"误差与实验数据的处理-第二部分2022优秀文档.ppt"
本文档主要讨论了误差分析和实验数据处理的关键概念,包括误差的类型、随机误差的正态分布以及有限测定数据的统计处理方法。以下是详细内容:
1. **误差的根本概念**
- **准确度** (Ea, Er):指的是测量结果与真实值之间的接近程度,准确度高意味着误差小。
- **偏差** (d):测量值与平均值之差,用来衡量数据的离散程度。
- **标准偏差** (σ, s):用于量化一组数据的分散程度,是所有偏差平方的平均平方根。
- **样本标准偏差** (s) 和 **总体标准偏差** (σ):前者用于样本数据,后者用于整个总体。
2. **准确度与精细度的关系**
- 准确度关注的是测量结果与真实值的一致性,而精细度则关注重复测量的一致性。
- 系统误差通常是固定的,源于仪器或方法的固有缺陷,难以消除;随机误差则是不可预知的,可能由于环境变化或操作误差引起。
3. **系统误差和随机误差**
- 系统误差可以通过改进设备或方法来减少。
- 随机误差遵循一定的统计分布,通常假设为正态分布。
4. **随机误差的正态分布**
- 正态分布是一种重要的统计模型,描述了大量独立随机变量的平均值的分布情况。
- 在实验数据处理中,经常使用t分布来处理有限次数的测定数据,因为它更能反映实际数据的不确定性。
5. **有限测定数据的统计处置**
- **t分布曲线**:当样本数量有限时,用t分布来代替正态分布,描述数据的分布规律。
- **置信度** (P):表示人们对测量结果的把握程度,是落在特定区间的概率。
- **显著性程度** (α):1-P,表示结果落在置信区间之外的概率。
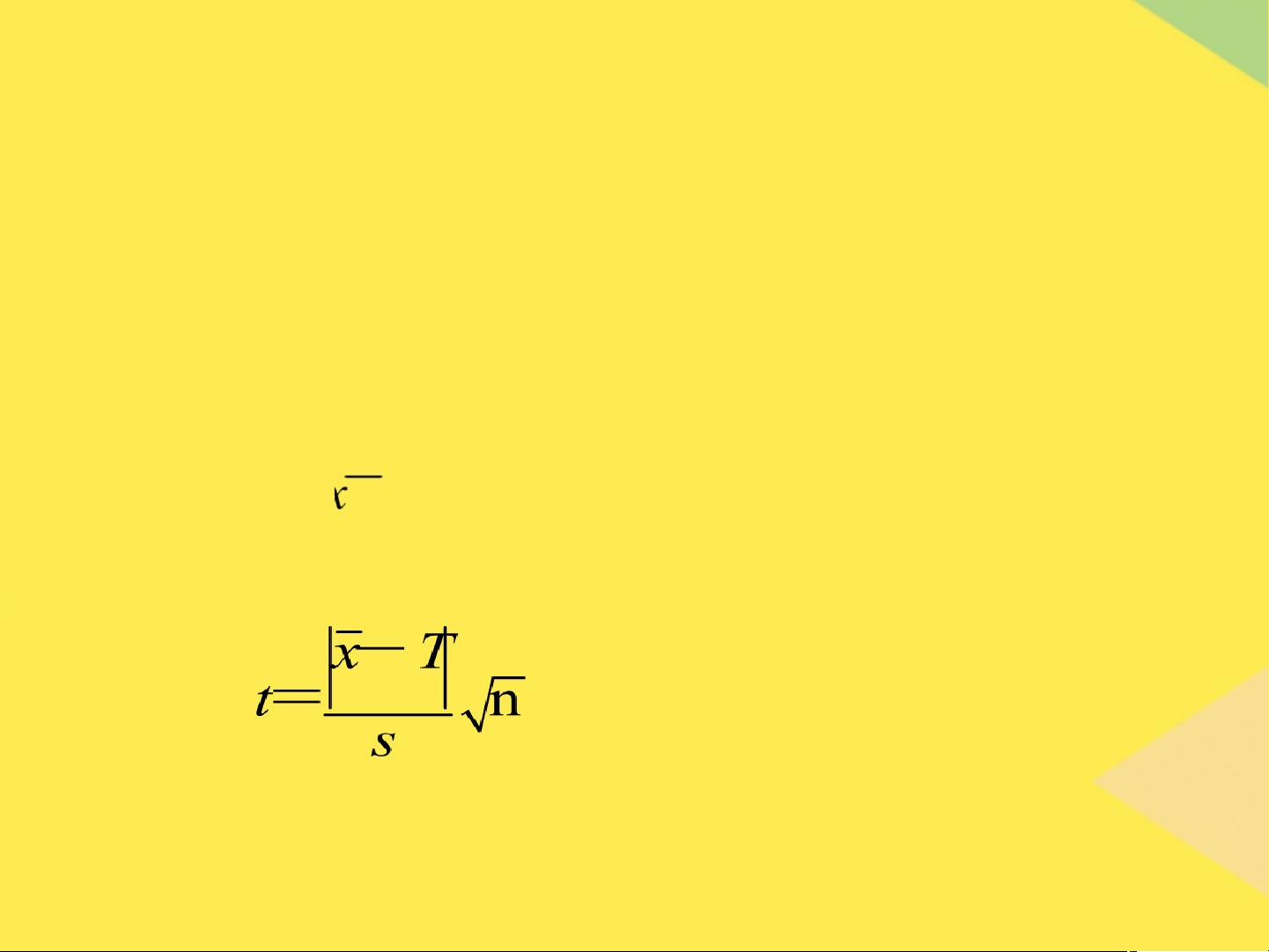
- **t值**:与置信度和自由度(f)相关,用于计算置信区间。
6. **平均值的置信区间**
- **置信区间** 是基于测量结果和置信度估计的总体平均值可能的范围。
- 当已知总体标准偏差(σ)时,可以使用u值计算置信区间;若仅知样本标准偏差(s),则需用t值。
- 置信度越高,置信区间越宽,表明不确定性更大;反之,置信度低时,置信区间窄,测量结果更接近真实值。
7. **实例解析**
- 例如,一个实验测定乙醇含量的平均值为50.48%,标准偏差为0.02%,样本数量为9,要求95%置信度的置信区间。
- 解决这个问题需要用到t分布表,找到对应置信度的t值,然后计算置信区间。
总结,这个文档提供了误差分析和实验数据处理的基础知识,涵盖了误差的种类、正态分布的运用以及如何通过置信度和t分布来确定数据的可信范围。这些知识对于进行科学实验和数据分析至关重要。