"深度学习特征融合与约束联合:优化单通道语音分离方法"
版权申诉
66 浏览量
更新于2024-03-09
1
收藏 764KB DOCX 举报
在日常生活中,语音是人类进行沟通的重要工具。当多个说话者同时讲话时,人类能够准确地分辨他们各自说了什么,但对于智能机器来说,这可能是一个具有挑战性的任务。单通道语音分离是将目标语音从混合语音信号中提取出来的过程,属于盲源分离的一个分支。传统的基于短时谱估计的单通道语音分离算法包括谱减法和维纳滤波法等。随着人工智能在各个领域的广泛应用,深度学习技术也得到了快速的发展。近年来,基于深度学习的单通道语音分离方法在语音分离领域得到了广泛的关注和研究。根据预测目标的不同,基于深度学习的语音分离方法可分为基于时频掩蔽的方法和基于频谱映射的方法。时频掩蔽方法旨在学习从混合信号到时频掩蔽的映射,然后利用估计的掩蔽和混合信号计算得到分离后的语音。2005年,Wang提出了一种理想二值掩蔽作为训练目标,用于听觉场景分析。理想二值掩蔽将语音分离问题抽象为一个二值掩蔽问题,即在每个时频点上将语音掩蔽为二进制值。然后通过利用训练好的模型,来推导出混合语音信号中的目标语音信号。
近年来,基于深度学习特征融合和联合约束的单通道语音分离方法备受学术界的关注。该方法通过引入深度学习技术,结合特征融合和联合约束的思想,实现了对单通道混合语音信号的分离。这种方法不仅提高了语音分离的准确性和效率,还有助于解决传统算法在精确度和泛化性能上存在的问题。具体来说,该方法首先利用深度学习网络对混合语音信号进行特征提取,然后将不同特征的信息进行融合,同时引入联合约束控制。通过联合约束,可以保证分离后的语音信号更加准确和清晰,提高了算法的稳定性和鲁棒性。
另外,该方法还引入了一种基于频域特征的改进掩蔽方法,通过掩蔽后的频谱估计得到更为准确和有效的分离结果。与传统的基于时频掩蔽方法相比,基于频域特征的改进掩蔽方法能够更好地保留语音信号的频率特征,避免了因时域信息缺失而导致的分离效果不佳的情况。
总的来说,基于深度学习特征融合和联合约束的单通道语音分离方法为解决多说话者语音分离问题提供了一种有效的解决方案。通过引入深度学习技术和改进的掩蔽方法,该方法在语音分离准确性和效率性方面取得了显著的进展。未来,可以进一步探索如何优化算法的性能和扩展其在其他领域的应用。希望该方法能够为语音信号处理领域的研究和应用提供新的思路和方法。
深度神经网络具有强大的数据挖掘能力,可以很好地映射网络输入输出间的非线性关
系。与传统基于现代信号处理理论的单通道语音分离算法相比,基于深度学习的单通道语
音分离算法在语音分离模型的构建上更加准确,语音分离也更加有效。基于深度学习的单
通道语音分离主要学习混合语音到预测目标的映射关系,该映射关系由深度神经网络的参
数决定。常用的深度神经网络有 DNN, CNN 和 RNN 等。CNN 的卷积层提取小块区域特
征,可以很好地保留语音特征的空间信息,另外池化层对冗余信息进行筛选,可以减少计
算量,CNN 具有更为出色的语音特征映射能力。以两个源语音混合信号的分离为例,基于
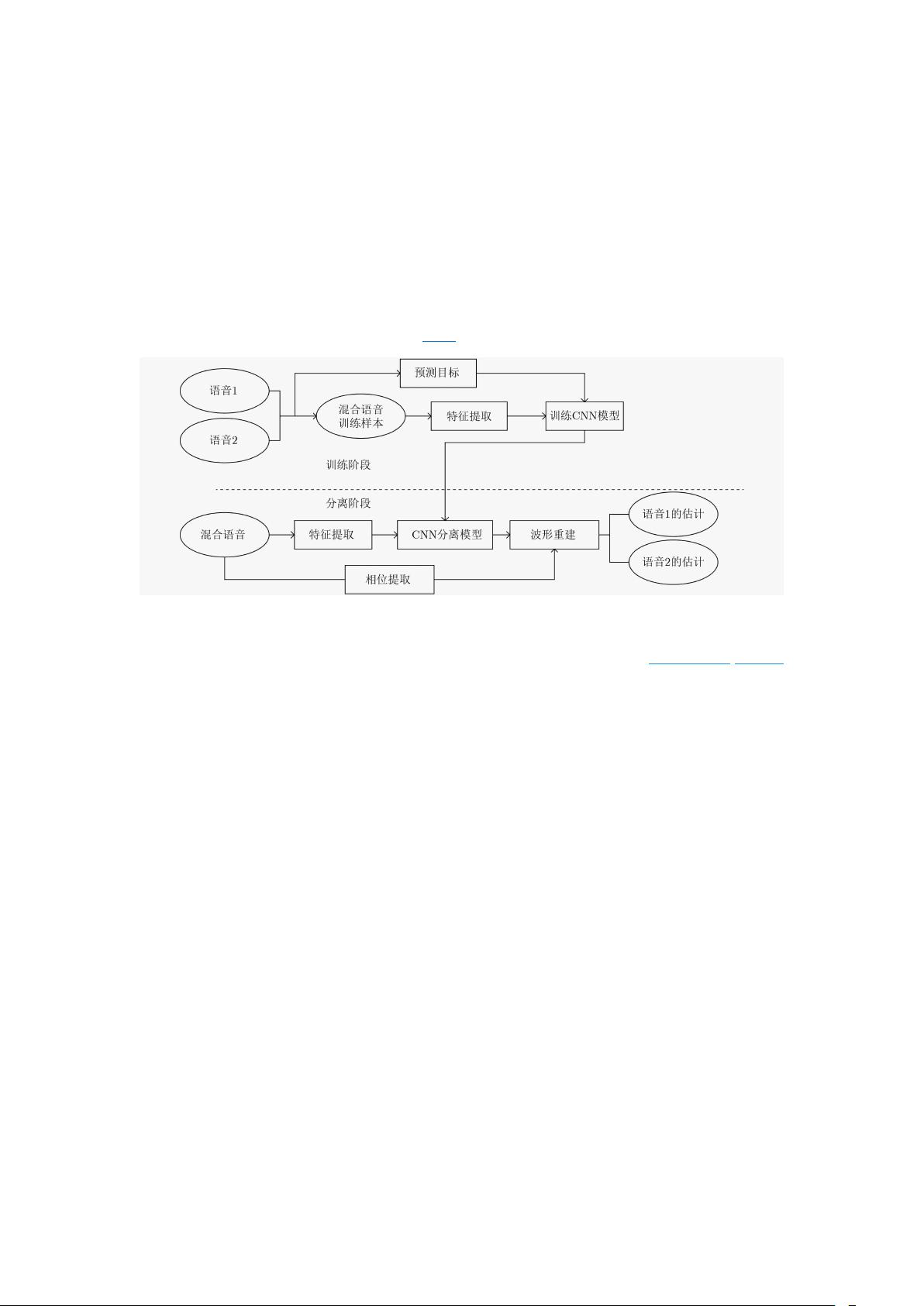
CNN 网络的单通道语音分离系统框图如图 1 所示。
图 1 基于 CNN 的单通道语音分离系统框图
下载: 全尺寸图片 幻灯片
基于 CNN 网络的语音分离包含两个阶段:训练阶段和分离阶段。在训练阶段,提取
两个源语音信号的声学特征以及两源语音混合后信号的声学特征,对其进行归一化等处理
后,利用这些特征和预测目标在损失函数的约束下训练 CNN。在测试阶段,首先提取混合
语音的声学特征,然后将其作为训练好的 CNN 的输入得到分离语音的预测目标,结合相
位信息得到频域信号,最后通过短时傅里叶逆变换得到重构语音的时域波形。
3. 基于 CNN 特征融合的单通道语音分离联合约束算法
3.1 具有融合功能的 CNN 分离模型
在基于传统 CNN 结构的语音分离中,当输入单一特征时得到的分离语音质量有限。
主要由于 CNN 对语音特征信息进行高度抽象化,导致部分全局信息丢失。为了提高分离
语音的质量,本文提出了一种含特征融合层的 CNN 结构,该结构在传统 CNN 基础上增加
了特征融合层,利用 CNN 提取多通道输入特征的深度特征,在融合层中将深度特征与声
学特征融合,该融合特征用于训练语音分离模型。
受图像信号 RGB 处理方式启发,本文将语音多种声学特征以多通道形式作为 CNN 的
输入,提取语音更加全面的深度特征。在基于深度学习的单通道语音分离中,混合信号的
剩余14页未读,继续阅读
201 浏览量
603 浏览量
225 浏览量
2023-02-23 上传
2022-05-31 上传
2022-05-26 上传
118 浏览量
2023-02-23 上传
203 浏览量

罗伯特之技术屋
- 粉丝: 4510
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







