GitHub开源项目驱动的软件工作量估计:一项案例研究
193 浏览量
更新于2024-08-27
收藏 1.21MB PDF 举报
"这篇研究论文探讨了基于开源项目(如GitHub)进行软件开发工作量估计的方法。作者通过收集和分析开源项目的数据,构建预测模型来预估新项目的开发工作量。关键词包括软件工作量估计、数据收集、自动化功能点、开源项目和AdaBoost算法。"
在软件开发过程中,工作量估计是一项至关重要的任务,它直接影响到项目的进度规划、资源分配以及成本控制。传统的软件工作量估计方法通常依赖于专家的经验和历史项目数据。然而,随着开源软件的普及,尤其是在GitHub这样的平台上,大量的开源项目为研究者提供了丰富的数据资源,使得基于数据驱动的工作量估计成为可能。
该研究论文对GitHub上的开源项目进行了深入分析,以收集有关项目规模、复杂性、开发周期等关键指标的数据。这些信息有助于理解不同项目之间的差异,从而构建更精确的预测模型。其中,自动化功能点(Automated Function Point)是一种衡量软件规模的标准,它考虑了软件的功能性和复杂性,为工作量估计提供客观依据。
研究中提到,利用 AdaBoost 算法来训练预测模型。AdaBoost 是一种集成学习算法,能够结合多个弱分类器形成强分类器,以提高预测的准确性。通过这种机器学习技术,研究者可以处理大量非结构化的项目数据,找出影响工作量的关键因素,并生成有效的预估模型。
此外,数据收集是此研究的关键步骤。研究者不仅要收集开源项目的代码行数、开发者数量、提交频率等基本数据,还需要考虑到项目文档、问题报告、版本迭代等多方面信息,以全面反映项目的工作量。这一步骤对于确保模型的泛化能力和预测精度至关重要。
这篇论文通过实证研究展示了如何利用开源项目(如GitHub)的数据来改进软件工作量估计的准确性和效率。其结果不仅对项目管理者有实际指导意义,也为未来在大数据背景下进一步探索软件开发中的工作量估计问题提供了新的思路和方法。
F. Qi et al. / Information and Software Technology 92 (2017) 145–157 147
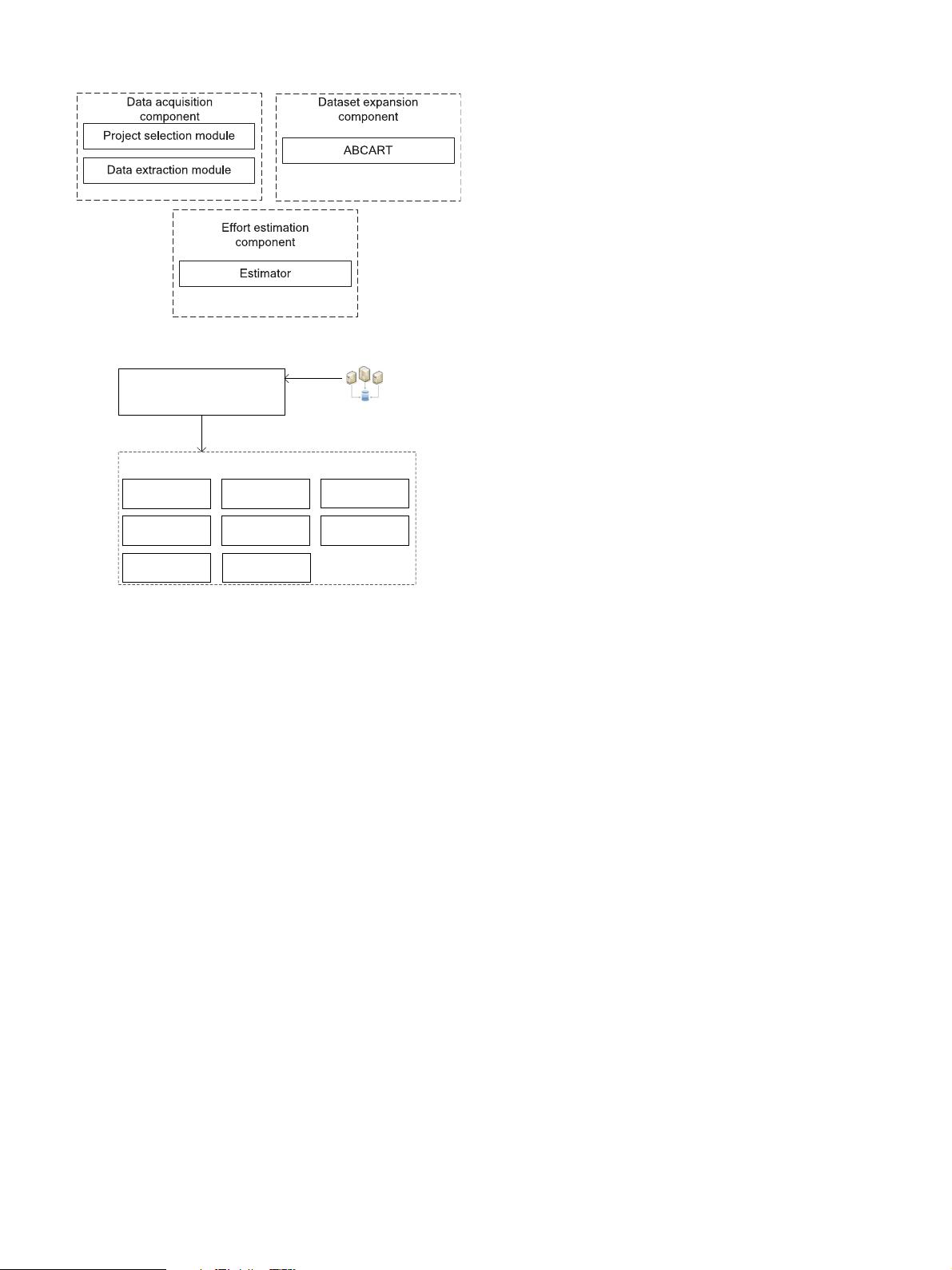
Fig. 1. Overview of our method.
http://www.github.com
Project information
selection module
Metric 1 Metric 2
Metric 4 Metric 5 Metric 6
Metric 7
Metric 3
Effort
Effort data extraction module
Fig. 2. Compositions of data acquisition component.
3. Our method
3.1. Overview of our method
Our proposed method consists of three parts, which is illus-
trated as Fig. 1 .
Data acquisition component: This component is responsible
for obtaining necessary data from OSP for effort estimation. The
main functions of this component include scrapping projects from
GitHub, filtering the collected projects, and extracting the neces-
sary data from the filtered projects.
Dataset expansion component: To get more effort data to train
the prediction models, we design this component to increase the
samples of the collected dataset.
Effort estimation component: This component is responsible
to train a prediction model on the collected data to estimate the
effort of a new project.
In this paper, we mainly concentrate on the components of data
acquisition and dataset expansion. For the effort estimation com-
ponent, we use CART [43] as the estimator to predict the effort of
a new project.
3.2. Data acquisition component
The data acquisition component consists of two modules: (1)
project information selection module; (2) and effort data extrac-
tion module. The compositions of data acquisition component are
shown in Fig. 2 .
Project information selection module: This module is respon-
sible to scrape relevant projects information from GitHub by using
the user specified keywords, and filter the obtained raw projects
information.
Effort dat a extraction module: This module is responsible for
downloading and analyzing source codes of projects from GitHub,
as well as extracting effort data of each project according to our
cost model.
Next, we will individually introduce these modules.
3.2.1. Project selection module
There are thousands of open source projects stored on GitHub,
where many APIs are provided for users to access project informa-
tion. Assume that we have not enough projects as the reference
object for estimating the effort required by a software system. In-
tuitively, we can obtain the reference projects from GitHub as the
training data for constructing the prediction model. GitHub hosts
over 53 million projects, it’s impossible and unnecessary to analyze
all the projects, therefore, how to select appropriate projects from
these massive data is the first issue to be considered. We develop
this module which takes the following three aspects into consider-
ation to select project.
Development time: The projects we selected are from 2011
to 2016. With the progress of development language and IDE, as
well as the increasing of user’s requirements, the efforts required
by developing a new software project may be different at differ-
ent times. For example, we want to use a machine learning algo-
rithm in a Java project (such as the support vector machine (SVM)
[50] described by Cortes and Vapnik in 1995) to make a predic-
tion in 20 0 0, we may need to spend a lot of time to understand
and rewrite this algorithm with Java language. This is quite time-
consuming. However, in nowadays, with the available of many ma-
chine learning libraries, such as JAVA-ML [51] (which implements
many commonly used machine learning algorithms and provides
services through different interfaces), we can invoke the SVM algo-
rithm in our program directly. Off-the-shelf libraries will improve
the development efficiency of a project and decrease the effort re-
quired by a new project. Therefore, it is necessary to filter out a
part of projects according to the developing time of the projects.
Team size: The team size of a project on GitHub can be eval-
uated by the number of contributors of this project. Since the
project developed by a team with only one or two persons usu-
ally doesn’t conform to the team configurations of most companies
(e.g., Scrum guide recommends that development team size should
be between 3 and 9 [52] ), we require the team size of the project
to be collected must be larger than 3.
Business-related: To train a good prediction model, sufficient
training data is a required element, furthermore, it would be bet-
ter if the collected effort dat a is similar to the projects to be
estimated. As compared with the CSPs, we can easily get more
business-related effort data of OSPs from GitHub. This requirement
can be implemented by using the API of ‘ https://api.github.com/
search/repositories?q=keywords ’.
3.2.2. Data extraction module and cost metrics
The required effort for developing a project is determined by
many cost metrics, such as LOC, FP, PLEX, and etc. [ 16 , 31 , 42 ]. We
divide commonly used cost metrics into two groups: (1) function
point analysis model, and (2) COCOMO II, which are summarized
in Table 1 .
Albrecht [31] published a dataset which is composed by 24
projects completed at IBM in the 1970 s. Their projects are devel-
oped by using the third-generation languages, such as COBOL, PL1,
and etc. China dataset [46] consists of the software projects from
different com panies of China, which contains 499 sam ples with 17
cost metrics and one effort label. Kitchenham dataset [16] is com-
posed by the effort data of different projects from a single out-
sourcing company, which contains 145 projects’ effort data. Chi-
damber and Kemerer [32] published a dataset which is constructed
剩余12页未读,继续阅读
2018-03-25 上传
2013-04-03 上传
2019-05-31 上传
2023-04-01 上传
2023-04-07 上传
2023-06-12 上传
2024-02-02 上传
2023-04-24 上传
2023-02-15 上传
2023-02-22 上传

weixin_38617196
- 粉丝: 5
- 资源: 933
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
