Spark核心技术概览:大数据高速计算引擎
需积分: 0 107 浏览量
更新于2024-06-30
收藏 8.21MB PDF 举报
"Spark讲义(上) 1 - 大数据高速计算引擎Spark的介绍,包括其历史、核心特点、组件以及与MapReduce的对比。"
Spark是大数据处理领域中的一个关键工具,以其高效、通用和易用性著称。自2009年在加州大学伯克利分校AMP实验室诞生以来,它迅速发展,2010年开源并最终在2014年成为Apache顶级项目。Spark的成功在于它提供了一种比MapReduce更快的计算方式,尤其是在内存计算方面,速度提升可达100倍,即使在硬盘计算上也有10倍的增益。
Spark的核心组件SparkCore提供了基础的分布式计算框架,支持离线处理任务。而SparkSQL则进一步扩展了Spark的功能,使其能够处理结构化的数据,同时支持离线和交互式查询。对于实时数据流处理,Spark引入了SparkStreaming,允许对连续的数据流进行微批处理。此外,SparkGraphX则专为图计算设计,适用于社交网络分析等场景。
Spark的高效性得益于其DAG(有向无环图)执行引擎,它能够在内存中存储和重用计算结果,减少了磁盘I/O,从而极大地提升了性能。Spark还提供了丰富的编程接口,支持Scala、Java、Python和R,使得开发者能够轻松构建各种应用程序。特别是其交互式Python(PySpark)和Scala(Spark Shell)环境,让开发者可以快速测试和验证解决方案。
Spark的通用性是另一个显著优势,它集成了批处理、交互式查询、实时流处理、机器学习和图计算等多种处理模式,为用户提供了一站式的大数据处理平台,降低了开发和维护的成本。Spark能够无缝集成到现有的Hadoop生态系统中,通过YARN或Mesos作为资源管理器,使得在不同环境下部署和管理Spark集群变得更加便捷。
总结来说,Spark是大数据领域的革命性工具,以其速度、易用性和广泛的应用范围,已经成为许多企业和研究机构首选的计算引擎,推动了大数据处理技术的发展和创新。通过深入理解和掌握Spark,开发者和数据科学家能够更有效地处理大规模数据,实现更高效的数据洞察。
缓存文件数不表示实际显示的文件总数。只是表示不在缓存中的文件可能需要从硬盘读取,速度稍有差别
前提条件:启动hdfs服务(日志写到HDFS)
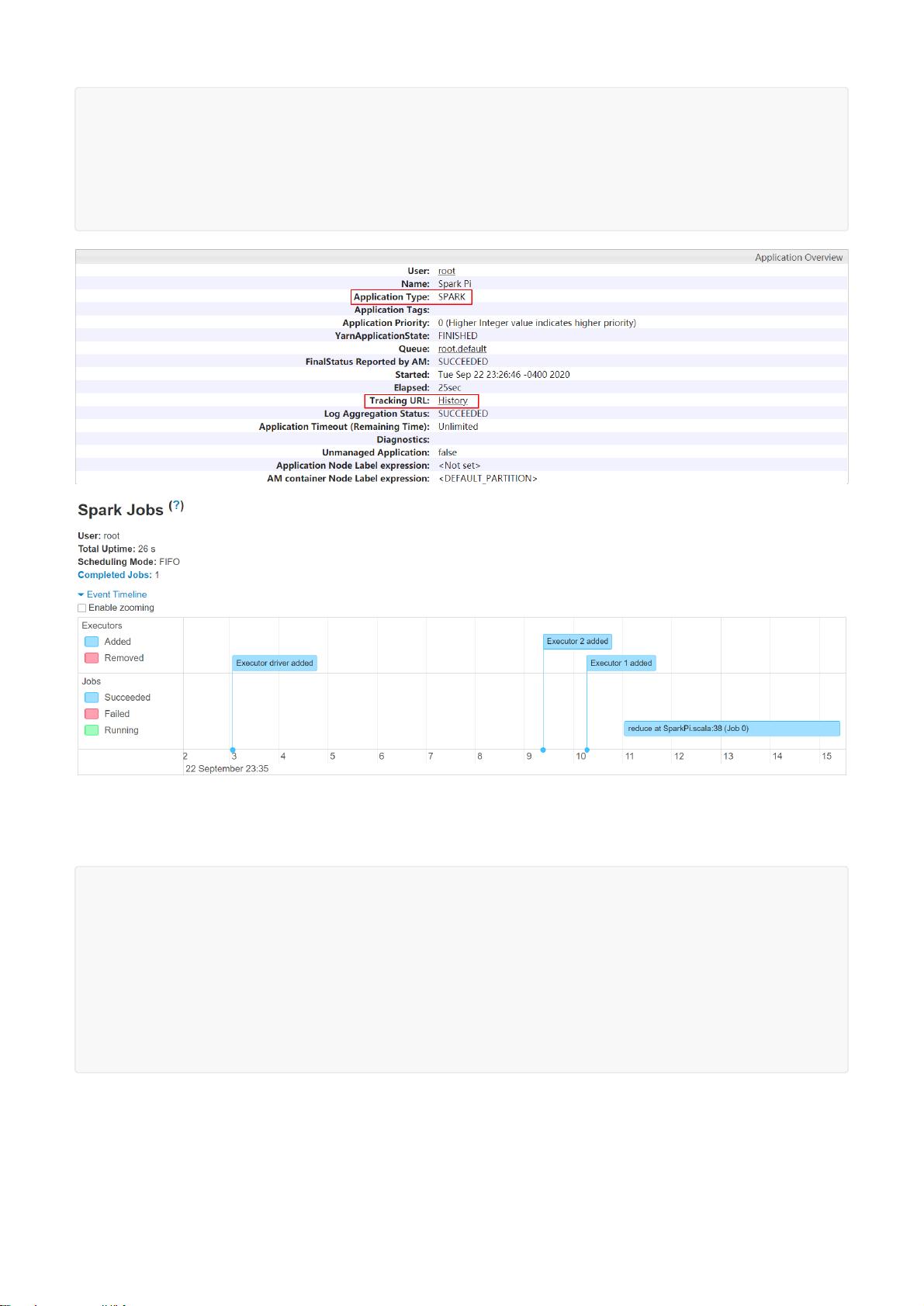
启动historyserver,使用 jps 检查,可以看见 HistoryServer 进程。如果看见该进程,请检查对应的日志。
$SPARK_HOME/sbin/start-history-server.sh
web端地址:http://linux121:18080/
2.4.4 高可用配置
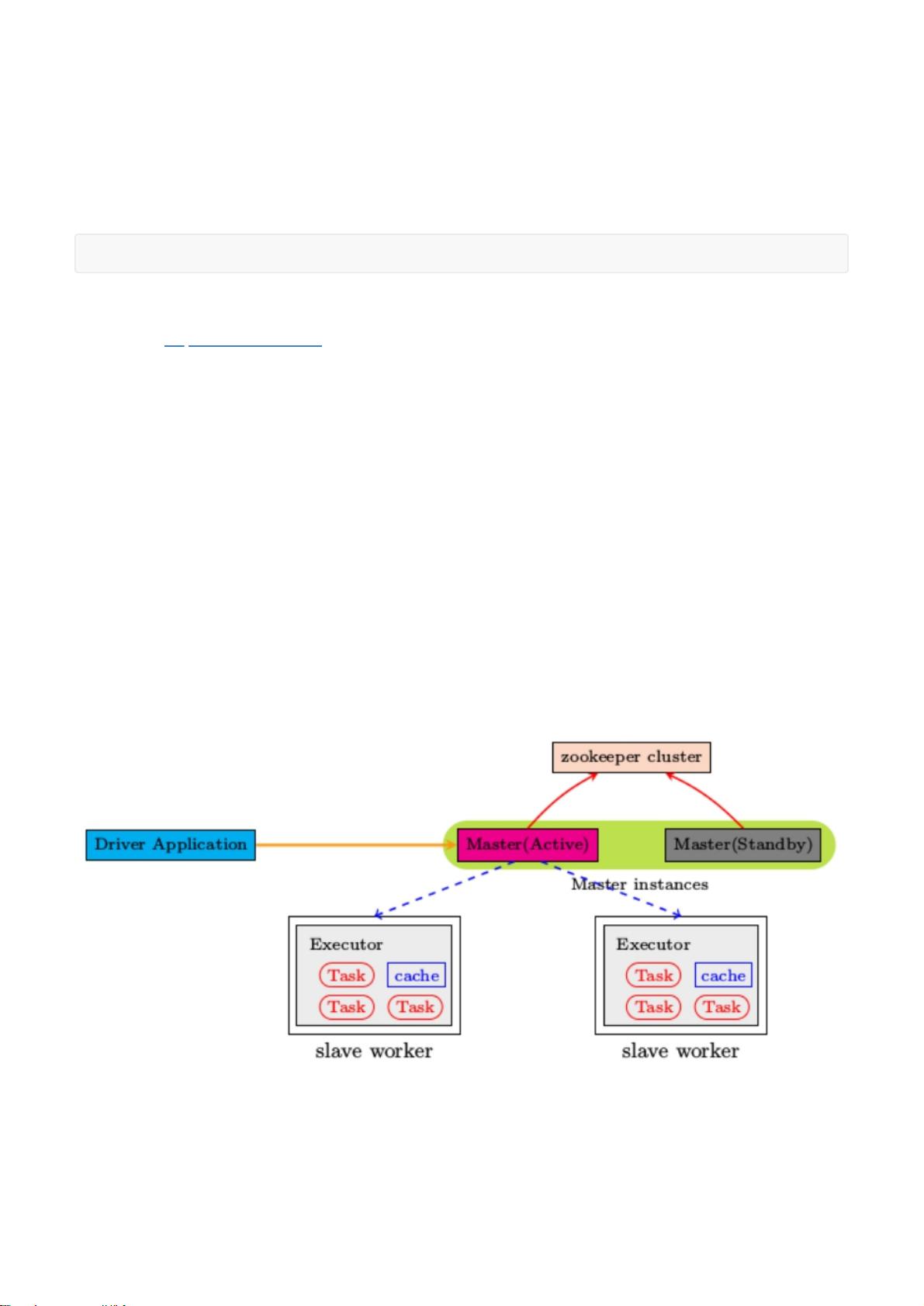
Spark Standalone集群是 Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存着Master单
点故障的问题。如何解决这个问题,Spark提供了两种方案:
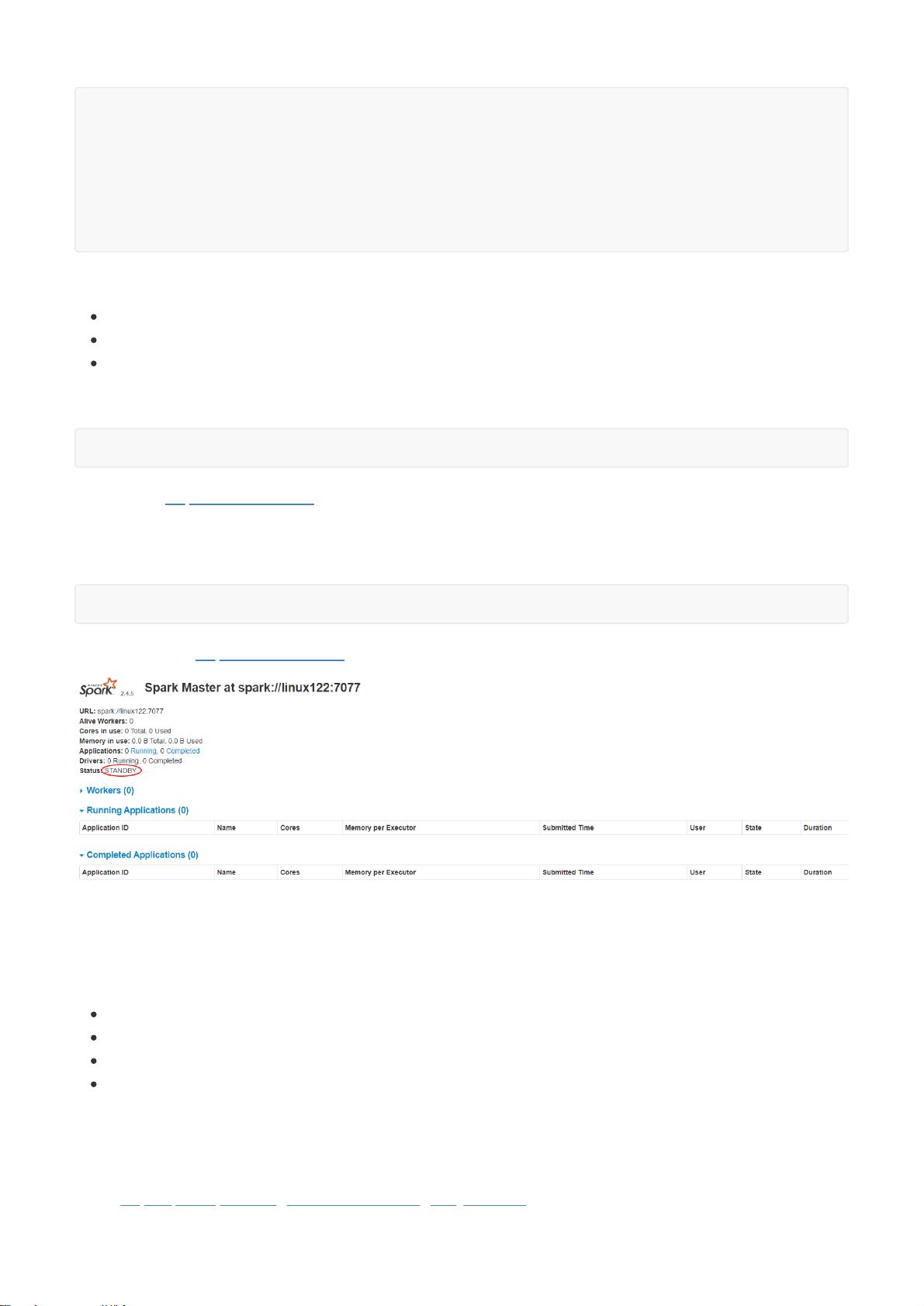
(1)基于zookeeper的Standby Master,适用于生产模式。将 Spark 集群连接到Zookeeper,利用 Zookeeper
提供的选举和状态保存的功能,一个 Master 处于 Active 状态,其他 Master 处于Standby状态;
保证在ZK中的元数据主要是集群的信息,包括:Worker,Driver和Application以及Executors的信息;
如果Active的Master挂掉了,通过选举产生新的 Active 的 Master,然后执行状态恢复,整个恢复过程可能需要1~2
分钟;
(2)基于文件系统的单点恢复(Single-Node Rcovery with Local File System),主要用于开发或者测试环境。将
Spark Application 和 Worker 的注册信息保存在文件中,一旦Master发生故障,就可以重新启动Master进程,将系
统恢复到之前的状态
配置步骤:
1、安装ZooKeeper,并启动
2、修改 spark-env.sh 文件,并分发到集群中

剩余133页未读,继续阅读
2018-08-15 上传
2019-02-03 上传
2023-03-16 上传
2023-12-05 上传
2023-03-16 上传
2023-03-16 上传
2023-05-20 上传
2024-01-09 上传

ali-12
- 粉丝: 32
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
