Storm实时计算框架详解
需积分: 10 66 浏览量
更新于2024-07-21
收藏 2.03MB PDF 举报
"这篇文章是关于Storm实时数据流处理框架的学习总结,由作者严亮在2015年七月编写。Storm是一个免费开源的系统,它提供了分布式和高容错的实时计算能力,常用于实时分析、在线机器学习、持续计算等场景。与Hadoop批处理不同,Storm专注于实时数据处理,支持热部署,允许即时上线或下线应用程序,并且可以用多种编程语言(如Clojure、Java、Ruby和Python)进行开发,通过实现简单的通信协议可支持更多语言。Storm具有内置的容错机制和水平扩展性,可以处理大规模数据处理任务。文章详细介绍了Storm的基本概念、集群结构、工作原理和分组方式,如ShuffleGrouping和FieldsGrouping。"
本文详细探讨了Apache Storm,一个强大的实时计算系统,旨在简化持续不断的流计算。Storm的核心特性包括其免费开源、分布式和高容错的特性,这使得它成为实时数据分析和处理的理想选择,尤其适用于那些Hadoop批处理无法胜任的场景。与Hadoop相比,Storm在保证数据可靠性的同时提供实时响应,确保所有输入数据都能得到及时处理。
Storm作为一个服务框架,支持热部署,这意味着应用程序可以随时在线添加或移除,无需停机,这对于需要持续运行的实时应用至关重要。它支持多种编程语言,包括Clojure、Java、Ruby和Python,并且扩展性极强,开发者只需要实现一个简单的通信协议就能让Storm支持其他编程语言。
在集群结构方面,Storm通过分布式计算实现了高度的可扩展性,能够在多个线程、进程和服务器之间并行处理大量数据。此外,Storm具有内置的容错机制,能够自动管理工作进程和节点的故障,确保系统的稳定运行。
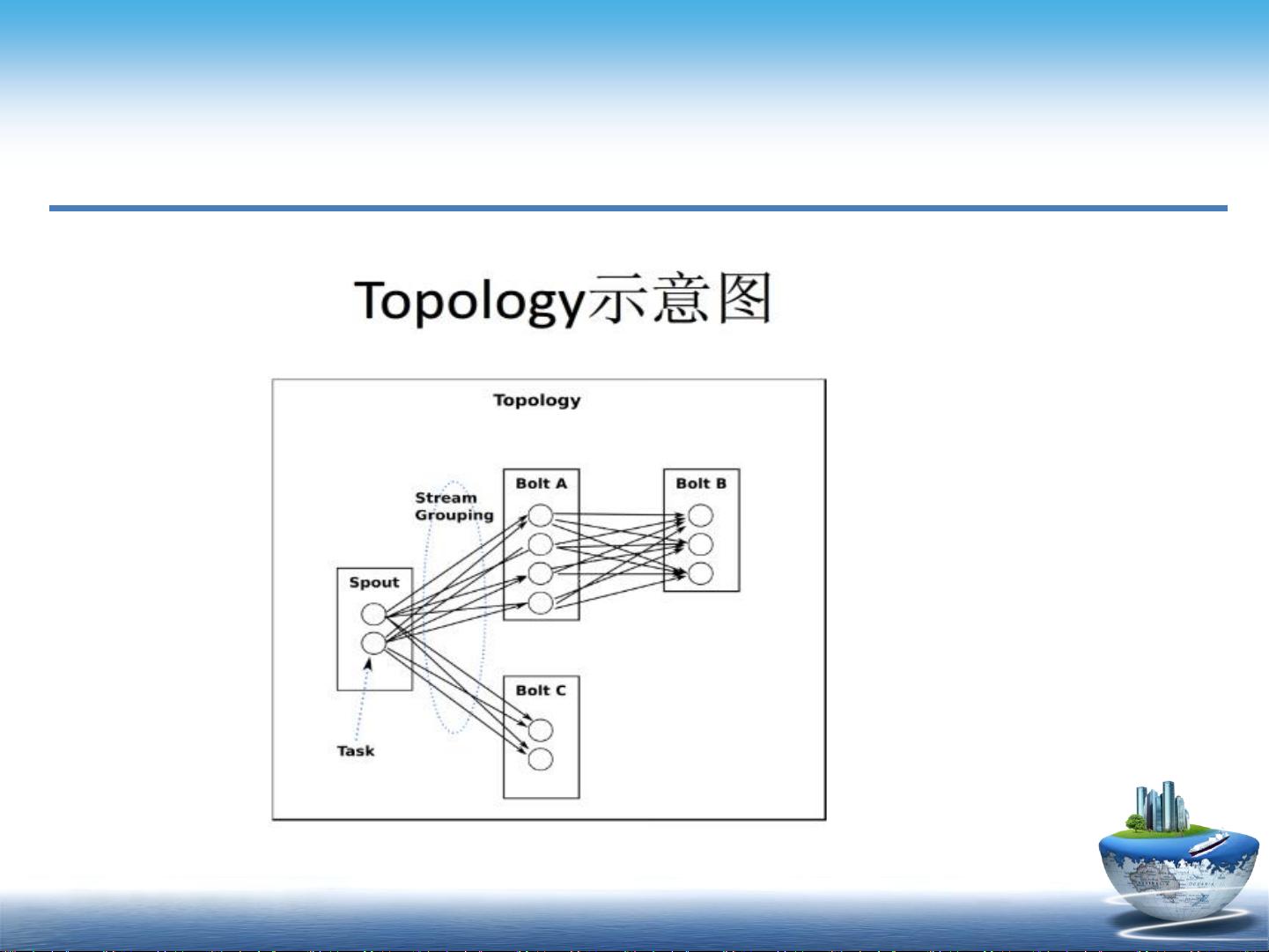
Storm的工作原理涉及Spout和Bolt的概念,Spout负责数据的生成,而Bolt则执行具体的数据处理任务。通过不同的分组策略,如ShuffleGrouping(随机分组)和FieldsGrouping(按字段分组),Storm能够灵活地将数据流分配给不同的处理组件,以优化计算效率和结果准确性。
例如,ShuffleGrouping将流中的数据随机分配到下游Bolt的各个实例,保证负载均衡;而FieldsGrouping允许根据特定字段对数据进行聚合,这样相同字段值的数据会被发送到同一个Bolt实例,便于进行字段级别的聚合操作。
Storm为实时数据流处理提供了一个强大而灵活的平台,它不仅能够处理大规模数据,而且具有高度的可用性和可扩展性,适合在各种实时计算需求的场景中使用。通过深入理解和熟练掌握Storm,开发者能够构建出高效、可靠的实时数据处理系统。


2023-11-16 上传
2024-05-29 上传
2023-06-12 上传
2023-09-10 上传
2023-09-13 上传
2023-07-07 上传
2023-04-02 上传
2023-06-03 上传

crosslab
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
