机器学习模型评估入门指南
需积分: 12 41 浏览量
更新于2024-07-17
收藏 3.65MB PDF 举报
"《Evaluating Machine Learning Models》是一本由Alice Zheng编写的初学者指南,专注于介绍机器学习模型评估的关键概念和常见陷阱。本书由O'Reilly Media, Inc.出版,旨在帮助读者理解如何在数据科学和业务基础之间找到交集,并融合应用。在Strata + Hadoop World这一全球数据专业人士的盛会上,读者可以学习到数据技术的商业应用,通过培训和深入教程提升新技能,并与国际数据社区建立联系。"
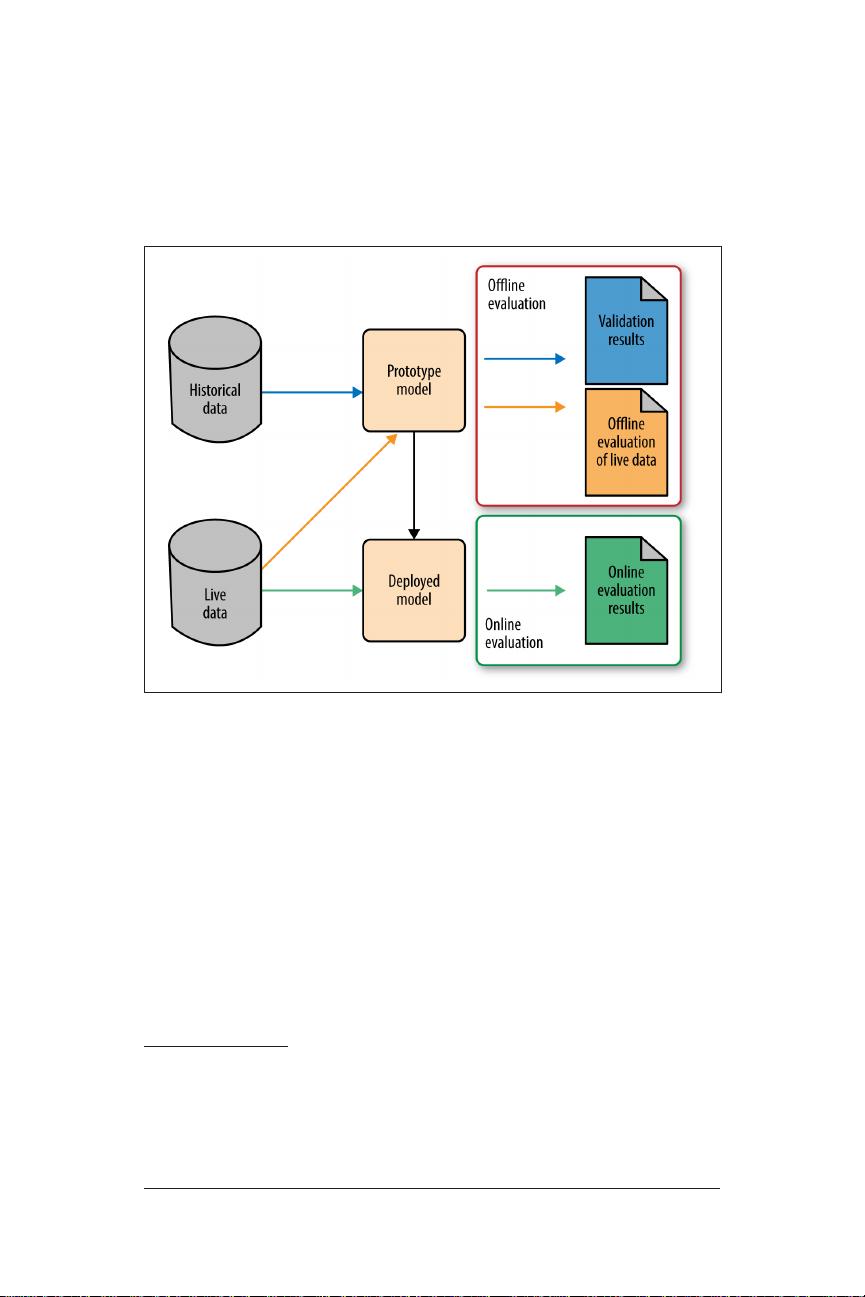
在机器学习领域,评估模型的性能是至关重要的步骤,因为它决定了模型在实际问题中的表现。以下是关于机器学习模型评估的一些关键知识点:
1. **准确度(Accuracy)**:最直观的评估指标,但并不总是适用,特别是在类别不平衡的数据集中,高准确度可能掩盖模型的不足。
2. **精确率(Precision)**和**召回率(Recall)**:精确率衡量的是预测为正类别的样本中真正为正的比例,召回率则表示所有真正正类别被正确预测的比例。这两个指标常用于需要权衡假阳性(False Positives)和假阴性(False Negatives)的情况。
3. **F1分数(F1 Score)**:综合考虑精确率和召回率的指标,是它们的调和平均值,适用于类别不平衡的问题。
4. **ROC曲线(Receiver Operating Characteristic Curve)**和**AUC值(Area Under the Curve)**:ROC曲线展示了不同阈值下真阳性率和假阳性率的关系,AUC值是ROC曲线下的面积,用于衡量模型区分正负类别的能力。
5. **混淆矩阵(Confusion Matrix)**:列出模型预测的所有结果,包括真正例、假正例、真反例和假反例,可用于分析模型的分类性能。
6. **交叉验证(Cross-validation)**:为了减少过拟合风险,通过将数据集划分为训练集和测试集多遍,评估模型在未见过的数据上的表现。
7. **泛化误差(Generalization Error)**:模型在新数据上的预期误差,是我们真正关心的指标,通过验证集或测试集评估。
8. **模型复杂度(Model Complexity)**:过复杂的模型可能导致过拟合,而过于简单的模型可能导致欠拟合。选择合适的模型复杂度是优化模型性能的关键。
9. **正则化(Regularization)**:通过添加惩罚项来防止模型过度依赖训练数据,如L1正则化(Lasso Regression)和L2正则化(Ridge Regression)。
10. **调参(Hyperparameter Tuning)**:通过网格搜索、随机搜索等方法找到最优的超参数组合,以提高模型性能。
11. **模型比较(Model Comparison)**:使用相同的评估标准对比不同模型,选择最佳模型进行部署。
Alice Zheng的书详细介绍了这些概念,并警告初学者们避免常见的评估陷阱,例如过分依赖单一评估指标、忽略数据质量以及错误地使用验证策略。通过阅读此书,读者不仅可以了解理论知识,还能掌握如何在实践中有效地评估和改进机器学习模型。


2018-03-29 上传
2016-12-24 上传
2017-03-08 上传
2023-04-04 上传
2023-03-30 上传
2023-05-03 上传
2023-04-05 上传
2024-06-26 上传
2023-03-31 上传

chunyangsuhao
- 粉丝: 102
- 资源: 7382
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
