掌握Hive:离线计算系统实战教程
需积分: 12 133 浏览量
更新于2024-07-16
收藏 1.42MB DOCX 举报
本资源详细介绍了离线计算系统中的Hive技术,这是第11天的学习内容,重点集中在Hive的深入理解和实战应用上。Hive是Apache Hadoop生态系统中的一个关键组件,它作为一个数据仓库工具,为Hadoop提供了结构化数据处理的能力,通过类SQL查询的方式简化了大数据处理过程。
学习目标明确,包括熟练掌握Hive的使用,包括其客户端接口(如Shell CLI、JDBC/ODBC和WebGUI)、HQL(Hive Query Language)的编写,理解Hive的工作原理,以及提升在实际项目中的应用能力。Hive的设计初衷是为了克服Hadoop MapReduce在开发复杂查询时的困难,通过SQL接口降低了学习曲线,提高了开发效率。
Hive的核心特点是可扩展性和容错性。它能够无缝扩展到大规模集群,且当单个节点故障时,查询仍能继续执行。此外,Hive还支持用户自定义函数,增加了灵活性。Hive架构主要包括用户接口、元数据存储、解释器、编译器、优化器和执行器等部分,它们协同工作以处理用户的查询请求。
Hive与Hadoop紧密集成,利用HDFS存储数据,而MapReduce则用于执行Hive生成的查询计划。这使得Hive既能利用Hadoop的大规模分布式处理能力,又能提供易于理解和使用的SQL查询体验。与传统数据库相比,Hive更专注于批处理和数据分析,而非实时交互。
Hive的数据存储全部在HDFS上,这使得Hive适合于大规模数据的长期存储和处理,特别适合进行复杂的数据清洗、聚合和分析任务。总结来说,Hive是大数据领域的重要工具,对于数据分析师、数据工程师或任何需要对大量结构化数据进行深度处理的团队来说,掌握Hive是提高工作效率和处理能力的关键。通过本资源的学习,读者将能更好地理解和应用Hive在实际项目中的角色。
1.6 HIVE 的安装部署
1.6.1 安装
单机版:
元数据库 $;-" 版:
1.6.2 使用方式
Hive 交互 shell
4<!
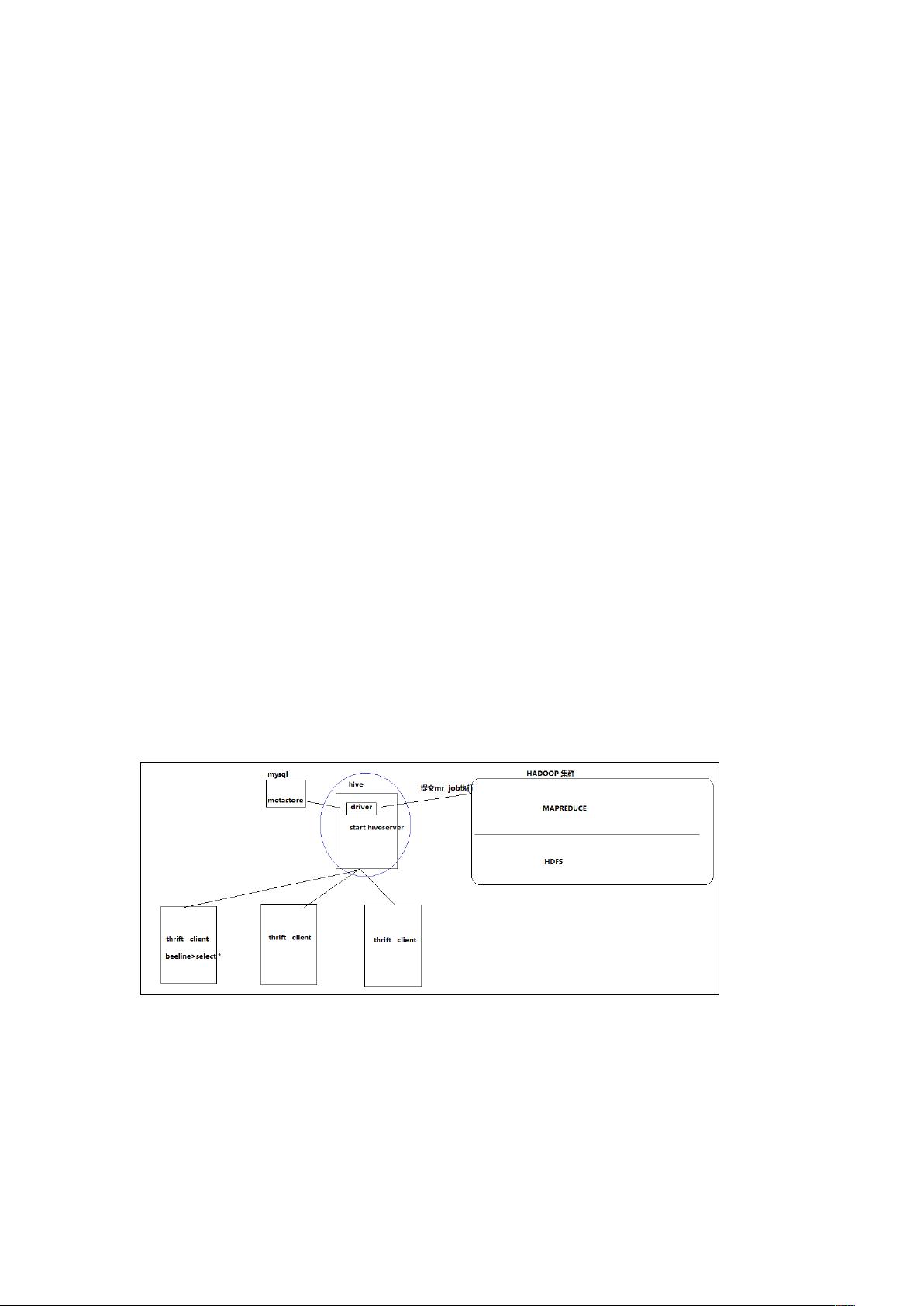
Hive thrift 服务
启动方式,(假如是在 !) 上):
启动为前台:4<!
启动为后台:!/4<!=<<"><!">=<<"><!?
启动成功后,可以在别的节点上用 4" 去连接
方式()
!<4<4"回车,进入 4" 的命令界面

剩余35页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-03-19 上传
2022-10-06 上传
2019-08-27 上传
2020-12-21 上传
2021-05-10 上传

铲屎小仙女
- 粉丝: 1
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







