C++AMP实战:GPU上的高效并行计算
64 浏览量
更新于2024-08-28
收藏 311KB PDF 举报
“遇见C++AMP:在GPU上做并行计算”
C++AMP,全称为Accelerated Massive Parallelism,是C++的一个库,用于利用图形处理单元(GPU)的并行计算能力,尤其是在大规模并行任务中。在CPU上,多核技术通常提供双核到四核的物理核心,通过超线程技术可以模拟出更多的逻辑核心。然而,与之相比,GPU拥有数量庞大的核心,例如中端的NVIDIA GTX 560SE具有288个核心,而高端的NVIDIA GTX 690则有惊人的3072个核心,这使得GPU在并行计算方面具有显著优势。
本文将基于之前介绍的C++PPL(Parallel Patterns Library)的概念,深入探讨如何利用C++AMP在GPU上执行并行计算。在C++PPL中,我们学习了如何在CPU上进行并行计算,但C++AMP允许我们将计算任务转移到GPU,充分利用其并行处理能力。对于需要大量并行计算的任务,如计算数组中每个元素的正弦值,GPU的并行处理能力能带来显著的性能提升。
为了在GPU上进行并行计算,我们需要使用C++AMP提供的头文件`amp.h`,它包含了并行计算所需的基本函数和类。同时,`amp_math.h`提供了数学函数,如正弦函数。C++AMP提供两种数学函数版本:`concurrency::fast_math`中的函数适用于单精度浮点数,而`concurrency::precise_math`则同时支持单精度和双精度浮点数。
在实现并行计算正弦值的代码时,需要注意以下几点:
1. **类型转换**:由于不是所有GPU都支持双精度浮点数运算,因此,通常会将浮点数类型从`double`改为`float`。这可以通过修改变量类型或者函数调用来实现。
2. **命名空间冲突**:C++AMP和STL都有名为`array`的类,为了避免混淆,我们需要使用`std::array`来明确表示我们使用的是STL中的容器。
3. **创建`array_view`对象**:在C++AMP中,我们不直接操作GPU内存,而是通过`array_view`对象来访问数据。`array_view`是一个轻量级的视图,它不存储数据,而是引用一个现有的容器,如`std::array`。创建`array_view`时,需要指定元素类型、维度以及实际数据所在的容器。
4. **并行计算**:使用`array_view`和C++AMP的并行算法,如`parallel_for_each`,可以在GPU上对每个元素执行并行操作,例如计算正弦值。
通过这样的方式,我们可以将原本在CPU上的串行计算任务转化为在GPU上的并行计算,显著提高计算效率。C++AMP通过抽象的编程模型简化了GPU编程,使得开发者无需深入了解GPU的底层细节,就能充分利用GPU的并行计算能力,实现高性能的应用程序。
遇见遇见C++AMP:在:在GPU上做并行计算上做并行计算
在《遇见C++ PPL:C++的并行和异步》里,我们介绍了如何使用C++ PPL在CPU上做并行计算,这次,我们会把舞台换成
GPU,介绍如何使用C++ AMP在上面做并行计算。并行计算正弦值
为什么选择在GPU上做并行计算呢?现在的多核CPU一般都是双核或四核的,如果把超线程技术考虑进来,可以把它们看作
四个或八个逻辑核,但现在的GPU动则就上百个核,比如中端的NVIDIA GTX 560 SE就有288个核,顶级的NVIDIA GTX 690
更有多达3072个核,这些超多核(many-core)GPU非常适合大规模并行计算。
接下来,我们将会在《遇见C++ PPL:C++的并行和异步》的基础上,对并行计算正弦值的代码进行一番改造,使之可以在
GPU上运行。如果你没读过那篇文章,我建议你先去读一读它的第一节。此外,本文也假设你对C++ Lambda有所了解,否
则,我建议你先去读一读《遇见C++ Lambda》。
并行计算正弦值
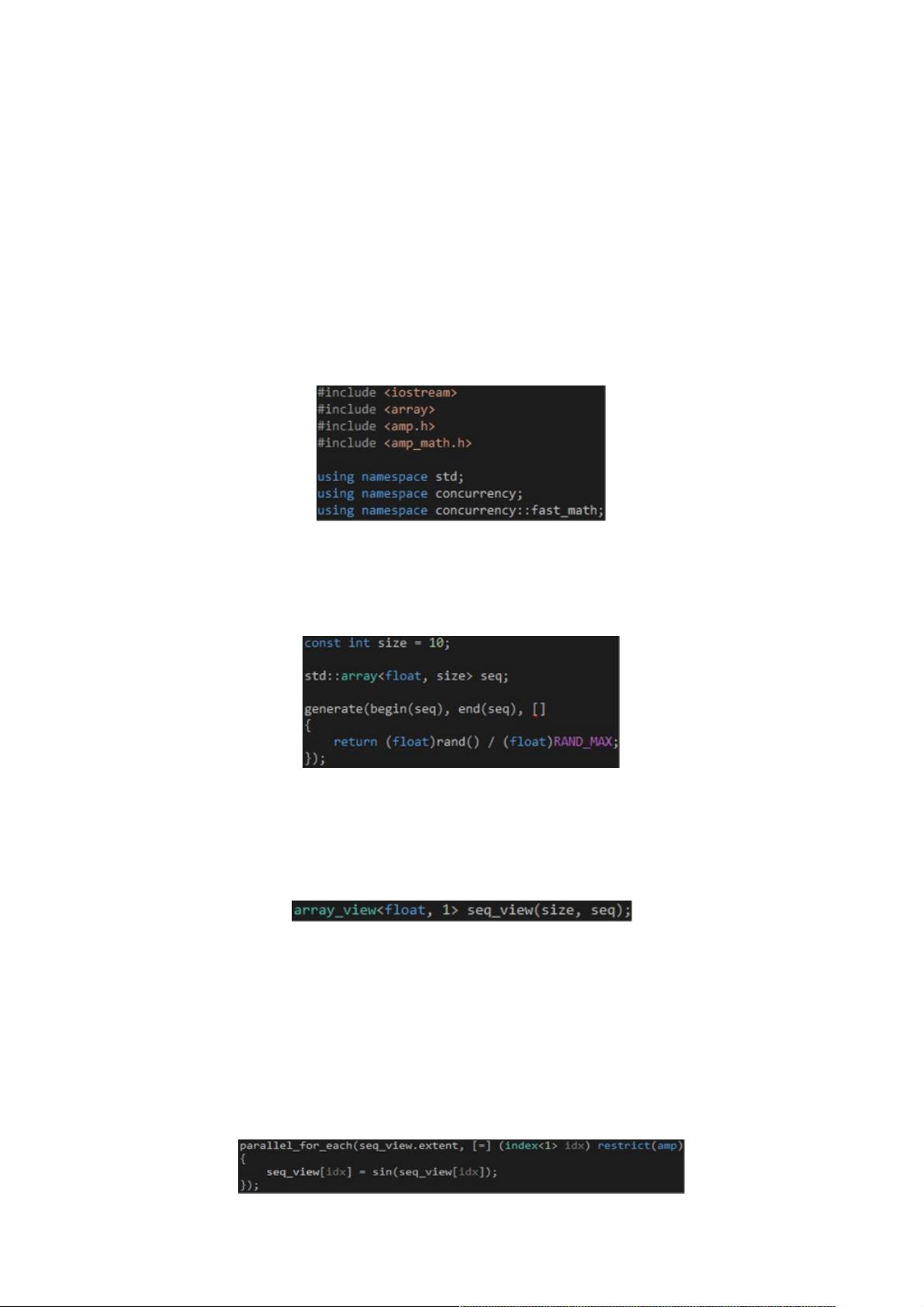
首先,包含/引用相关的头文件/命名空间,如代码1所示。amp.h是C++ AMP的头文件,包含了相关的函数和类,它们位于
concurrency命名空间之内。amp_math.h包含了常用的数学函数,如sin函数,concurrency::fast_math命名空间里的函数只支
持单精度浮点数,而concurrency::precise_math命名空间里的函数则对单精度浮点数和双精度浮点数均提供支持。
代码 1
把浮点数的类型从double改成float,如代码2所示,这样做是因为并非所有GPU都支持双精度浮点数的运算。另外,std和
concurrency两个命名空间都有一个array类,为了消除歧义,我们需要在array前面加上“std::”前缀,以便告知编译器我们使用
的是STL的array类。
代码 2
接着,创建一个array_view对象,把前面创建的array对象包装起来,如代码3所示。array_view对象只是一个包装器,本身不
能包含任何数据,必须和真正的容器搭配使用,如C风格的数组、STL的array对象或vector对象。当我们创建array_view对象
时,需要通过类型参数指定array_view对象里的元素的类型以及它的维度,并通过构造函数的参数指定对应维度的长度以及包
含实际数据的容器。
代码 3
代码3创建了一个一维的array_view对象,这个维度的长度和前面的array对象的长度一样,这个包装看起来有点多余,为什么
要这样做?这是因为在GPU上运行的代码无法直接访问系统内存里的数据,需要array_view对象出来充当一个桥梁的角色,使
得在GPU上运行的代码可以通过它间接访问系统内存里的数据。事实上,在GPU上运行的代码访问的并非系统内存里的数
据,而是复制到显存的副本,而负责把这些数据从系统内存复制到显存的正是array_view对象,这个过程是自动的,无需我们
干预。
有了前面这些准备,我们就可以着手编写在GPU上运行的代码了,如代码4所示。parallel_for_each函数可以看作C++ AMP的
入口点,我们通过extent对象告诉它创建多少个GPU线程,通过Lambda告诉它这些GPU线程运行什么代码,我们通常把这个
代码称作Kernel。
代码 4
我们希望每个GPU线程可以完成和结果集里的某个元素对应的一组操作,比如说,我们需要计算10个浮点数的正弦值,那
下载后可阅读完整内容,剩余4页未读,立即下载
2012-10-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-04-11 上传
点击了解资源详情

weixin_38700320
- 粉丝: 4
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
