HBase Scan用法详解:API、TableScanMR与SnapshotScanMR
85 浏览量
更新于2024-08-29
收藏 294KB PDF 举报
"HBase最佳实践 – Scan用法大观园"
在HBase中,Scan操作是一种重要的查询方式,尤其在处理大数据量时显得尤为重要。本文将深入探讨Scan的三种常见用法:Scan API、TableScanMR和SnapshotScanMR,旨在揭示它们的工作原理、最佳实践,并进行比较,以帮助读者更好地理解和应用。
首先,Scan API是最基础且常见的用法,适用于简单的客户端查询。在Scan API的设计中,客户端并不一次性获取所有满足条件的数据,而是通过迭代的方式逐行获取。每次调用`next`方法时,如果客户端缓存还有未读取的数据,就直接返回;否则,会向RegionServer发送请求。默认情况下,一次请求最多返回100行数据或结果大小不超过2MB。服务器端在接收到请求后,会从BlockCache、HFile和memcache中顺序读取数据,然后返回给客户端。客户端则将数据缓存在内存中,逐条提供给上层应用。
Scan API的工作方式确保了内存的高效利用,避免了一次性加载大量数据导致的内存压力。然而,这种机制也意味着,对于大数据量的扫描,可能会产生大量的网络交互,影响性能。因此,最佳实践包括合理设置扫描参数,如批大小(batch size)和缓存大小,以平衡网络开销与内存消耗。
其次,TableScanMR是MapReduce框架下的Scan用法,适用于需要进行分布式处理的场景。在TableScanMR中,Map任务会并行地扫描HBase表的各个Region,每个任务处理一部分数据,然后由Reduce任务进行聚合或进一步处理。这种方式适合处理大规模数据的批量计算,但相比Scan API,它的延迟更高,因为涉及到MapReduce的整个生命周期。
再者,SnapshotScanMR是基于HBase快照功能的扫描,它允许在不实际锁定表的情况下,安全地扫描某个时间点的数据状态。这种方式适用于需要回溯历史数据或在多版本数据上进行分析的场景。SnapshotScanMR提供了对特定时间点数据一致性读取的能力,但它的实现较为复杂,且快照本身会占用额外的存储空间。
总结来说,Scan API适用于常规查询,TableScanMR适合大规模数据处理,而SnapshotScanMR则针对特定场景的回溯需求。理解并正确选择Scan用法,对于优化HBase应用程序的性能至关重要。同时,避免一些常见的误区,如忽视缓存设置、不适当使用Scan范围等,也是提升Scan效率的关键。后续的文章将会结合HDFS,更深入地分析HBase数据读取在底层HDFS层面的实现,这对于全面理解HBase的数据访问流程极具价值。
HBase最佳实践最佳实践–Scan用法大观园用法大观园
HBase从用法的角度来讲其实乏陈可善,所有更新插入删除基本一两个API就可以搞定,要说稍微有点复杂的话,Scan的用法
可能会多一些说头。而且经过笔者观察,很多业务对Scan的用法可能存在一些误区(对于这些误区,笔者也会在下文指
出),因此有了本篇文章的写作动机。也算是Scan系列的其中一篇吧,后面对于Scan还会有一篇结合HDFS分析HBase数据
读取在HDFS层面是怎么一个流程,敬请期待。
HBase中Scan从大的层面来看主要有三种常见用法:ScanAPI、TableScanMR以及SnapshotScanMR。三种用法的原理不尽
相同,扫描效率也当然相差甚多,最重要的是这几种用法适用于不同的应用场景,业务需要根据自己的使用场景选择合适的扫
描方式。接下来分别对这三种用法从工作原理、最佳实践两个层面进行解析,最后再纵向对三种用法进行一下对比,希望大家
能够从用法层面对Scan有更多了解。
ScanAPI
scan客户端设计原理
最常见的scan用法,见官方API文档。scan的原理之前在多篇文章中都有提及,为了表述方便,有必要在此简单概述一番。
HBase中scan并不像大家想象的一样直接发送一个命令过去,服务器就将满足扫描条件的所有数据一次性返回给客户端。而
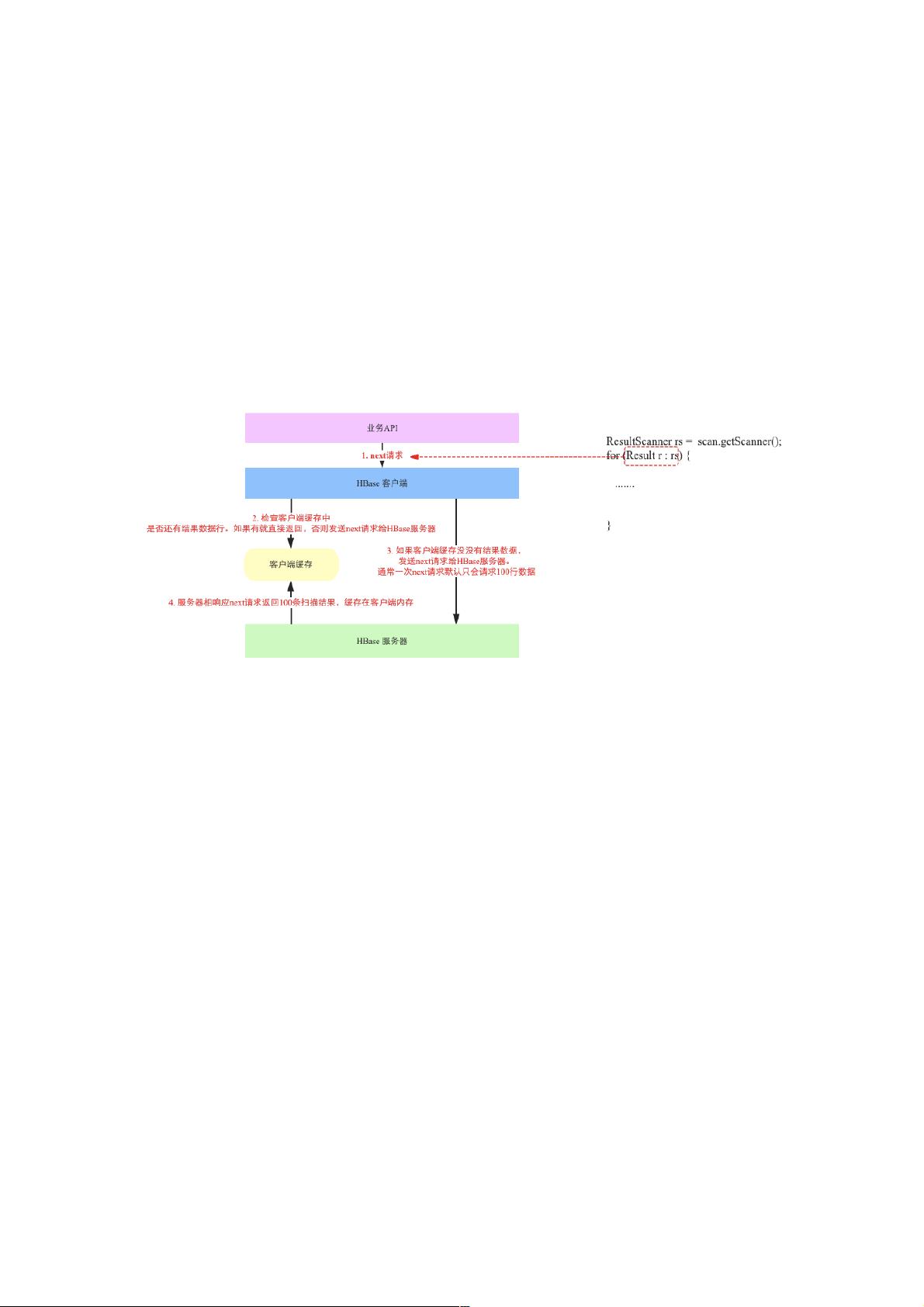
实际上它的工作原理如下图所示:
上图右侧是HBase scan的客户端代码,其中for循环中每次遍历ResultScanner对象获取一行记录,实际上在客户端层面都会
调用一次next请求。next请求整个流程可以分为如下几个步骤:
next请求首先会检查客户端缓存中是否存在还没有读取的数据行,如果有就直接返回,否则需要将next请求给HBase服务器端
(RegionServer)。
如果客户端缓存已经没有扫描结果,就会将next请求发送给HBase服务器端。默认情况下,一次next请求仅可以请求100行数
据(或者返回结果集总大小不超过2M)
服务器端接收到next请求之后就开始从BlockCache、HFile以及memcache中一行一行进行扫描,扫描的行数达到100行之后
就返回给客户端,客户端将这100条数据缓存到内存并返回一条给上层业务。
上层业务不断一条一条获取扫描数据,在数据量大的情况下实际上HBase客户端会不断发送next请求到HBase服务器。有的朋
友可能会问为什么scan需要设计为多次next请求的模式?个人认为这是基于多个层面的考虑:
HBase本身存储了海量数据,所以很多场景下一次scan请求的数据量都会比较大。如果不限制每次请求的数据集大小,很可
能会导致系统带宽吃紧从而造成整个集群的不稳定。
如果不限制每次请求的数据集大小,很多情况下可能会造成客户端缓存OOM掉。
如果不限制每次请求的数据集大小,很可能服务器端扫描大量数据会花费大量时间,客户端和服务器端的连接就会timeout。
这样的设计有没有瑕疵?
next策略可以避免在大数据量的情况下发生各种异常情况,但这样的设计对于扫描效率似乎并不友好,这里举两个例子:
scan并没有并发执行。这里可能很多看官会问:扫描数据分布在不同的region难道也不会并行执行扫描吗?是的,确实不会,
至少在现在的版本中没有实现。这点一定出乎很多读者的意料,我们知道get的批量读请求会将所有的请求按照目标region进
行分组,不同分组的get请求会并发执行读取。然而scan并没有这样实现。
大家有没有注意到上图中步骤3和步骤4之间HBase服务器端扫描数据的时候HBase客户端在干什么?阻塞等待是吧。确实,
所以从客户端视角来看整个扫描时间=客户端处理数据时间+服务器端扫描数据时间,这能不能优化?
ScanAPI应用场景
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-03-18 上传
2021-01-27 上传
2019-11-09 上传
2021-02-25 上传
点击了解资源详情

weixin_38711740
- 粉丝: 5
- 资源: 952
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
