提升虚拟化网络I/O性能:高效中断合并与虚拟接收端扩展
131 浏览量
更新于2024-08-30
收藏 1.68MB PDF 举报
"这篇研究论文探讨了如何通过有效的中断合并和虚拟接收端扩展来提升网络I/O虚拟化的性能,以解决在云计算中由于高带宽网络连接导致的虚拟化性能下降问题。"
在云计算领域,虚拟化技术是一项至关重要的技术,它使得大量虚拟机(VMs)能够透明地提供服务,如实时迁移、高可用性和快速检查点功能。通过虚拟化,工作负载可以迅速部署并在物理机器上扩展虚拟机,从而实现快速响应。然而,尤其是在网络I/O方面,虚拟化技术在处理高速网络连接时会遇到显著的性能瓶颈。
论文首先分析了网络I/O虚拟化面临的性能挑战,并指出了两个主要问题:一是传统的网络I/O虚拟化会导致大量的虚拟中断传递到客户虚拟机,这增加了处理中断的开销;二是后端驱动程序未能充分利用底层多核处理器的计算资源。这两个问题共同制约了网络I/O的效率,特别是在高负载和高并发的云环境里。
为了解决这些问题,论文提出了两项优化方法。一是高效的中断合并(Interrupt Coalescing),这是一种技术,通过将多个中断合并成一个,减少对虚拟机的打扰,降低中断处理的频率,从而提高整体性能。这种方法旨在减少不必要的中断处理,减轻虚拟机的负担,尤其是当网络流量较大时,可以显著减少处理中断的时间。
二是虚拟接收端扩展(Virtual Receive-Side Scaling,vRSS),这是对传统接收端扩展(Receive-Side Scaling,RSS)的一种扩展,RSS是将网络数据包的处理分发到多核处理器的不同核心上,以实现并行处理。vRSS则是在虚拟化环境中实现这一功能,使得多核处理器的每个核心都能有效地处理来自不同网络连接的数据包,进一步提高了网络吞吐量和处理能力。
结合这两项优化,论文提出的方案旨在提高虚拟化环境中的网络性能,确保在网络I/O虚拟化中能有效利用硬件资源,尤其是在处理高速网络连接时,降低性能损失,提升云服务的响应速度和整体效率。这将对云数据中心的运营和用户体验产生积极影响,使得云服务能够更高效、更稳定地运行。
kernel, can reduce the overhead of receiving packet by
deferring the incoming message handling until a given
threshold is reached.
When a packet arrives, the physical network interface
card (NIC) sends a physical interrupt to the processor and
that is forwarded to the virtual processor of Domain 0. The
NIC driver (native driver in Domain 0) is activated to
receive the packet and send it to the virtual switch, which
dispatches the packet to the corresponding back-end driver.
Once a back-end driver receives the packet, it puts a request
in the shared ring to find an available guest buffer, and then
copies the packet to it. It then puts a new request in the
shared ring for the inbound packet and notifies the guest
domain to process the request, using a virtual interrupt. The
front-end driver responds to the interrupt and receives the
packets by consuming the requests for inbound packets in
the shared ring.
3NETWORK I/O VIRTUALIZATION CHALLENGES
Although many studies have been done in network I/O
virtualization, they focused on interguest packet movement
improvement to achieve better performance. In this section,
we discuss two major additional challenges: Excessive
virtual interrupts and single-threaded backend drivers.
3.1 Challenge 1: Excessive Virtual Interrupts
Upon processing an inbound packet, the back-end driver
interrupts a guest OS immediately, indicating the packet’s
readiness to the guest OS. Although this scheme achieves the
best response time and handles latency-sensitive workloads
well, it causes excessive virtual interrupts to the guest OS,
and significantly degrades I/O virtualization performance.
In the virtualized environment, virtual interrupt proces-
sing is much more expensive than a physical interrupt.
Unlike the native environment, handling a virtual interrupt
in a guest OS could incur multiple rounds of trap-and-
emulation, depending on what virtual interrupt controller
the guest OS implements. For instance, an I/O advanced
programmable interrupt controller (APIC) masks and
unmasks the servicing interrupt, by programming the I/O
redirection table register. APIC programs the end of
interrupt (EOI) and the task priority register (TPR) for every
interrupt. Any of the above register writes may trigger trap-
and-emulation in the virtualized environment. The cost of a
typical trap-and-emulation of an interrupt controller regis-
ter operation is around 3,000 to 5,000 cycles. As a result, each
virtual interrupt can introduce an additional 10 K cycles,
based on Xentrace measurement on Intel servers. Therefore,
it is important to reduce the virtual interrupt overhead in a
virtualized execution environment.
3.2 Challenge 2: Single-Threaded Back-End Driver
The hypervisor shares the physical NIC among multiple
guests through a back-end driver. However, the centralized
back-end driver, running in a single thread, becomes a
bottleneck as the number of guests goes up, or as the number
of virtual receiving queues in front-end drivers increases.
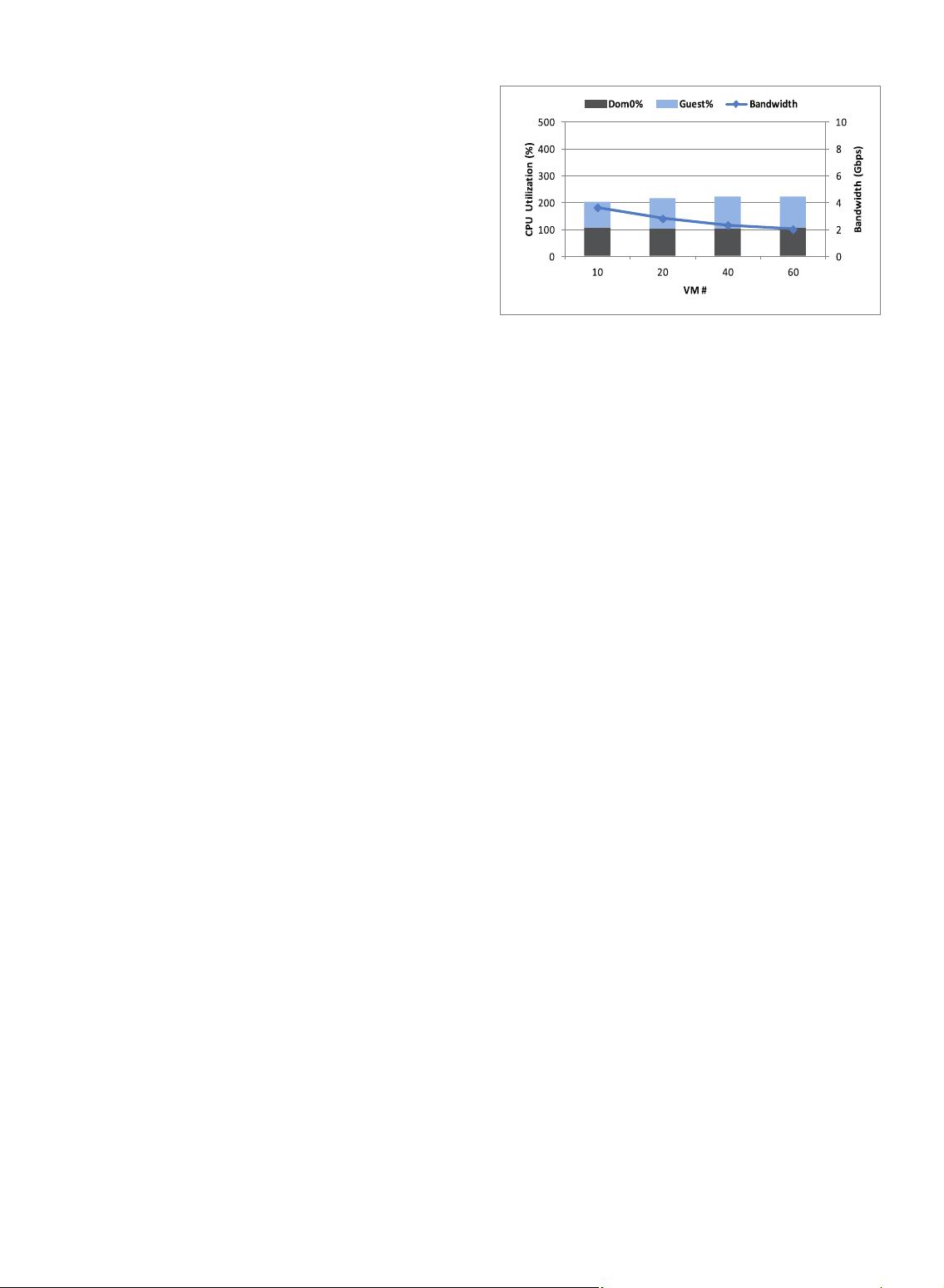
Fig. 2 illustrates the network I/O virtualization scalability
analysis in our 10 Gbps network environment (see the
configuration in Section 5). It points out that when the single-
threaded back-end driver services multiple guests, it
saturates the virtual CPU. That is because the virtual
interrupts delivered to Domain 0 target virtual CPU0, which
is saturated in the presence of high-speed input, no matter
how many other idle CPUs Domain 0 has. This inefficiency
of resource exploitation becomes a bottleneck. In addition, as
the number of VMs keeps increasing, the throughput drops
further due to the increased overheads of context switches
among VMs. Overall, our experiment reveals that the
networking performance is very poor (all under 4 Gbps)
with a single-threaded back-end driver, and suffers from
significant performance degradation as the number of VMs
increases. Therefore, existing network I/O virtualization
suffers from performance and scalability issues.
4NETWORK I/O VIRTUALIZATION OPTIMIZATIONS
To cope with the previously stated challenges, we present
our optimizations in this section. Section 4.1 elaborates
virtual interrupt coalescing (VIC), and Section 4.2 elaborates
the multimode VIC for dynamic network workl oad,
Section 4.3 covers multilayer interrupt coalescing, and in
Section 4.4, we present a virtual RSS.
4.1 Virtual Interrupt Coalescing
Interrupt coalescing [1] is a technology to throttle interrupt
frequency, so as to achieve the best tradeoff between
performance and latency. As network connection speed
goes up, rate of interrupts generated by packet arrivals is
increased. For instance, a 10 Gbps network can receive up to
0.8 million packets per second with maximum size of
1.5 KB, and it may have a 10 higher frequency for small
packets size (minimum to 50 B). To reduce the number of
interrupts, modern NICs coalesce interrupts to achieve
better performance while maintaining the worst case
latency [7] in the physical layer.
Although a NIC can reduce physical interrupt frequency,
it has a limited frequency control range, and the virtual
interrupt rate is still a heavy system overhead. As
mentioned in Section 3.1, virtual interrupt handling is very
expensive. Therefore, we enhance Xen network I/O
virtualization by coalescing virtual interrupts to reduce
CPU cycle usage. As depicted in Fig. 3, virtual interrupts
can be coalesced by either the driver domain or guest
domain. Consequently, there are two implementations:
back-end VIC (BEC) and front-end VIC (FEC). BEC moderates
GUAN ET AL.: PERFORMANCE ENH ANCEMENT FOR NETWORK I/O VIRTUALIZATION WITH EFFICIENT INTERRUPT COALESCING AND... 3
Fig. 2. Network I/O virtualization scalability.
剩余10页未读,继续阅读
119 浏览量
2021-09-23 上传
2023-07-21 上传
2023-04-03 上传
2023-07-25 上传
2023-06-08 上传
2023-03-27 上传
2023-03-27 上传
2023-04-04 上传

weixin_38519849
- 粉丝: 5
- 资源: 973
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
