
1. Single-processor Computing
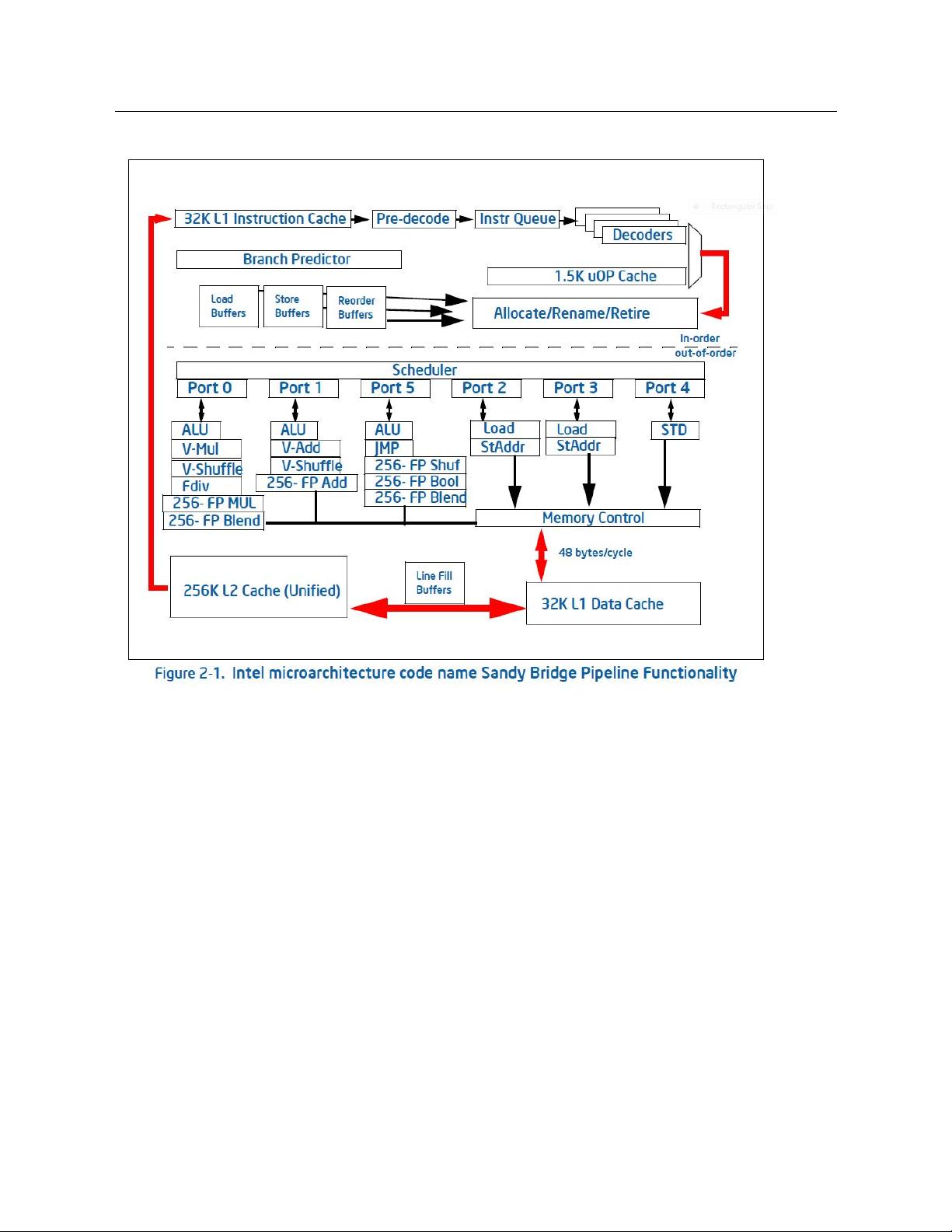
Figure 1.2: Block diagram of the Intel Sandy Bridge core
are. Division operations can take 10 or 20 clock cycles, while a CPU can have multiple addition and/or
multiplication units that (asymptotically) can produce a result per cycle.
1.2.1.3 Pipelining
The floating point add and multiply units of a processor are pipelined, which has the effect that a stream of
independent operations can be performed at an asymptotic speed of one result per clock cycle.
The idea behind a pipeline is as follows. Assume that an operation consists of multiple simpler opera-
tions, and that for each suboperation there is separate hardware in the processor. For instance, an addition
instruction can have the following components:
• Decoding the instruction, including finding the locations of the operands.
• Copying the operands into registers (‘data fetch’).
• Aligning the exponents; the addition .35×10
−1
+ .6×10
−2
becomes .35×10
−1
+ .06×10
−1
.
• Executing the addition of the mantissas, in this case giving .41.
16 Introduction to High Performance Scientific Computing




剩余574页未读,继续阅读

josias
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


