Hadoop2.0集群安装完全指南
200 浏览量
更新于2024-07-18
3
收藏 4.5MB PDF 举报
"Hadoop2.0安装详细步骤"
在安装Hadoop 2.0的过程中,首先需要理解Hadoop的基本架构和工作原理。Hadoop是一个开源的分布式计算平台,由Apache软件基金会开发,主要由两个核心组件组成:Hadoop分布式文件系统(HDFS)和MapReduce。HDFS提供了一个高容错性的文件存储系统,而MapReduce则是一种并行处理和计算框架。
1. Hadoop集群的角色划分
- Master节点:在Hadoop集群中,Master节点通常包括NameNode和JobTracker。NameNode是HDFS的主节点,负责管理文件系统的元数据(如文件名、块信息等),并控制客户端对文件系统的访问。JobTracker则是MapReduce框架的主节点,它调度和监控MapReduce作业的执行。
- Slave节点:Slave节点主要包括DataNode和TaskTracker。DataNode是HDFS的一部分,它们存储数据块并响应NameNode的指令进行数据读写。TaskTracker运行在Slave节点上,接收JobTracker分配的任务,并在本地执行Map或Reduce任务。
2. 安装环境
- 在实际安装时,通常会构建一个多节点的集群,例如在本例中,集群包含1个Master节点和3个Slave节点。所有节点需要通过局域网相互连接,确保网络连通性,并能够相互ping通。在安装前,需要准备所有节点的操作系统环境(通常是Linux),并确保系统配置一致。
3. 安装步骤
- 准备环境:首先,要在所有节点上安装Java环境,因为Hadoop依赖于Java运行。通常需要安装JDK,并设置好JAVA_HOME环境变量。
- 下载Hadoop:从Apache官方网站获取Hadoop的二进制发行版,并解压到指定目录。
- 配置Hadoop:修改Hadoop的配置文件,如`hdfs-site.xml`(配置HDFS参数)、`mapred-site.xml`(配置MapReduce参数)和`core-site.xml`(核心配置)。这一步骤中,需要明确Master和Slave节点的角色,以及数据存储路径等信息。
- 格式化NameNode:首次安装时,需要对NameNode进行格式化,初始化HDFS的命名空间。
- 启动Hadoop服务:启动Hadoop的各个守护进程,包括NameNode、DataNode、JobTracker和TaskTracker。通常可以通过start-dfs.sh和start-mapred.sh脚本启动。
- 验证安装:安装完成后,可以通过检查HDFS的web界面(默认端口50070)和JobTracker的web界面(默认端口50030)来确认服务是否正常运行。此外,可以尝试上传文件到HDFS,运行简单的MapReduce作业来测试集群功能。
4. 注意事项
- 防火墙设置:确保所有相关端口在防火墙中开放,以便节点间通信。
- 安全设置:在生产环境中,可能需要考虑Hadoop的安全配置,如开启Hadoop的Secure Mode,使用Kerberos进行身份验证。
- 资源管理:根据集群的硬件资源合理配置HDFS的副本数和MapReduce的槽位数,以充分利用硬件资源并保持系统稳定性。
通过以上步骤,可以完成Hadoop 2.0的安装。然而,安装过程可能会因具体环境和需求有所不同,因此在实际操作时,还需要参考官方文档或社区提供的详细教程进行调整。

2016/12/15 Hadooop集群安装超详细(转)woshigeshou123的专栏博客频道CSDN.NET
http://blog.csdn.net/woshigeshou123/article/details/8833174?locationNum=3&fps=1 12/72
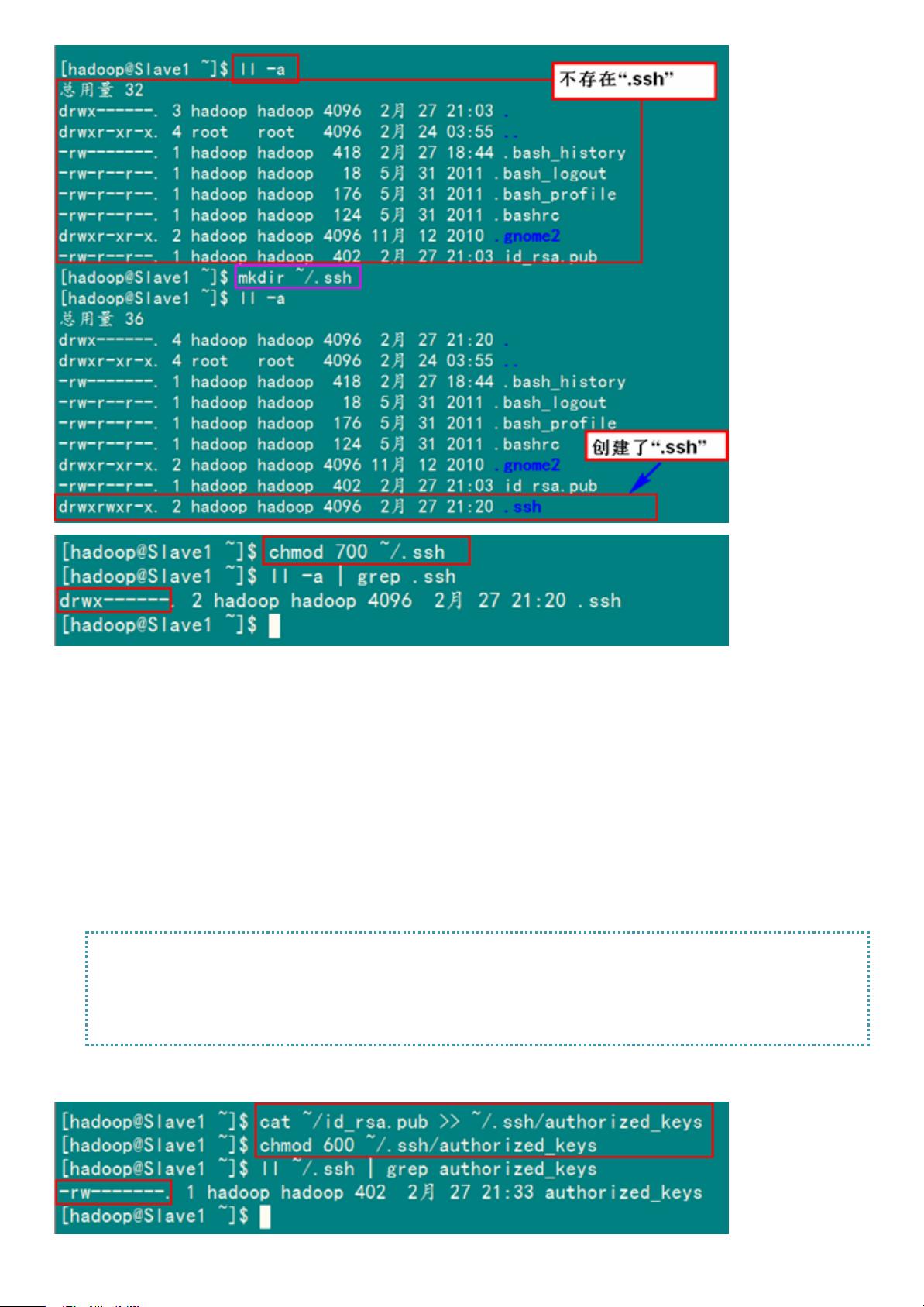
备注:如果不进行设置,在验证时,扔提示你输入密码,在这里花费了将近半天时间来查找原因。在网
上查到了几篇不错的文章,把作为"Hadoop集群_第5期副刊_JDK和SSH无密码配置"来帮助额外学习之用。
2)设置SSH配置
用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。
RSAAuthenticationyes#启用RSA认证
PubkeyAuthenticationyes#启用公钥私钥配对认证方式
AuthorizedKeysFile.ssh/authorized_keys#公钥文件路径(和上面生成的文件同)
设置完之后记得重启SSH服务,才能使刚才设置有效。
servicesshdrestart
退出root登录,使用hadoop普通用户验证是否成功。
sshlocalhost


剩余71页未读,继续阅读
2016-01-07 上传
2024-06-19 上传
2024-09-06 上传
2023-05-14 上传
2024-06-21 上传
2023-06-09 上传
2024-01-05 上传
2023-06-01 上传

LittleBryce
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
