Flume-ng详解:日志收集与传输指南
需积分: 10 170 浏览量
更新于2024-07-21
收藏 295KB PDF 举报
"Flume自学手册,涵盖了Flume的介绍、架构、安装与使用以及开发相关的详细内容,适合学习和参考。"
Apache Flume 是一个分布式、可靠且可用于有效收集、聚合和移动大量日志数据的系统。它设计用于将数据从多个来源汇聚到一个中心数据存储库,例如Hadoop HDFS。Flume以其高可用性和容错性著称,适用于大规模日志处理场景。
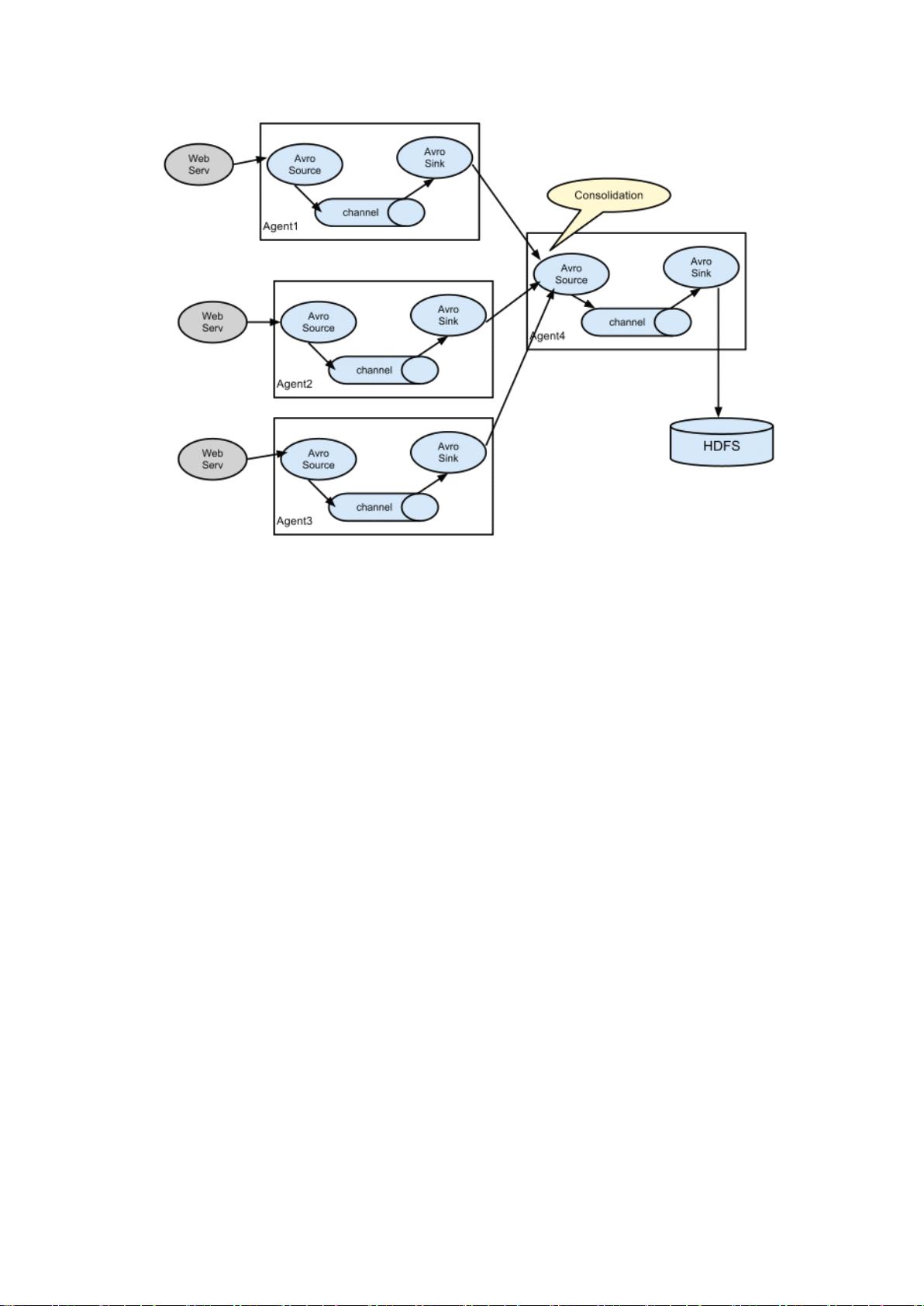
**1. Flume架构**
Flume 的架构基于 Agent 模型,每个 Agent 包含三个主要组件:
- **Source**: 数据源,负责接收来自不同应用或系统的事件数据。Flume 提供多种类型的 source,如 Spooling Directory Source,用于监控文件系统的新文件,或者 Avro Source,用于接收 Avro 格式的数据。
- **Channel**: 数据缓冲区,用于临时存储从 Source 收集到的事件,确保数据在被正确发送到 Sink 之前不会丢失。Channel 可以是内存型(内存缓冲)或文件型(如 JDBC Channel),以实现高可用性和容错性。
- **Sink**: 数据接收器,将 Channel 中的事件传递到最终目的地,例如 HDFS、HBase 或其他外部系统。Flume 提供了多种 Sink 类型,如 HDFS Sink,将数据写入 Hadoop 文件系统。
**2. 数据流和可靠性**
Flume 使用 Event 作为数据传输的基本单元,Event 包含一个 byte 数组主体和可选的 headers。事件从 Source 流动到 Channel,然后到 Sink,确保在 Sink 确认接收成功后才会从 Channel 中删除。这种设计保证了数据的可靠传输。
**3. 安装与使用**
Flume 的安装通常涉及下载最新版本的二进制包,配置相应的配置文件(如 flume.conf),然后启动 Agent。配置文件定义了 Agent 的 Source、Channel 和 Sink,以及它们之间的连接。
**4. 开发相关**
Flume 允许用户自定义 Source、Sink 和 Interceptors(拦截器)。这使得用户可以根据特定需求扩展 Flume 功能,例如创建新的数据源,实现特殊的数据处理逻辑,或者添加特定的日志格式解析。
- **自定义 Source**: 用户可以创建自己的数据源类型,以适应非标准的数据输入方式。
- **自定义 Sink**: 可以构建自定义的 Sink 实现数据的特定存储或处理方式。
- **自定义 Interceptors**: 拦截器允许在数据流入 Channel 之前进行预处理,例如过滤、转换或添加元数据。
**5. 参考文档**
官方文档包括用户指南、开发者指南等,提供了详细的配置、使用和开发说明,是学习和解决问题的重要资源。
Flume 是一个强大的日志管理和分析工具,尤其适用于需要高效、可靠地处理大量日志数据的环境。通过深入理解和实践,可以充分利用其特性来优化数据流动和处理流程。
2.2
2.2
2.2
2.2 核心组件
核心组件
核心组件
核心组件
2.2.1
2.2.1
2.2.1
2.2.1 source
source
source
source
Client 端操作消费数据的来源 , Flume 支持 Avro , log4j , syslog
和 http post(body 为 json 格式 ) 。 可以让应用程序同已有的 Sourc e
直接打交道,如 AvroSource , SyslogTcpSource 。也可以写一个
Source , 以 IPC ( 进程间通信协议 ) 或 RPC ( 远程进程间通信协议 ) 的
方式接入自己的应用, Avro 和 Thrift 都可以 ( 分别有
NettyAvroRpcClient 和 ThriftRpcClient 实现了 RpcClient 接
口 ) , 其中 Avro 是默认的 RPC 协议 。 具体代码级别的 Client 端数
据接入,可以参考官方手册。
剩余17页未读,继续阅读
2023-06-08 上传
2023-11-22 上传
2023-06-11 上传
2023-09-23 上传
2023-08-03 上传
2023-10-19 上传
2023-06-10 上传

hhlllp
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
