

for x in vec2.keys():
# tfidf_title_vectorizer.vocabulary_ it contains all the words in the corpus
# tfidf_title_features[doc_id, index_of_word_in_corpus] will give the tfidf value of wo
rd in given document (doc_id)
if x in tfidf_title_vectorizer.vocabulary_:
labels.append(tfidf_title_features[doc_id, tfidf_title_vectorizer.vocabulary_[x]])
else:
labels.append(0)
elif model == 'idf':
labels = []
for x in vec2.keys():
# idf_title_vectorizer.vocabulary_ it contains all the words in the corpus
# idf_title_features[doc_id, index_of_word_in_corpus] will give the idf value of word
in given document (doc_id)
if x in idf_title_vectorizer.vocabulary_:
labels.append(idf_title_features[doc_id, idf_title_vectorizer.vocabulary_[x]])
else:
labels.append(0)
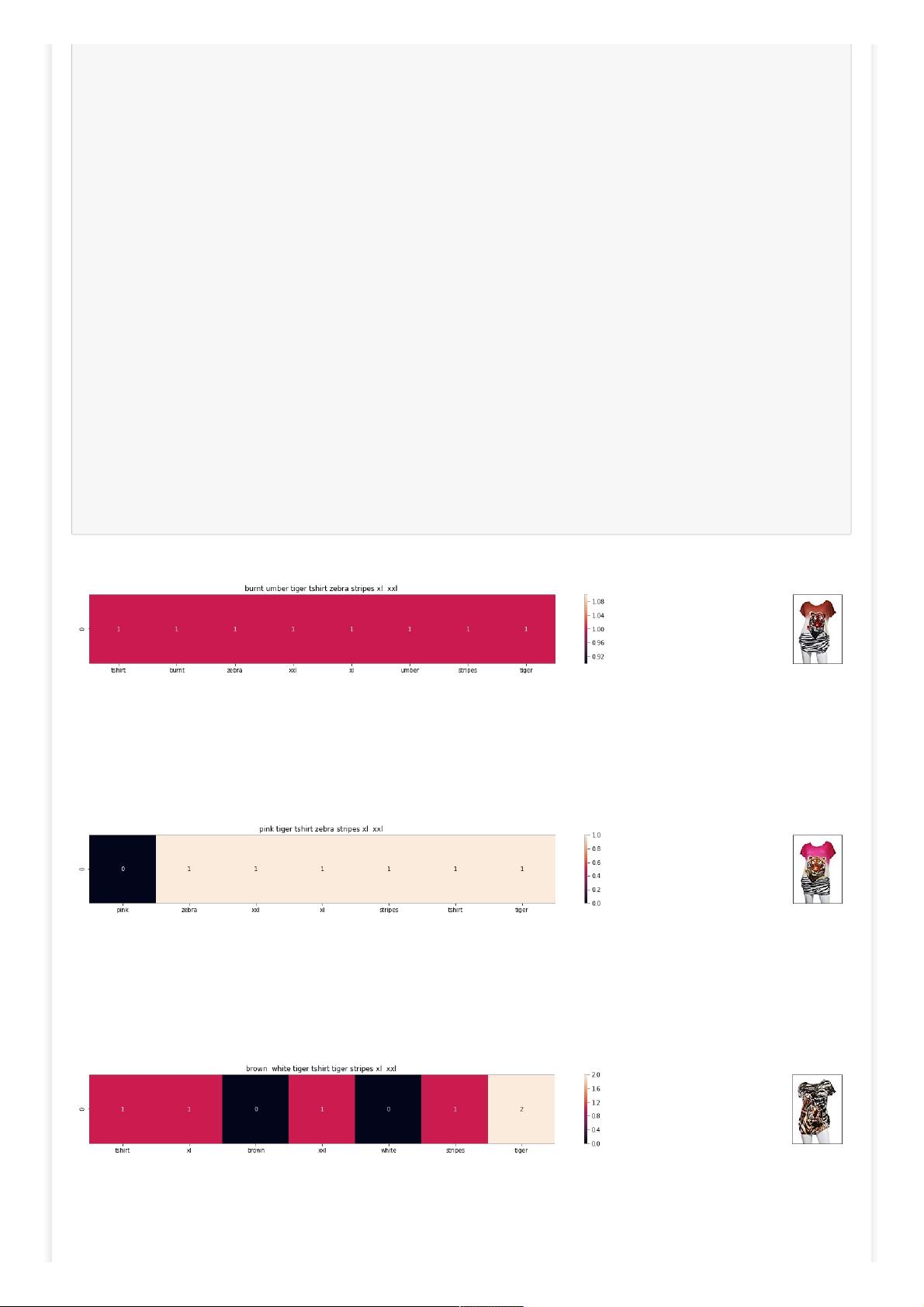
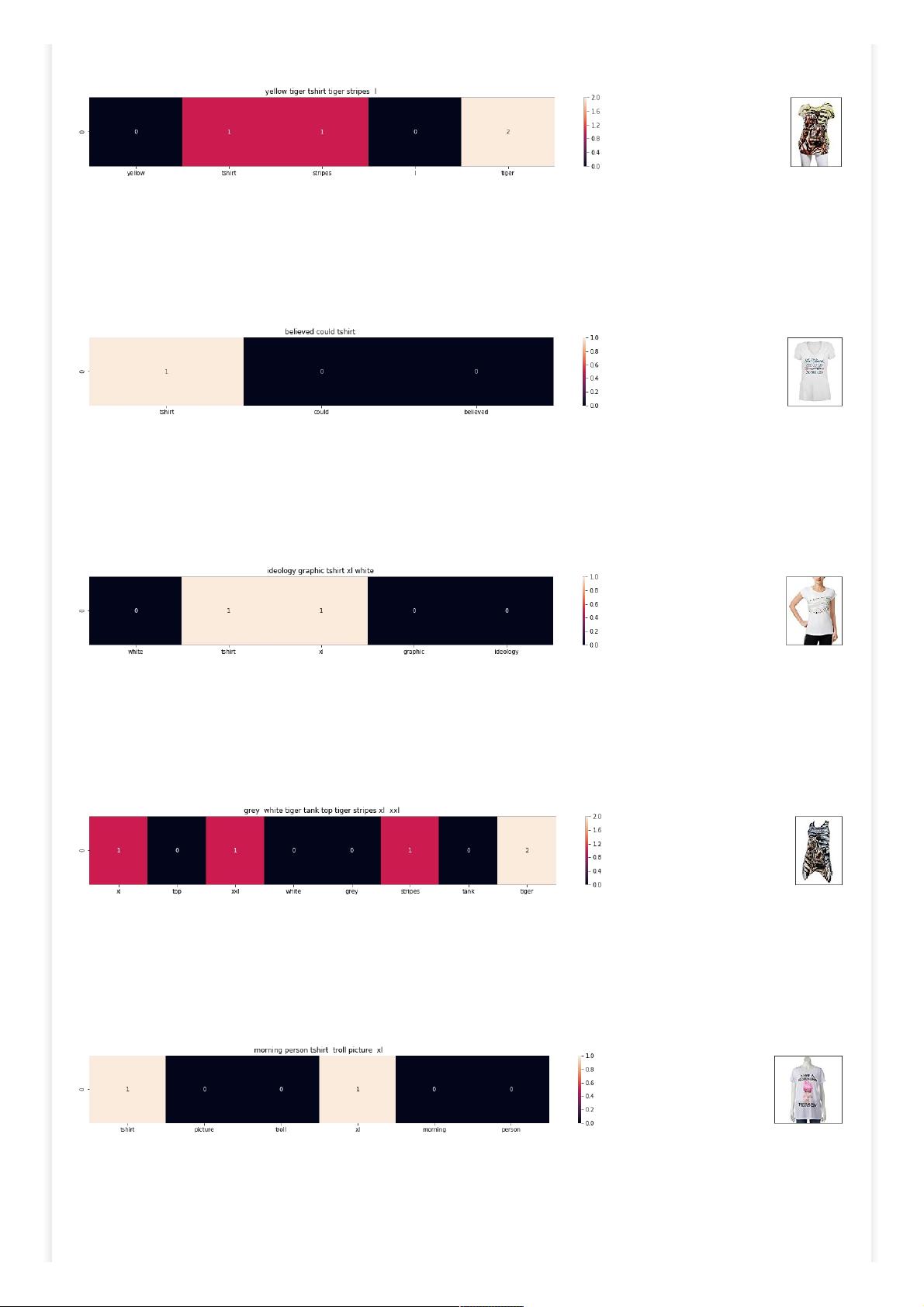
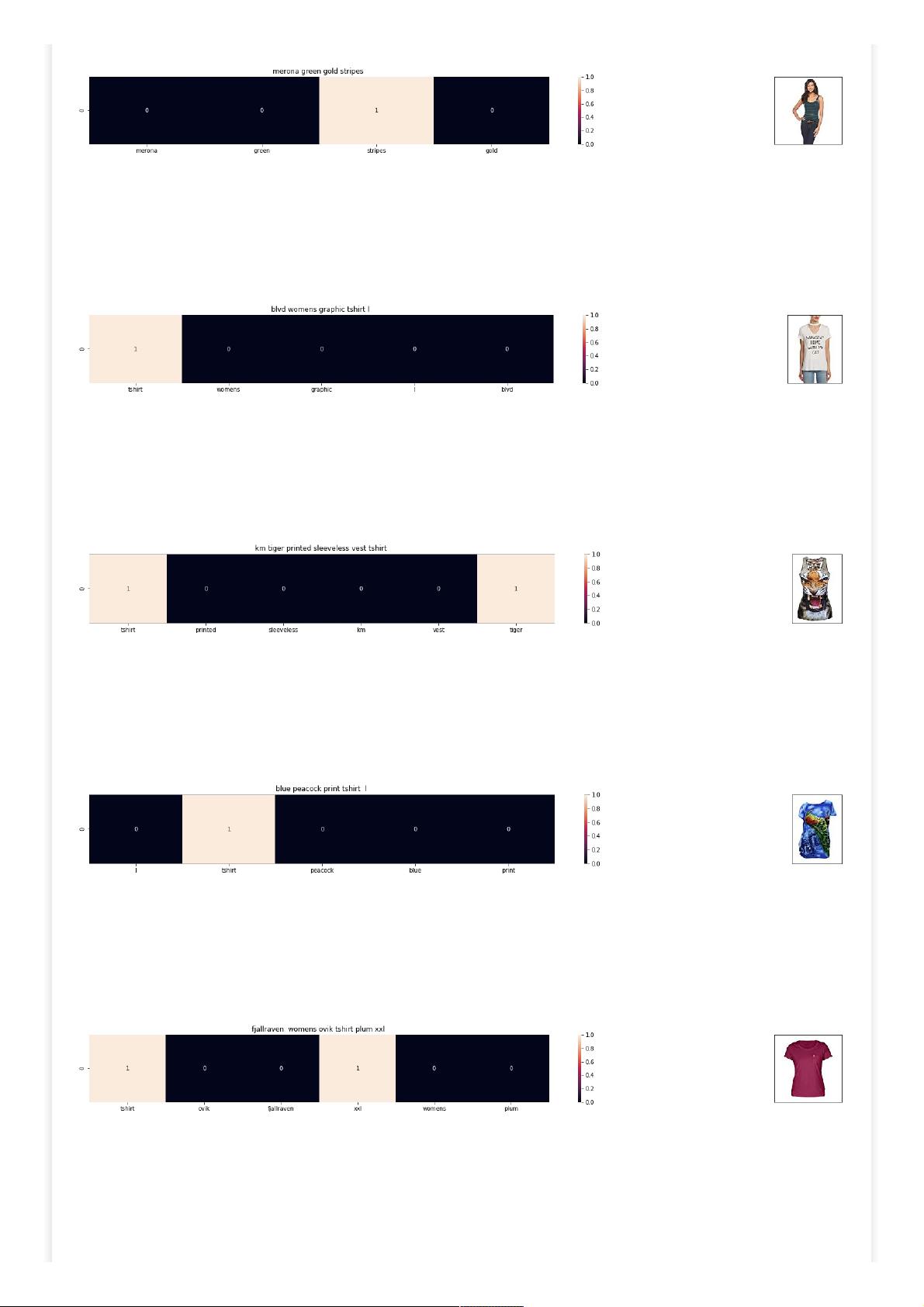
plot_heatmap(keys, values, labels, url, text)
# this function gets a list of wrods along with the frequency of each
# word given "text"
def text_to_vector(text):
word = re.compile(r'\w+')
words = word.findall(text)
# words stores list of all words in given string, you can try 'words = text.split()' this will
also gives same result
return Counter(words) # Counter counts the occurence of each word in list, it returns dict
type object {word1:count}
def get_result(doc_id, content_a, content_b, url, model):
text1 = content_a
text2 = content_b
# vector1 = dict{word11:#count, word12:#count, etc.}
vector1 = text_to_vector(text1)
# vector1 = dict{word21:#count, word22:#count, etc.}
vector2 = text_to_vector(text2)
plot_heatmap_image(doc_id, vector1, vector2, url, text2, model)
[8.2] Bag of Words (BoW) on product titles.
In [117]:
from sklearn.feature_extraction.text import CountVectorizer
title_vectorizer = CountVectorizer()
title_features = title_vectorizer.fit_transform(data['title'])
title_features.get_shape() # get number of rows and columns in feature matrix.
# title_features.shape = #data_points * #words_in_corpus
# CountVectorizer().fit_transform(corpus) returns
# the a sparase matrix of dimensions #data_points * #words_in_corpus
# What is a sparse vector?
# title_features[doc_id, index_of_word_in_corpus] = number of times the word occured in that doc
In [118]:
def bag_of_words_model(doc_id, num_results):
# doc_id: apparel's id in given corpus
# pairwise_dist will store the distance from given input apparel to all remaining apparels
# the metric we used here is cosine, the coside distance is mesured as K(X, Y) = <X, Y> / (||X
||*||Y||)
Out[117]:
(16042, 12609)

剩余91页未读,继续阅读

sambalshikhar
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


