Hadoop MapReduce详解:分布式计算框架与实战
版权申诉
193 浏览量
更新于2024-07-07
收藏 11.02MB PPTX 举报
"大数据课程——Hadoop集群程序设计与开发,深入讲解MapReduce分布式计算框架,适合教师教学使用,包括教学大纲、教案、教学设计、实训文档等全方位教学资源。"
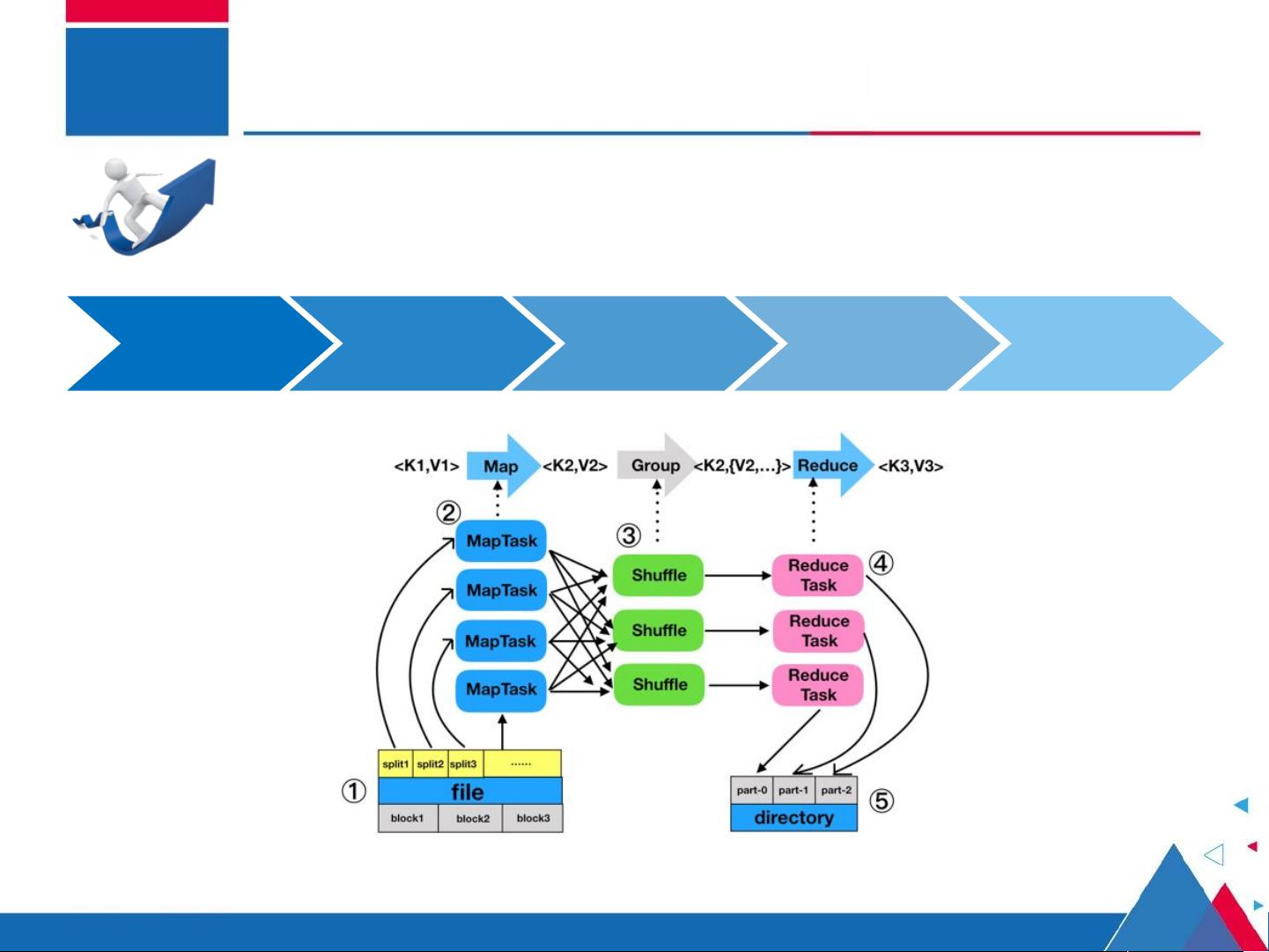
MapReduce是Hadoop生态系统中的核心组件,它为处理和分析大规模数据提供了强大的支持。这一分布式计算框架基于“分而治之”的理念,将复杂问题拆分成多个小任务,然后在多台机器上并行处理,最后再汇总各个部分的结果。MapReduce简化了程序员的工作,他们只需要关注业务逻辑,实现Map和Reduce两个主要接口。
Map阶段是MapReduce程序的起始环节,它负责将输入数据分割成键值对,并将这些键值对作为参数传递给用户定义的Map函数。这个函数通常用于对数据进行预处理,例如过滤、转换等操作,生成中间结果。Map阶段的结果会被排序并分区,以便于Reduce阶段的处理。
Reduce阶段则接收Map阶段产生的中间结果,将相同键的值组合在一起,通过用户定义的Reduce函数进行聚合计算。这一步骤通常用于汇总数据,生成最终的结果。值得注意的是,Reduce阶段是可选的,有些任务可能只需要Map阶段的处理结果。
MapReduce模型具有良好的可扩展性,可以通过添加更多的节点到集群来增加处理能力,同时具备高容错性,当某个节点故障时,任务可以被重新调度到其他健康节点上。然而,MapReduce并不适合实时计算场景,因为它需要完整的Map和Reduce步骤完成,不适合处理连续流入的数据流。此外,对于有依赖关系的任务(DAG任务),MapReduce表现并不理想,因为它假设所有的Map任务和Reduce任务可以独立执行。
MapReduce的编程模型简单,使得开发者可以专注于处理逻辑,而不必过多关注底层的分布式细节。然而,这也意味着在性能调优方面可能会比较复杂,包括数据局部性优化、减少shuffle阶段的数据传输、合理设置Map和Reduce任务的数量等,这些都是提升MapReduce程序性能的关键策略。
MapReduce是大数据处理中的基础工具,尤其适用于离线批处理任务。通过Hadoop集群,MapReduce能够有效地处理PB级别的数据,为大数据分析提供了坚实的基础。在教学中,教师可以结合PPT、教案和实训文档,系统地向学生介绍MapReduce的工作原理、编程模型以及优化技巧,帮助他们掌握大数据处理的核心技能。
✎
4.1 MapReduce
概述
Hadoop
Spark Hive
Hbase
Hadoop
Spark
…
Java php
Android
Html5
Bigdata
python
…
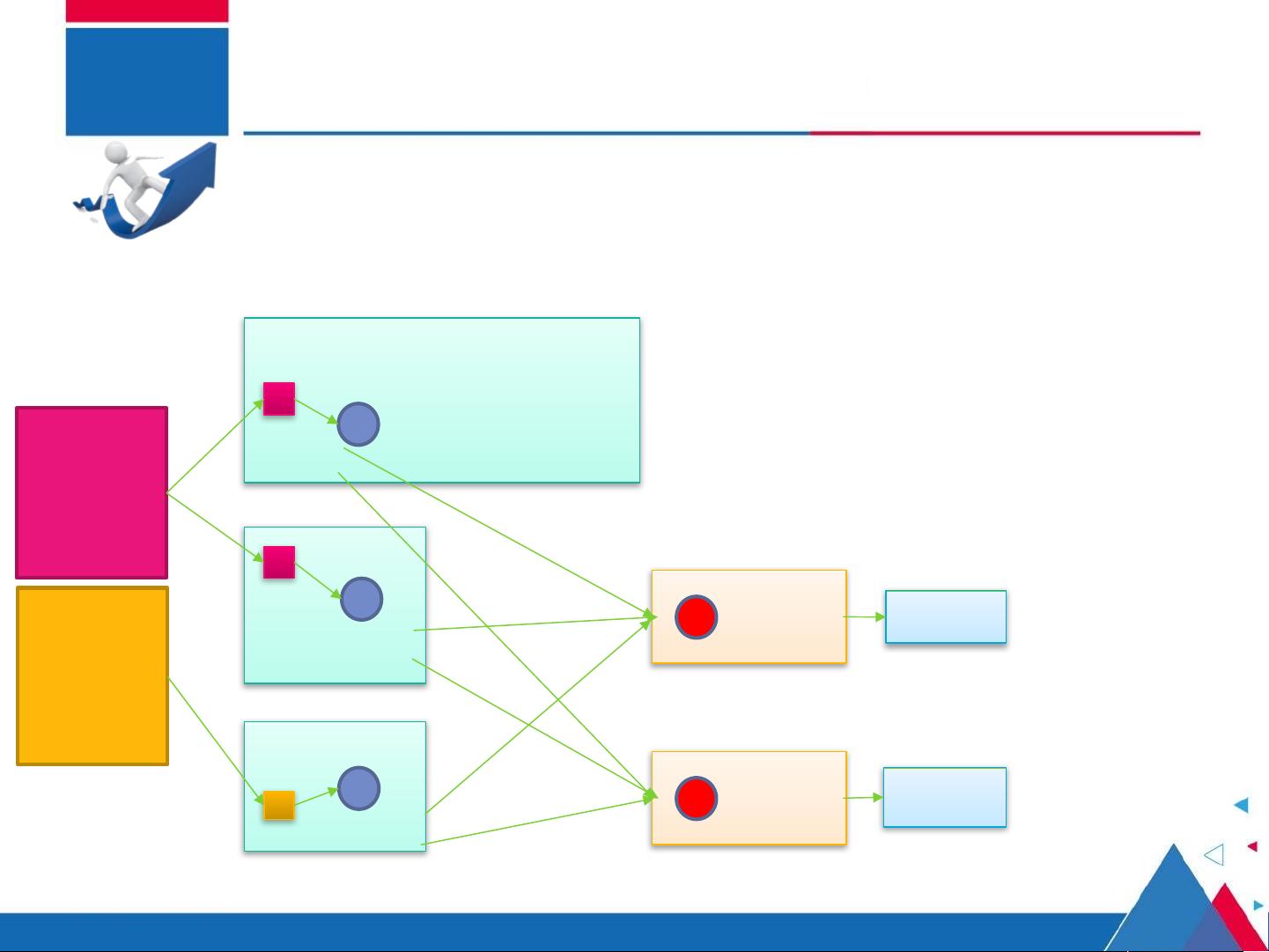
需求:统计其中每
一个单词出现的总
次数(查询结果:
a-p 一个文件, q-z
一个文件)
1
2
3
MapTask
MapTask
MapTask
ReduceTask
ReduceTask
统计 a-p 开头的单词
统计 q-z 开头的单词
1 ) MapReduce 运算程序一般需要分成 2 个阶段:
Map 阶段和 Reduce 阶段
2 ) Map 阶段的并发 MapTask ,完全并行运行,互
不相干
3 ) Reduce 阶段的并发 ReduceTask ,完全互不相
干,但是他们的数据依赖于上一个阶段的所有
MapTask 并发实例的输出
4 ) MapReduce 编程模型只能包含一个 Map 阶段和
一个 Reduce 阶段,如果用户的业务逻辑非常复杂,
那就只能多个 MapReduce 程序,串行运行
分区 2(q-z)
分区 1(a-p)
1 )读数据,并按行处理
2 )按空格切分行内单词
3 ) KV 键值对(单词, 1 )
4 )将所有的 KV 键值对中的
单词,按照单词首字母,分成
2 个分区溢写到磁盘
输出结果
到文件
输出结果
到文件
1 ) MapTask 如何工作
2 ) ReduceTask 如何工作
4 ) MapTask 和
ReduceTask 之间如何衔接
3 ) MapTask 如何控制
分区、排序等
若干问题细节
输入数据
Map 阶段
输出数据
分区 1(a-p)
分区 2(q-z)
分区 1(a-p)
分区 2(q-z)
200m
100m
128m
72m
Reduce 阶段
MapReduce 核心思想

剩余63页未读,继续阅读
点击了解资源详情
404 浏览量
242 浏览量
404 浏览量
243 浏览量
242 浏览量
246 浏览量
643 浏览量
643 浏览量

睡不醒.
- 粉丝: 1323
- 资源: 62
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易语言冰雪战歌音乐盒
- Buddy:基于Leancloud无限制的班级管理系统(学生迫害系统)(:wrapped_gift:也是我可爱的英语老师Buddy的圣诞节礼物)
- highline:将 Markdown 文档中的 GitHub 链接转换为代码块
- BinaryRelationPropertyAnalyser
- docker-sample
- 易语言二行代码显示flash
- 作品答辩环境工程系绿色环保模板.rar
- pyfasttext:fastText的另一个Python绑定
- Tanji-crx插件
- ASP+ACCESS学生管理系统(源代码+LW).zip
- 易语言企达鼠标精灵
- 20210806-华创证券-食品饮料行业跟踪报告:餐饮标准化解决方案暨大消费论坛反馈,川调火热东风至,智慧餐厅初萌芽.rar
- weatherapp
- yii2-semantic-ui:Yii2 语义 UI 扩展
- One_Click_Boom-ocb:一键式解决方案,用于设置大数据处理环境。 Installl是所有bash文件所在的父目录。 只需在终端中通过命令“ chmod 777 *”向位于installl目录内的所有bash文件提供权限
- CLAT Guru-crx插件
