Scrapy入门:高效构建古诗文爬虫框架
119 浏览量
更新于2024-08-31
收藏 892KB PDF 举报
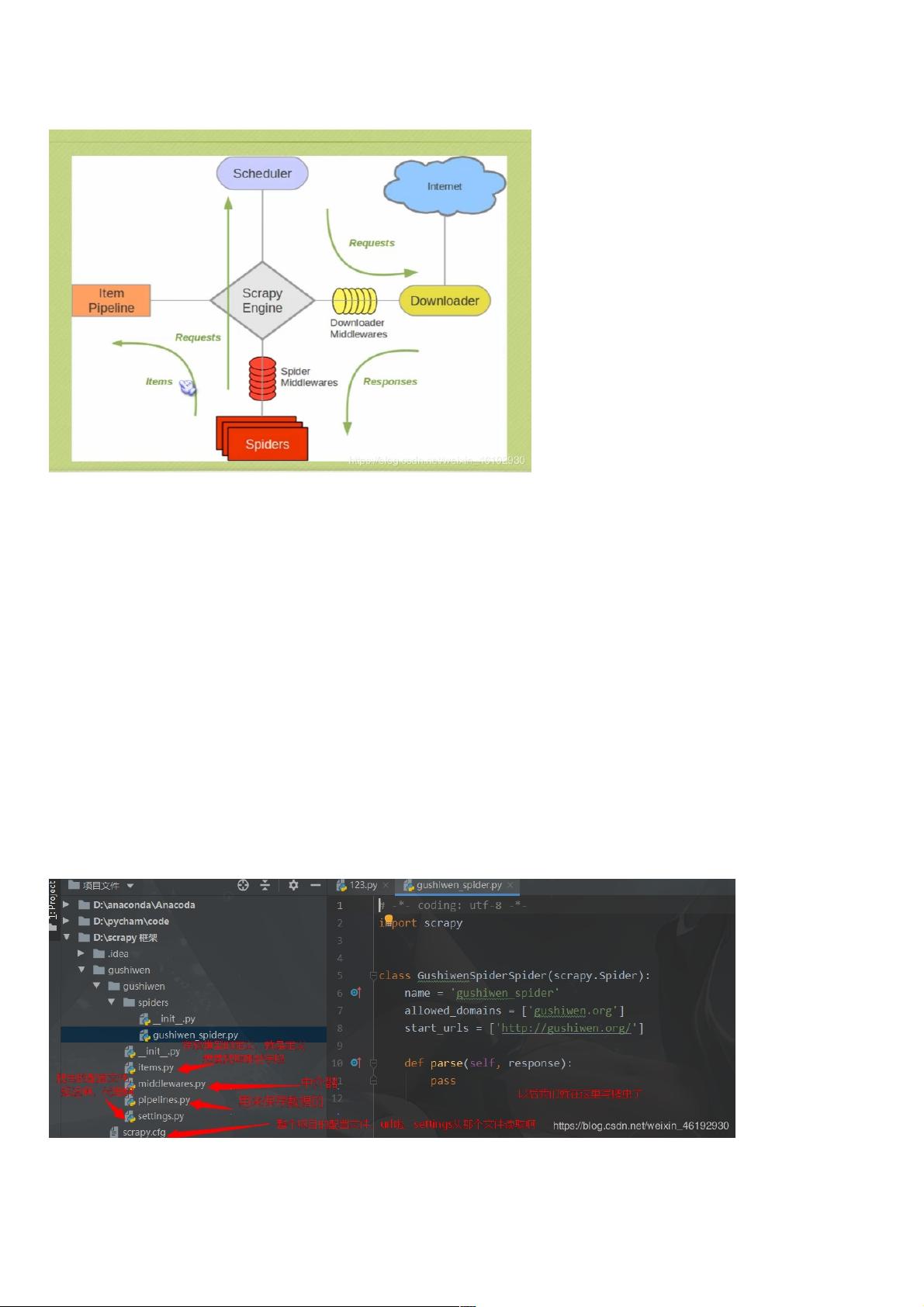
Scrapy是一个强大的Python网络爬虫框架,专为高效、可扩展的网页抓取而设计。它简化了编写爬虫的过程,使得开发者能够专注于数据提取和处理,而不是底层的网络通信和数据管理。Scrapy的核心组成部分包括Scrapy Engine、Spider、Scheduler、Downloader和Item Pipeline。
Scrapy Engine是框架的心脏,它负责管理和协调整个爬虫的工作流程。当一个Spider开始运行时,它会向Engine提交初始的抓取请求。Engine充当了各个组件间的通信桥梁,接收请求,调度URL的抓取顺序,确保去重,并将数据传递给相应的模块。
Spider是Scrapy的核心逻辑部分,它定义了要爬取哪些页面和如何解析数据。Spiders从特定的网站开始,通过指定规则(例如XPath或CSS选择器)提取所需的信息,形成实体(Item),并可能包含新的URL,引导Scrapy进行递归抓取。
Scheduler是Scrapy的重要组成部分,它扮演一个URL队列的角色,负责组织和优先级排序待抓取的链接,避免重复请求,并确保爬虫按预设策略或动态策略执行。
Downloader是实际进行网络下载的组件,它接收Engine转发的下载请求,从互联网上下载网页内容,然后将响应传递给Engine。
Item Pipeline则是数据处理的关键环节,开发者可以自定义如何存储、清洗和转换从Spider获取的Items,如数据库、CSV文件或API接口,实现数据持久化。
下载中间件(Downloader Middlewares)和Spider中间件(Spider Middlewares)则是可扩展的插件,允许开发者添加额外的功能,如代理服务器管理、请求头定制等,以增强爬虫的灵活性和适应性。
Scrapy的数据流动过程遵循一种线性的模式:首先,Spider提供初始URL,Scheduler根据策略调度请求;接着,下载器获取并下载网页;下载完成后,响应被送至Spider进行解析,生成新的请求和Items;最后,Items通过Item Pipeline进行处理,整个流程由Scrapy Engine统一管理。
Scrapy通过模块化的结构和灵活的扩展性,降低了爬虫开发的复杂度,使得开发者能够快速构建高性能、可维护的网络爬虫,从而获取和分析网络上的大量信息。
Scrapy入门:爬取古诗文入门:爬取古诗文
Scrapy框架介绍框架介绍
写一个爬虫需要做很多事情,比如:发送请求,数据解析,数据存储,反爬虫机制(更换代理,设置请求头等),异步请求。这些工作如果每次都要从头开始,使很浪费时间得。
scrapy 把一些基础的东西都封装了,在它上面写爬虫可以更加高效。
Scrapy Engine(引擎) :框架的核心,负责在各组件之间进行通信,传递数据等。
Spider(爬虫):发送那个需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据在发送给爬虫,爬虫就去解析想要的数据。用于从特定的网页中提取自己需要的信息,即所谓
的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。这个部分使我们开发者自己写的,因为要爬取的链接,页面中的数据都是自己来决定的。
Scheduler(调度器): 复制接受引擎发送过来的请求,并按照一定的方式去进行排列和整理,负责调度请求的顺序等。就是一个 url 排序队列,有他决定下一个网址是啥,同时去
重。
Downloader(下载器): 复制接受引擎传过来的下载请求,然后去网络上下载相应的数据在交还给引擎。
item Pipeline(管道): 负责将Spider 传递过来的数据(实体items) 进行保存,具体保持在哪有开发者决定
Downloader Middlewares(下载中间件): 可以扩展下载器和引擎之间的通信功能的中间件。加个代理之类的
Spider Middlewares(spider 中间件): 可以扩展引擎和爬虫之间通信功能的中间件
scrapy 中的数据流是由中间的执行引擎控制,大概过程如下:
从spider 中获取第一个需要爬取的url
使用 scheduler 调度 requests 并向 scheduler 请求下一个要爬取的url
10.scheduler返回下一个需要爬取的url
执行引擎将url 通过downloader middiewares 转发给downloader
一旦页面下载完毕,下载器生成一个该页面的 responses 并发送给执行引擎
引擎从downloader中接受 responses 并通过spider middlewares 发送 spider 处理
spiders 处理responses 并返回爬取到的 items 及新的requests 给引擎。
执行引擎将爬取道德items给items pipeline 然后将requests 给scheduler
从第一部开始重复这个流程,直到scheduler中没有更多的url,
。。。啥东西。。。在以后的案例中慢慢了解吧。。。
创建项目创建项目
创建项目:通过命令来实现,首先进入到你想把这个项目想存放的目录,然后使用scrapy startproject gushiwen
创建爬虫:scrapy genspider[爬虫名][爬虫作用的域名] scrapy genspider gushiwen_spider gushiwen.org
是中间件不是中介器哈哈哈,,,,,,,
案例:爬取古诗文网案例:爬取古诗文网
一股文学的味道
– 首先来看一下首先来看一下 settings.py 这个项目配置文件这个项目配置文件
BOT_NAME:项目名
USER_AGENT:默认是注释的,这个东西非常重要,如果不写很容易被判断为电脑,简单点写一个Mozilla/5.0即可
下载后可阅读完整内容,剩余3页未读,立即下载
2020-09-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-03-23 上传
点击了解资源详情

weixin_38637998
- 粉丝: 10
- 资源: 916
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
