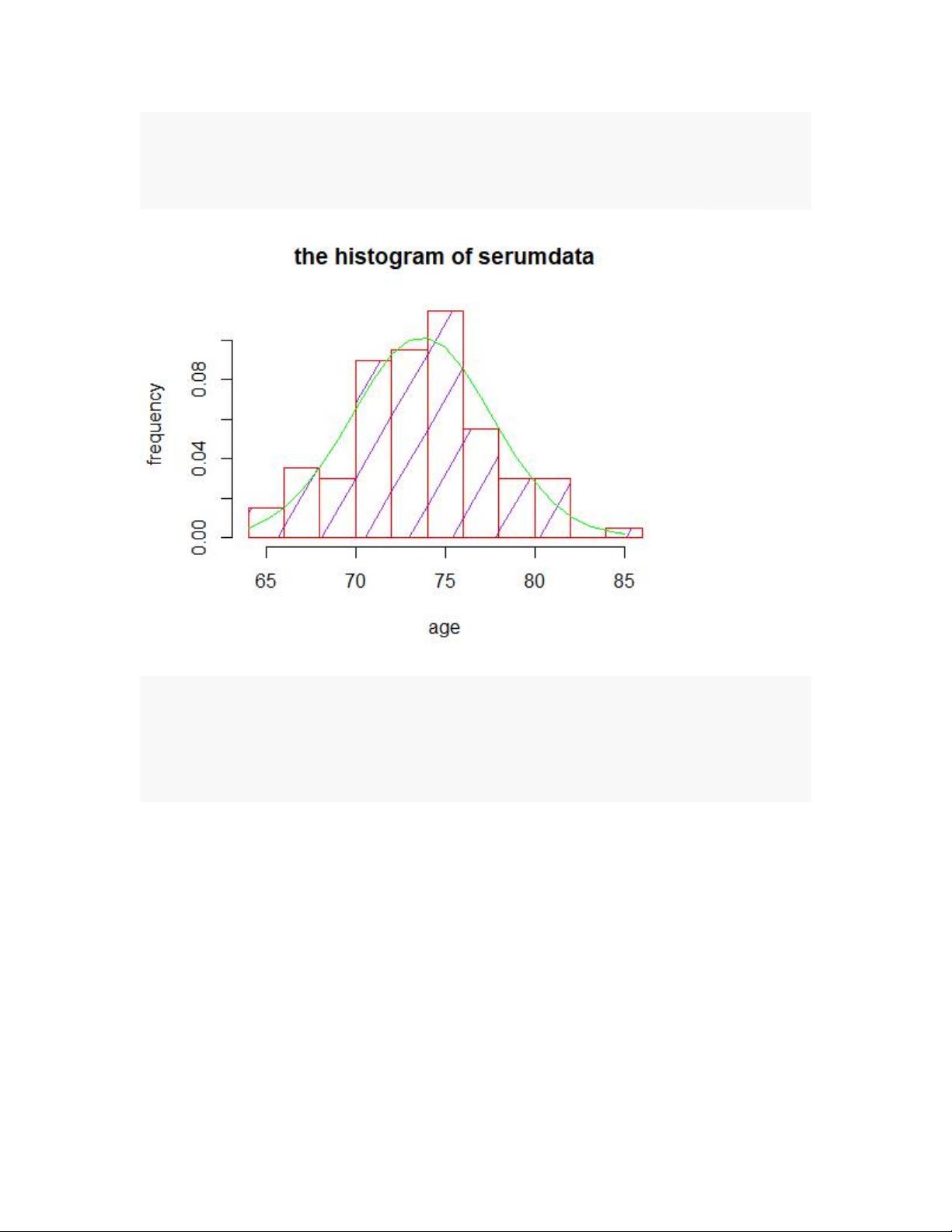
在第3.2部分,作者引导读者进行直方图的绘制。通过`hist`函数,他们展示了如何用紫色背景和红色边框绘制直方图,调整了频率显示(freq=FALSE)、颜色、边框样式、密度设置(density=3)以及图形角度(angle=60),同时设置了图表标题和坐标轴标签,具体为年龄(x轴)和频率(y轴)。此操作有助于观察数据分布的形状和集中趋势,进一步辅助数据探索和模型选择。
这些练习旨在帮助学生掌握R语言在实际数据分析中的应用,理解数据的中心趋势、离散程度以及数据分布的形态,这些都是统计建模的基础。通过解决这些习题,学生不仅可以加深对统计原理的理解,还能提升编程技能,为后续的模型构建和预测奠定坚实的基础。
#
(
3
)画正态分布概率密度曲线
hist(serumdata,freq=FALSE,col="purple",border="red",density=3,angle=60,
main=paste("the histogram of serumdata"),xlab="age",ylab="frequency")
lines(x,dnorm(x,mean(serumdata),sd(serumdata)),col="green")
#
(
4
)绘制经验分布图
plot(ecdf(serumdata),verticals=TRUE,do.p=FALSE)
#
(
5
)绘制正态经验分布图
plot(ecdf(serumdata),verticals=TRUE,do.p=FALSE)
lines(x,pnorm(x,mean(serumdata),sd(serumdata)),col="blue")
剩余15页未读,继续阅读
1865 浏览量
334 浏览量
114 浏览量
2024-12-29 上传
400 浏览量
2301 浏览量
4325 浏览量
130 浏览量

井力15
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 心电图前端设计:集成呼吸起搏检测功能
- 移动端省市区三级联动功能实现与展示
- 建筑涂料喷刷机器人的操作指南解析
- 深入解析Android MaterialDialog开源项目
- Linux命令库详解与Shell操作指南
- dotlambda库:Racket中支持点标识符和Lambda表达式
- PLSQL与Oracle客户端使用与配置教程
- IDEA开发的图书管理系统功能详解
- Bootstrap前端模板开发快速指南
- Android平台的简易数独游戏教程
- Android ReCap API示例代码教程
- 全隔离式锂离子电池监控与保护系统设计
- 模式分类Duda课后习题Matlab程序实现与工具箱指南
- Python脚本自动获取B站直播奖励
- 新型建筑用混凝土定型模具的介绍与应用
- Odoo10公司系统邮件发送功能学习指南
