基于 Spark 的电影数据分析实践
需积分: 19 125 浏览量
更新于2024-08-05
2
收藏 246KB PDF 举报
基于 Spark 的 RDD 电影分析案例
本文将对基于 Spark 的RDD电影分析案例进行详细解释和知识点总结。
**知识点一:数据读取和预处理**
在 Spark 中,读取数据的方式有多种,例如使用 `textFile` 方法读取文本文件,或者使用 `csv` 方法读取 CSV 文件。在本例中,我们使用 `textFile` 方法读取三个文件:`ratings.dat`、`users.dat` 和 `movies.dat`。这些文件分别存储了用户评分、用户信息和电影信息。
在读取数据后,我们需要对数据进行预处理,例如将数据分割成不同的字段,或者将数据转换为适合分析的格式。在本例中,我们使用 `flatMap` 方法将数据分割成不同的字段,然后使用 `map` 方法将数据转换为适合分析的格式。
**知识点二:数据分析**
在 Spark 中,我们可以使用各种数据分析算法来分析数据。在本例中,我们使用了多种数据分析算法,例如计算男女用户的比例、计算每个用户的平均评分、计算每部电影的平均分等。
例如,在计算男女用户的比例时,我们使用 `flatMap` 方法将用户信息分割成不同的字段,然后使用 `map` 方法将数据转换为适合分析的格式。最后,我们使用 `reduceByKey` 方法计算男女用户的比例。
**知识点三:数据排序和排名**
在 Spark 中,我们可以使用 `sortBy` 方法对数据进行排序和排名。在本例中,我们使用 `sortBy` 方法对每个用户的平均评分进行排序和排名,以便获取排名前十和最后十名的用户及其评分。
**知识点四:数据 filtering**
在 Spark 中,我们可以使用 `filter` 方法对数据进行 filtering。在本例中,我们使用 `filter` 方法过滤掉评分数据不够 250 条的电影,然后计算每部电影的平均分。
**知识点五:数据聚合**
在 Spark 中,我们可以使用 `groupByKey` 方法对数据进行聚合。在本例中,我们使用 `groupByKey` 方法将每个用户的评分聚合起来,然后计算每个用户的平均评分。
**知识点六:数据 visualization**
在 Spark 中,我们可以使用 `foreach` 方法对数据进行 visualization。在本例中,我们使用 `foreach` 方法将结果打印出来,以便更好地理解和分析结果。
本文通过对基于 Spark 的 RDD 电影分析案例的解释和知识点总结,展示了 Spark 在大数据分析领域的强大能力和广泛应用前景。
电影分析实训实验报告
所有代码均为原创,若有问题肯请斧正
编程一
代码展示
输出结果
编程二
代码展示
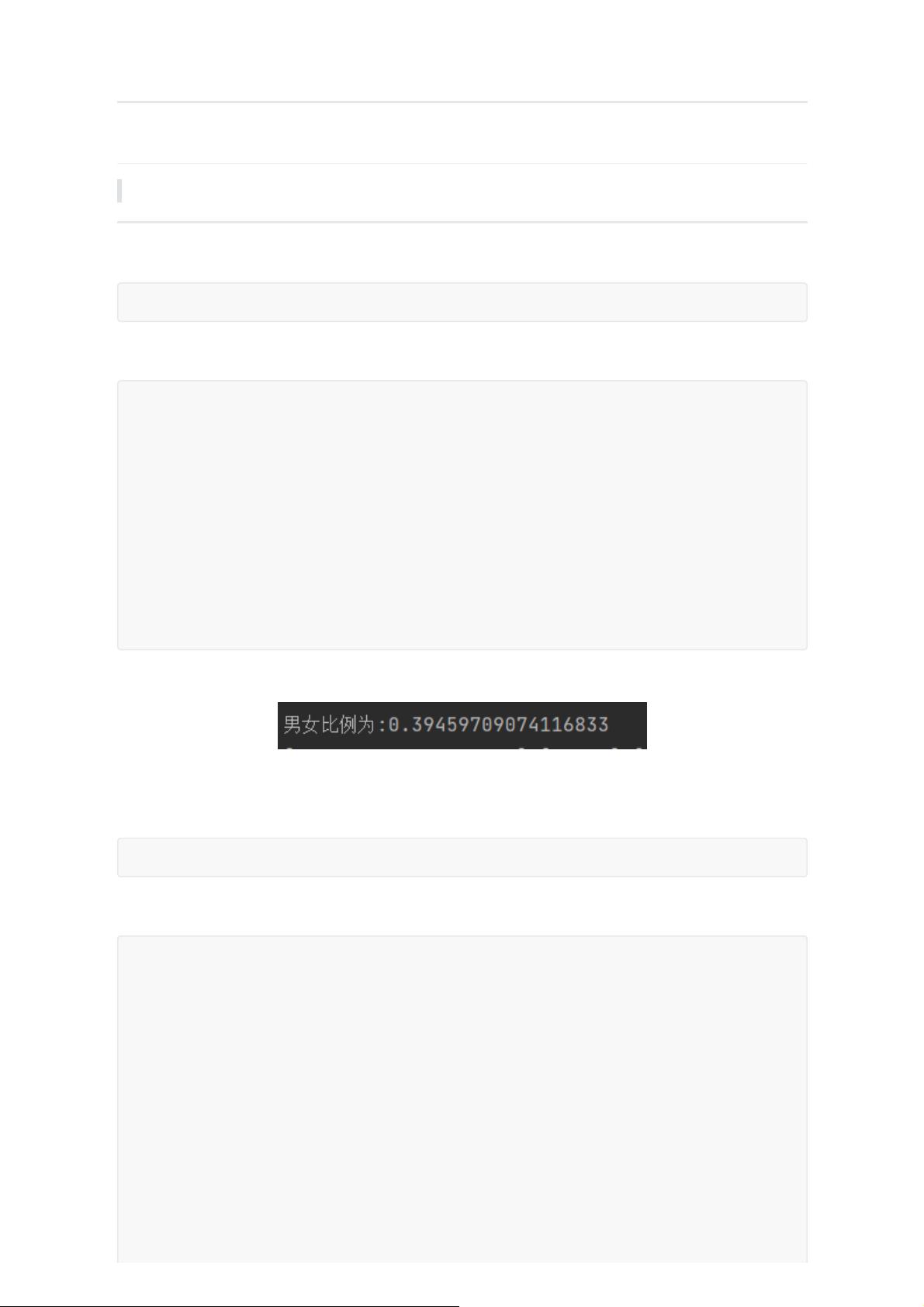
1. 男女用户的比例
object GenderRatio {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("男女比例").setMaster("local[*]")
val sc = new SparkContext(conf)
val x = sc.textFile("hdfs://192.168.40.133:9000/data/FilmData/users.dat")
.flatMap(x=>x.split("::")(1))
.map(x=>(x,1))
.reduceByKey(_+_)
.collect()
println("男女比例为:"+x(0)._2/x(1)._2.toDouble)
}
}
2.每个用户的平均评分中,排名前十和最后十名的用户以及其评分分为是多少?
object EndpointRank {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("端点评分").setMaster("local[*]")
val sc = new SparkContext(conf)
val x = sc.textFile("hdfs://192.168.40.133:9000/data/FilmData/ratings.dat")
.map(x=>(x.split("::")(0),x.split("::")(2).toDouble))
.groupByKey()
.map(x => {
val avg: Double = x._2.reduce(_ + _) / x._2.size
(x._1,avg)
})
println("得到每个用户的平均评分中,最后十名的用户及其评分")
x.sortBy(_._2)
.take(10)
.foreach(println)
下载后可阅读完整内容,剩余7页未读,立即下载
112 浏览量
188 浏览量
点击了解资源详情
2021-07-18 上传
984 浏览量
2024-12-13 上传
2023-05-29 上传
2023-06-11 上传
131 浏览量

是英俊啊
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- IA-32 Assembly Language
- DOS下常用网络相关命令解释
- GIS新引擎——“真图”数据解决方案.pdf
- 嵌入式Linux设备驱动开发.pdf
- JPA入门_PDF JPA
- 计算机网络技术 计算机网络技术
- 计算机通信技术计算机通信技术
- 初学者编程学习的文章
- BS EN 71-1-2005(+A4-2007)
- 消灭压力的高效工作方法
- 《Modeling Our World》中文版本
- Linux 上的GNOME 2.2 桌面用户指南.pdf
- Linux 系统上的GNOME 2.2 桌面管理指南.pdf
- 生化要点把一些生化要点都总结
- Linux内核完全注释-1.9.5.pdf
- 新版设计模式手册[C#]
