揭秘Hive执行机制:MR MapReduce详解
Hive实现原理是一份由淘宝综合产品团队的作者周忱(花名周忱,真名周敏)编写的教程,他曾在淘宝Hadoop与Hive研发组担任过Leader,并专注于分布式实时计算和开源软件。这份文档详细介绍了Hive的底层实现机制,针对SQL查询如`SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;`进行深入剖析。
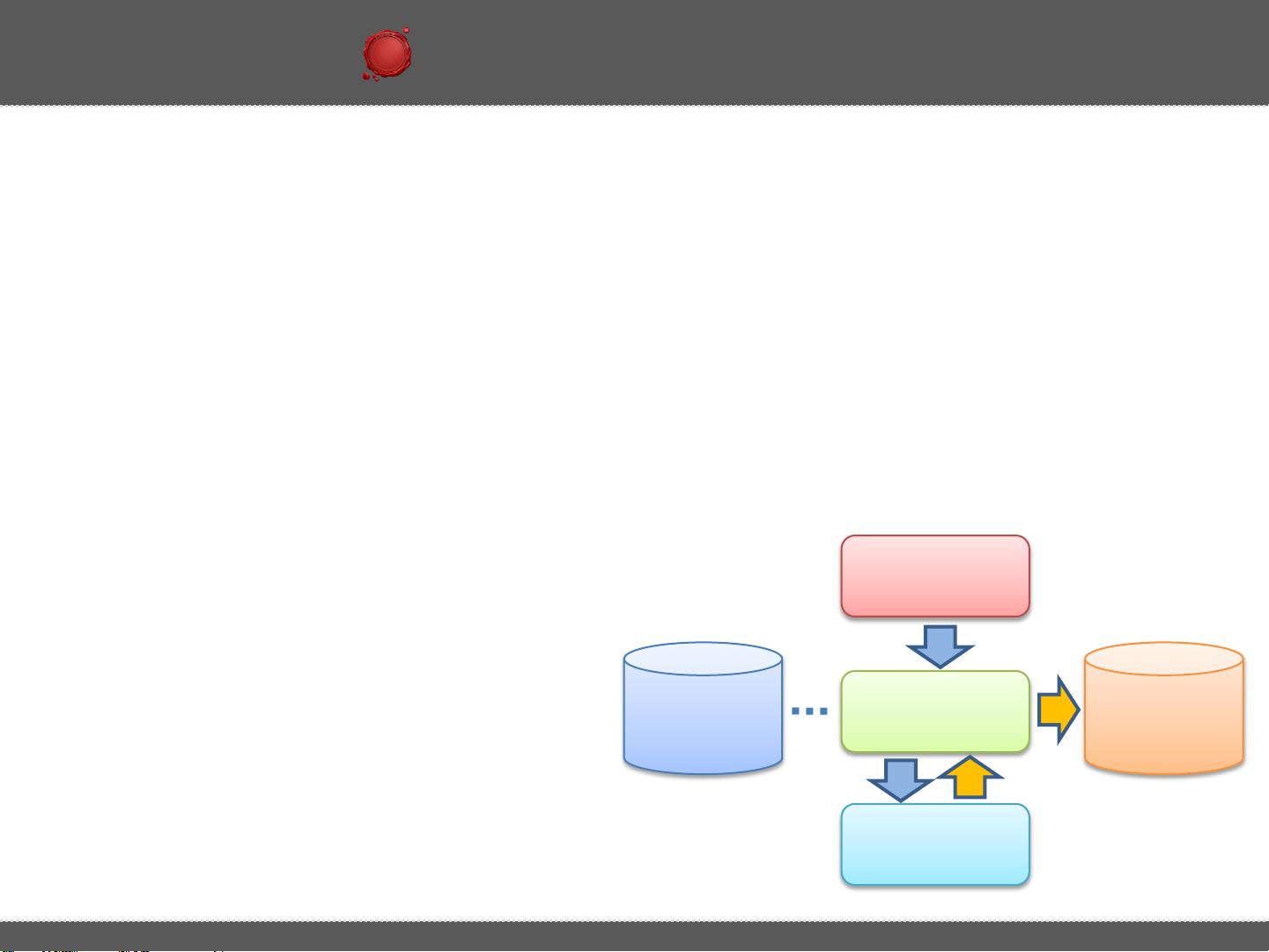
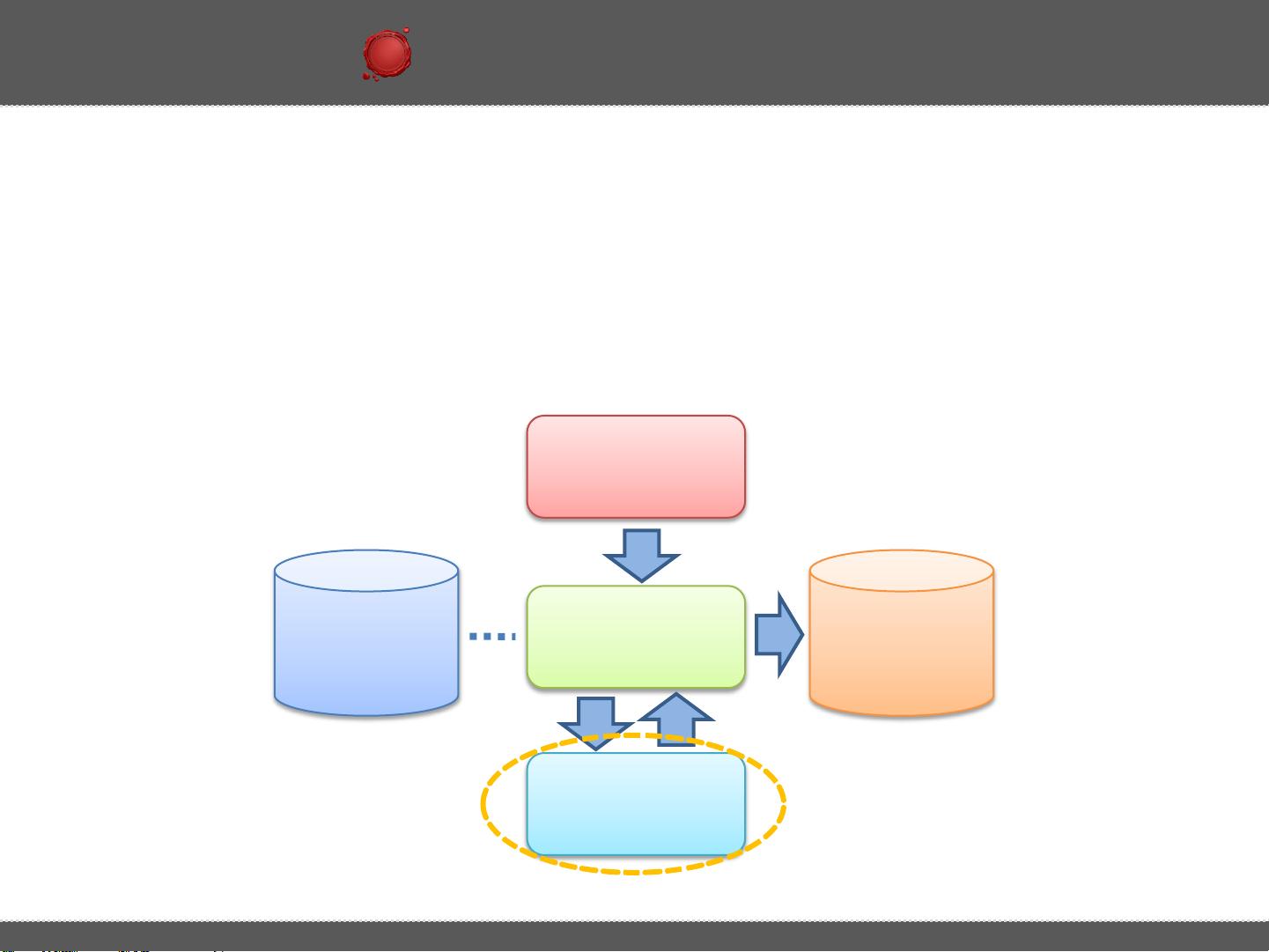
首先,当用户在Hive中编写这样的SQL语句时,实际上是利用了Hadoop生态系统中的MapReduce编程模型来执行数据处理。Hive通过元数据管理工具Hive Metastore存储表结构,用户的数据操作实际上是在这个元数据上进行的。当SQL被解析后,Hive会转化为一系列MapReduce任务。
1. **Map阶段**: 在这个阶段,Hive将SQL语句转换成一系列map tasks。对于`GROUP BY`语句,每个map task会读取pv_users表的一个分区(基于pageid和age),将数据行拆分成键值对,键是`(pageid, age)`,值是行计数(在这里是1)。例如:
- `<1,25>`: 表示pageid为1,age为25的行计数为1
- `<2,25>`: 类似地,pageid为2,age为25的行计数为1
2. **Shuffle和Sort阶段**: 当所有map任务完成,数据会被送到Shuffle阶段,这是MapReduce中的一个重要步骤,它将所有的键值对按照键进行排序和合并。在这个阶段,所有具有相同键的值会被聚集在一起,形成一个键的列表。
3. **Reduce阶段**: 在Shuffle后,每个键对应的值列表(在这里是行计数)会被传递给reduce task。reduce task会对这些值进行累加,得到每个键的最终计数。例如,`<1,25>`和`<1,32>`会被合并,最后的键值对是`<1,3>`,因为总共有两行pageid为1。
4. **结果输出**: 最终,reduce任务将计算出的结果写回Hive Metastore,或者用户指定的输出位置,形成了查询结果,即`pageid`、`age`及其对应的行计数。
总结来说,Hive通过巧妙地利用Hadoop MapReduce框架,实现了SQL查询到分布式计算的无缝转换,提供了易用的接口来操作大规模数据。理解这个原理有助于深入掌握Hive的工作流程,以及如何优化其性能和扩展性。

Hive执行流程
• 操作符
Hive实现原理
1
操作符
描述
TableScanOperator
扫描hive表数据
ReduceSinkOperator
创建将发送到Reducer端的<Key,Value>对
JoinOperator
Join两份数据
SelectOperator
选择输出列
FileSinkOperator
建立结果数据,输出至文件
FilterOperator
过滤输入数据
GroupByOperator
Group By语句
MapJoinOperator
/*+ mapjoin(t) */
LimitOperator
Limit语句
UnionOperator
Union语句
Taobao Java Team | zhouchen.zm
剩余61页未读,继续阅读
2020-09-09 上传
2021-01-07 上传
2021-08-16 上传
点击了解资源详情
点击了解资源详情
2017-01-10 上传
2021-02-24 上传

52Pig
- 粉丝: 28
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Linux操作系统下C语言编程入门.pdf
- 你必须知道的.net
- protel DXP WORD 教程
- PLC自动售货机的设计
- 常见应用软件测试内容
- 全国2008年10月自学考试软件工程试题.doc
- 基于.net平台的分层架构与设计模式
- LINQ Object Relational Mapping in C Sharp 2008
- 触摸屏基础知识.pdf
- 用u盘装系统全过程用u盘装系统全过程
- 汉诺塔的算法,有递归算法
- Flex 3 Cookbook
- 轻松从零开始学 数码相机参数概念解读
- 完美程式设计指南(Wring Solild Code)
- grails in action
- ASP.NET 2.0入门经典-4
