分治策略:从归并排序到最近点对问题
版权申诉
106 浏览量
更新于2024-07-08
收藏 8.95MB PDF 举报
"这篇文档是关于分治算法(Divide and Conquer)的讲座幻灯片,由Kevin Wayne创建并更新于2005年。主要内容涵盖了归并排序(Mergesort)、逆序对计数(Counting Inversions)、随机化快速排序(Randomized Quicksort)、中位数选择(Median Selection)以及最近点对问题(Closest Pair of Points)等。这些是分治算法的经典应用实例,旨在讲解如何通过分解问题、递归解决子问题,然后将结果合并来达到高效解题的目的。"
分治算法是一种重要的计算机科学中的算法设计策略,其基本思想是将一个复杂的问题分解成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这种策略通常能够将时间复杂度从原始的线性平方级别降低到对数级别的效率。
1. **归并排序(Mergesort)**:归并排序是一种典型的分治算法,它将一个数组分为两半,分别对两部分进行排序,然后将两个已排序的子数组合并为一个有序数组。归并排序的时间复杂度为O(n log n),空间复杂度为O(n)。
2. **逆序对计数(Counting Inversions)**:在排序数组中,如果一个元素出现在另一个元素之前,但其值较大,就形成了一个逆序对。计算逆序对的数量可以帮助评估数组的排序程度。逆序对问题也可以使用分治策略解决,时间复杂度可以达到O(n log n)。
3. **随机化快速排序(Randomized Quicksort)**:快速排序是另一种高效的排序算法,通常使用“分区”操作将数组分为两部分,一部分的所有元素都小于另一部分。随机化版本的快速排序在最坏情况下也能保持O(n log n)的时间复杂度。
4. **中位数选择(Median Selection)**:在未排序的数组中找到中间值(中位数)。分治方法可以用于选择第k小(或大)的元素,包括中位数。中位数问题的解决方案如“快速选择”算法,其平均时间复杂度为O(n)。
5. **最近点对问题(Closest Pair of Points)**:在二维平面上找到距离最近的两个点。经典的分治算法,如“平面分割”方法,可以在O(n log n)时间内解决此问题。
这些内容在计算机科学教育中占有重要地位,特别是对于算法设计和分析课程,因为它们展示了如何通过分治策略解决复杂问题,并且是理解和实现高级数据结构与算法的基础。通过学习和掌握这些算法,开发者能够编写更高效、更优化的代码,从而在实际应用中提高程序性能。
Sorting lower bound
Theorem. Any deterministic compare-based sorting algorithm must make
Ω(n log n) compares in the worst-case.
!
Pf. [ information theoretic ]
Assume array consists of n distinct values a
1
through a
n
.
Worst-case number of compares = height h of pruned comparison tree.
Binary tree of height h has ≤ 2
h
leaves.
n! different orderings ⇒ n! reachable leaves.!
!
!
!
!
!
!
!
Note. Lower bound can be extended to include randomized algorithms.
17
2
h
≥ # leaves ≥ n !
⇒ h ≥ log
2
(n!)
≥ n log
2
n − n / ln 2 ▪
Stirling’s formula
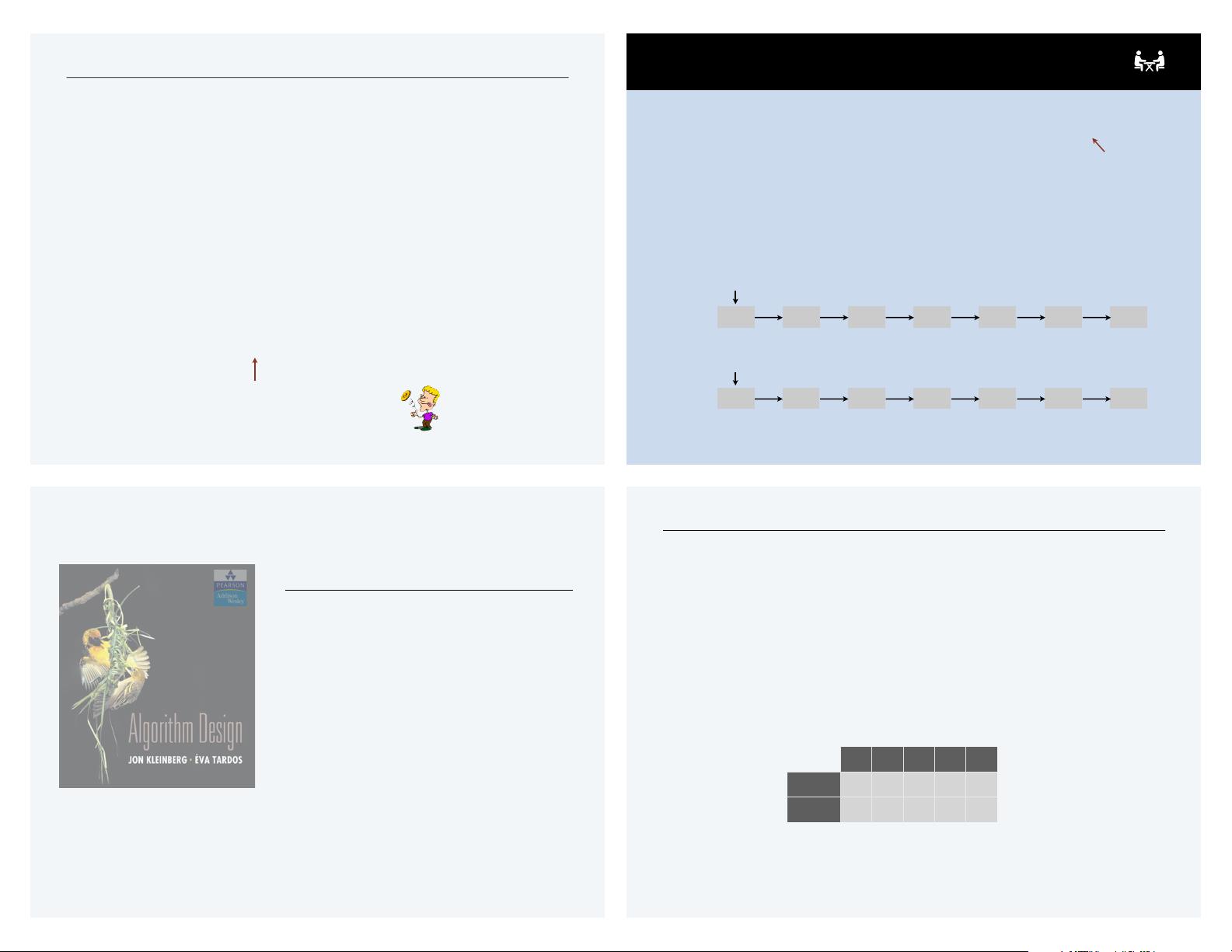
SHUFFLING A LINKED LIST
Problem. Given a singly linked list, rearrange its nodes uniformly at random.
Assumption. Access to a perfect random-number generator.
!
Performance. O(n log n) time, O(log n) extra space.
18
L
3♣
4♣
5♣
6♣
2♣
7♣
null
L
6♣
2♣
7♣
3♣
5♣
4♣
null
input
shu#ed
all n! permutations
equally likely
5. DIVIDE AND CONQUER
‣
mergesort
‣
counting inversions
‣
randomized quicksort
‣
median and selection
‣
closest pair of points
SECTION 5.3
Counting inversions
Music site tries to match your song preferences with others.
You rank n songs.
Music site consults database to find people with similar tastes.!
Similarity metric: number of inversions between two rankings.
My rank: 1, 2, …, n.
Your rank: a
1
, a
2
, …, a
n
.
Songs i and j are inverted if i < j, but a
i
> a
j
.
!
!
!
!
!
!
!
Brute force: check all Θ(n
2
) pairs.
20
A
B
C
D
E
me
1
2
3
4
5
you
1
3
4
2
5
2 inversions: 3-2, 4-2
剩余20页未读,继续阅读
2021-11-27 上传
2020-05-27 上传
2023-05-25 上传
2023-03-31 上传
2023-03-31 上传
2023-05-21 上传
2023-05-25 上传
2023-06-03 上传
2023-05-24 上传
2023-07-12 上传

码上富贵
- 粉丝: 1w+
- 资源: 177
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
