深度学习驱动的端到端图像压缩技术进展
42 浏览量
更新于2024-08-27
1
收藏 10.42MB PDF 举报
"基于端到端学习的图像编码研究及进展"
本文主要探讨了在图像大数据时代背景下,随着硬件技术的快速发展,基于深度学习的图像视频编码技术的重要性和应用。端到端学习的图像压缩框架因其在原始图像数据压缩效率上的优势,受到了学术界和工业界的广泛关注。文章系统性地概述了这个领域的核心组成部分,包括变换、量化、熵编码和损失函数的研究现状,并对相关技术的最新进展进行了详细介绍。
首先,图像压缩中的“变换”是将图像数据从空间域转换到频域的关键步骤,传统的图像压缩方法如JPEG使用离散余弦变换(DCT)。然而,基于深度学习的端到端方法可以自定义变换层,通过神经网络学习更适应数据特性的变换方式,从而提高压缩效率。
其次,“量化”是图像压缩过程中的另一个重要环节,它将变换后的系数映射到有限的数值集合中。传统的量化过程可能导致信息丢失,而深度学习方法可以学习更精细的量化策略,减少失真并优化压缩性能。
接着,熵编码是将量化后的数据进行高效编码的过程,如算术编码或哈夫曼编码。深度学习引入后,可以学习数据的概率分布,实现自适应的熵编码,进一步提升压缩比率。
再者,损失函数的选择对压缩质量有直接影响。传统的MSE(均方误差)或PSNR(峰值信噪比)可能无法完全捕捉视觉感知质量,因此,研究者们探索了诸如MS-SSIM(多尺度结构相似度)、VGG损失等深度学习相关的损失函数,以更好地模拟人类视觉系统的感知特性。
文章还对比分析了近期的一些前沿研究成果,如神经网络模型在压缩效率和重构质量方面的表现,以及不同方法在复杂性和解码速度上的权衡。这些研究不仅推动了理论上的进步,也为实际应用提供了更多可能性,例如在云计算、物联网(IoT)设备、高清视频流媒体等领域。
基于端到端学习的图像编码已经成为图像压缩领域的一个重要研究方向。未来,这一技术有望在提高压缩效率、降低带宽需求的同时,保持高质量的图像重建,对于图像大数据的存储和传输具有重大意义。随着深度学习技术的不断发展,我们期待看到更多创新的图像压缩算法,以应对日益增长的图像数据处理挑战。
激 光 与 光 电 子 学 进 展
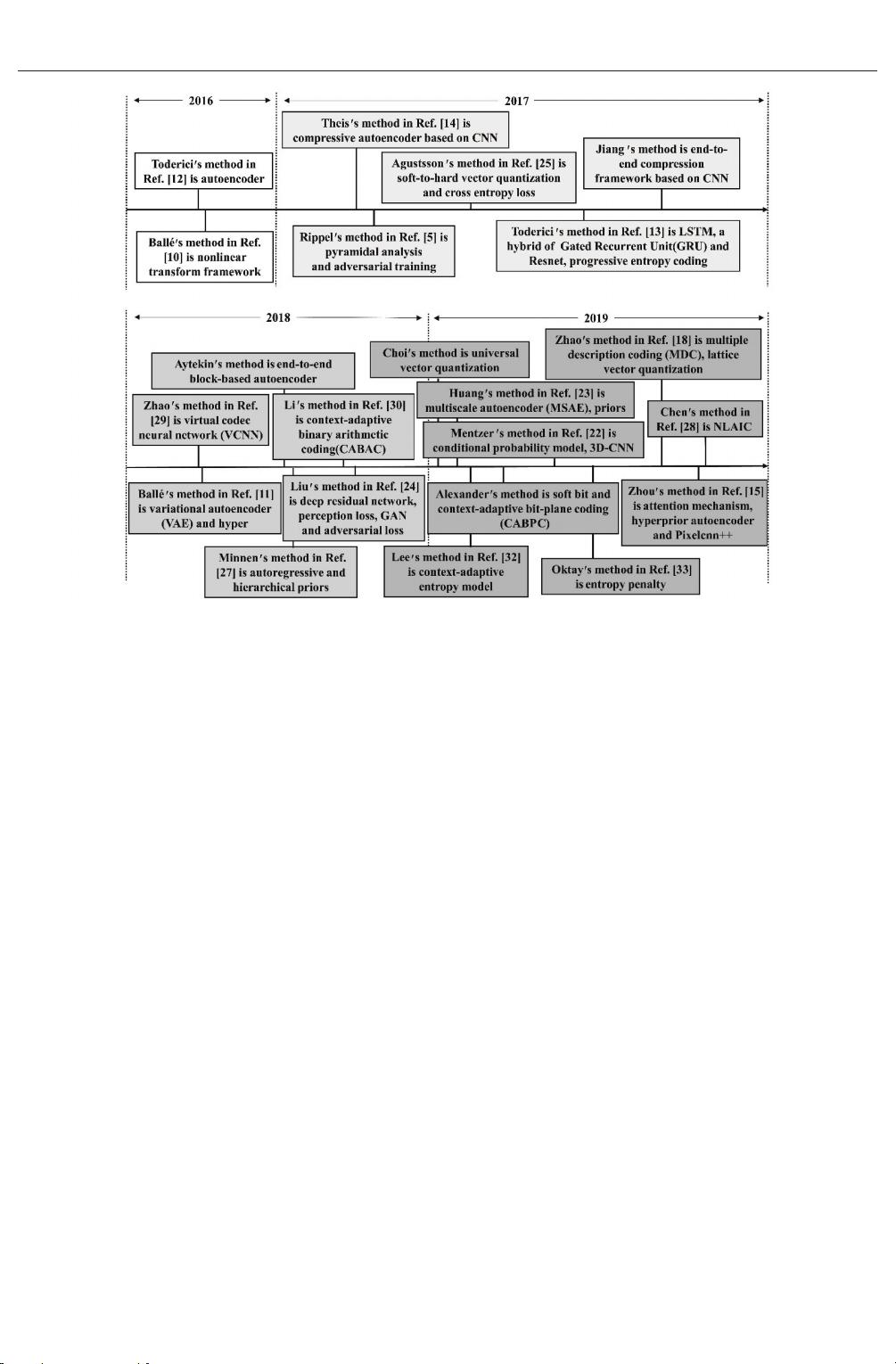
图
基于端到端学习的图像编码技术发展历程
21
变
换
图像变换编码将空域图像像素转换为变换域系
数
实现能量聚集 的紧致表 达
以达到压 缩 的目的
大多数压缩方法都使用正交线性变换来降低数据的
相关性
在传统的 变换方法 中
最早针对 信 号冗余
解耦优化的线性变换可以追溯至
变换和主成分
分析法
之 后 国 际 图 像 编 码 标 准
和
分别使用的离散余 弦变换和小 波变换 也
均为线性变换
但是正交线性变换中线性滤波器响应的联合统
计量呈现了很强的 高阶依赖 性
为解决此 问 题可联
合局部非线性进 行 增益控制
近几年
端到端学 习
将非线 性 变 换 融 入 图 像 压 缩 框 架 中
其 中
等
提出了基于非线性变换编码的端到端学习框
架
图
将 图 像 强 度 向 量
x
先 通 过 分 析 变 换
y
g
x
ϕ
其中
ϕ
为学习参数 向量
映射到编 码 域
再通过量化处理 得 到 离 散 值 向 量
q
之 后 进 行 熵 编
码
相对应地
由离散值向量
q
估计连续值 向量
y
应用生成变换
x
g
y
θ
其中
θ
为学习参数向
量
并进行像素重 建
编码决策 通 过率失真 优 化性
能
常见的失真度量包括均方误差
和
也可引入感知失真 等进行性 能 优化
最后端到 端 学
习系统通过优 化 学 习 参 数 向 量
ϕ
和
θ
来 最 小 化 码
率
R
和失真
D
的加权和
R
λD
其中
λ
控制码率
和失真的平衡
分析变换分为三个阶段
卷积
下采
样和
变换
作 为 其 逆 变 换 的 生 成 变 换 也 分 为
三个阶段
仿 射 卷 积
上 采 样 和
逆
变
换
且两类变换中的 上 下采样操 作 均可通过 卷 积来
实现
从而提高了计算 效 率
感知变换 中 归一化拉
普拉斯金字塔模型
与
的组合考虑 了图
像局部亮度和对比度的误差
相 较 于 采 用
优
化
的传 统 方 法 而 言
在 相 似 重 建 质 量 的 情 况
下降低了码率
现今
自编码器被 越来越广泛 地用于图像 压缩
中
这些研究利用单个自编码器或循环自编码器在
瓶颈 层 生 成
用 于 后 续 的 量 化 和 熵 编 码
典型的自编码器结构包含三个部分
编码器
表示压
缩数据的瓶颈和解 码器
将这三个 部 分级联并 进 行
端到端训练
由于传统
等算法中线性变换对
空间相关性和压缩 数据分布 的 利用不够 充 分
使用
深度卷积神经网络 可实现非 线 性变换
对图像分 布
进行更好的冗余解 耦
实现更紧 致 的特征表 达 并实
现更好的压缩
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-31 上传
2021-08-19 上传
2022-06-01 上传
2010-12-29 上传
点击了解资源详情
点击了解资源详情

抹蜜茶
- 粉丝: 303
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
