GHome:打造家庭信息化新时代
版权申诉
182 浏览量
更新于2024-07-08
收藏 2.92MB PPTX 举报
"GHome家庭信息化解决方案是融创天下产品管理部提出的一种全面解决家庭信息化需求的方案,旨在利用现代信息技术构建和睦、平安、智慧的家庭环境,增强家庭成员间的亲情交流,并为运营商提供竞争优势。方案涵盖了家庭网关、家庭信息机、家庭监控、远程教育、亲情服务等多种功能,以满足不同家庭的需求。
1. 家庭信息化的意义:
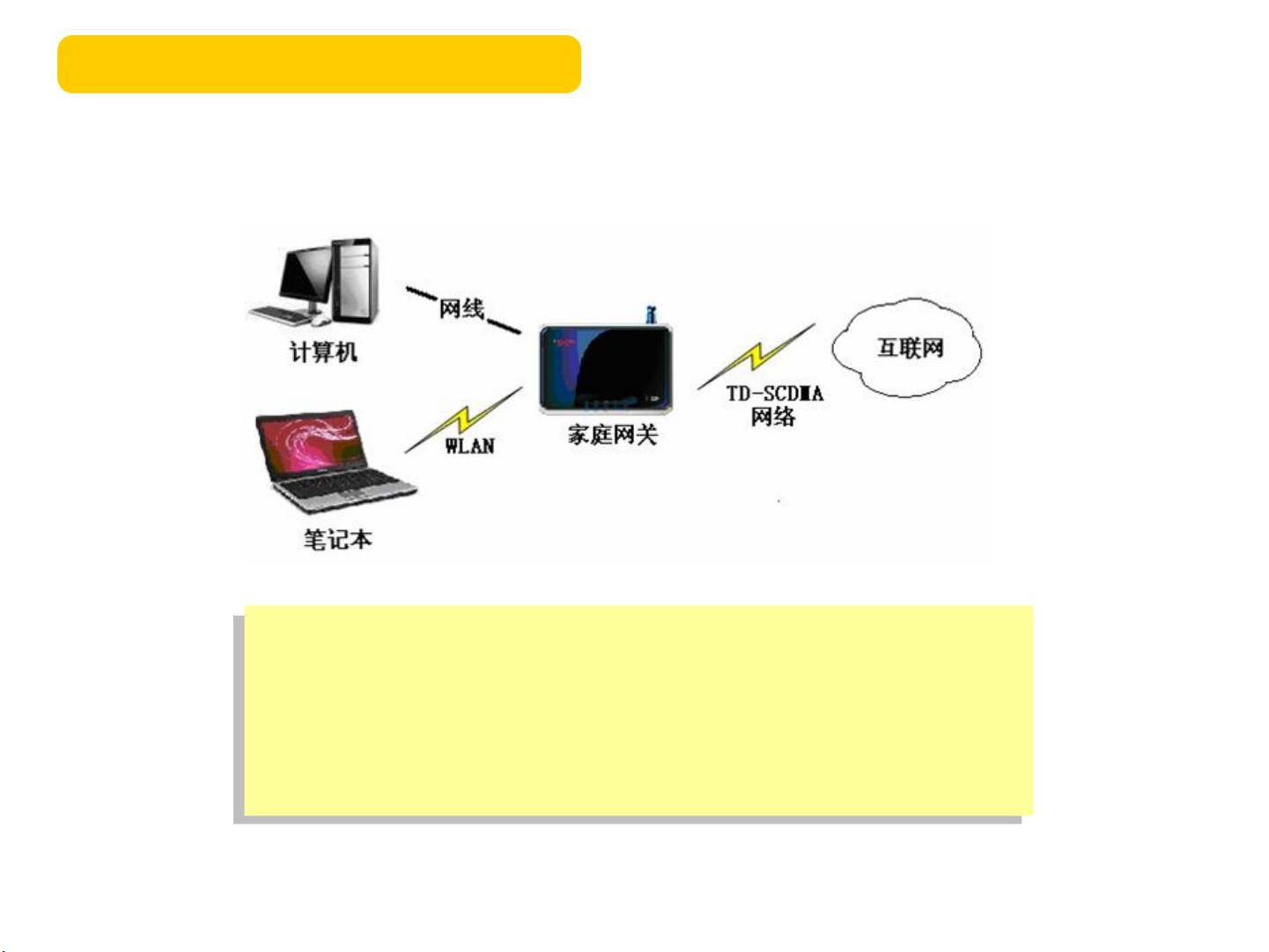
- 对运营商的意义:家庭信息化业务是运营商在全业务运营竞争中的关键,可以推动3G网络建设和业务发展,增加移动用户的增长,如中国电信在2009年的用户增长情况所示。家庭网关作为融合各种数据业务的中心,对运营商具有战略价值。
- 对用户的意义:随着IP宽带用户的增长和家庭网络的普及,3C(计算机、通信、消费电子)的融合趋势推动了新的宽带价值链的形成。家庭信息化服务平台能够提供便民生活服务,通过家庭信息机和家庭智能终端实现家庭娱乐分享、情感交流,提升家庭生活质量,同时提供视频监控和安防报警功能,确保家庭安全。
2. GHome家庭信息化产品:
- GHome家庭信息化业务不仅包括家庭信息化服务平台,还推出了家飞猫产品,如HB-T2型号。家飞猫的功能不断演进,能够实现手机观看家中的数字电视,分享照片和自拍视频,甚至远程监控家庭安全,例如通过门磁、红外传感器、烟感等设备进行实时监控,并将警报信息推送到用户手机。
3. 技术介绍:
GHome技术可能涉及到IP网络技术、多媒体处理、云计算、物联网和移动通信技术,这些技术的集成使得家庭信息化产品能够实现跨设备的数据共享、远程控制和实时通讯。
4. 家庭信息化市场分析:
市场分析可能涉及当前家庭信息化市场的规模、增长潜力、竞争对手分析以及消费者需求调研。这一部分将帮助确定产品定位和市场策略。
5. 营销管理及营销落实:
这一部分可能涵盖产品的市场推广策略、销售渠道建设、合作伙伴关系管理以及售后服务等方面,旨在确保GHome家庭信息化解决方案能够成功进入市场并获得用户认可。
GHome家庭信息化解决方案是针对家庭信息化需求的全方位策略,通过先进的技术手段和创新的服务模式,旨在提升家庭生活的便捷性、安全性和娱乐性,同时也为运营商提供了新的业务增长点。"

2. 家飞猫 HB-T268 功能介绍 -1
家飞猫无线座机 -TD 语音功能
功能:
将电话机通过电话线连接至家飞猫的 RJ11 口,可拨打电
话
支持来电显示功能
支持呼叫转移
TD 模块支持 TD-SCDMA 和 GSM 的双模自动切换
剩余48页未读,继续阅读
2021-10-07 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

m0_62049925
- 粉丝: 0
- 资源: 22万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
