CUDA 2.0编程入门:并行模型与API详解
需积分: 15 151 浏览量
更新于2024-07-27
收藏 2.6MB PDF 举报
NVIDIA CUDA编程指南,版本2.0,是针对NVIDIA计算统一设备架构(CUDA)的全面教程。CUDA是一种专为图形处理单元(GPU)设计的并行编程模型,旨在利用GPU的高度并行性和多线程特性来加速计算密集型任务。这份指南主要分为四个章节:
1. **简介**:
- CUDA提供了一种可伸缩并行编程模型,使得开发者能够编写能够在CPU和GPU之间无缝协作的应用程序。
- GPU的特点是拥有众多并行处理核心,称为多核处理器,能同时执行大量独立任务。
- 文档结构清晰,介绍了整个指南的组织方式,以便读者循序渐进地学习。
2. **编程模型**:
- 线程层次结构涉及到CUDA程序如何在GPU上组织和执行,包括线程块(block)和线程(thread)的概念。
- 存储器层次结构包括全局内存、共享内存和纹理内存,用于管理和访问不同的数据存储区域。
- 主机和设备之间的交互,解释了CPU和GPU之间的数据传输和控制流管理。
- 软件栈概述了CUDA编程所需的工具链,包括CUDA编程语言、驱动程序和NVCC编译器。
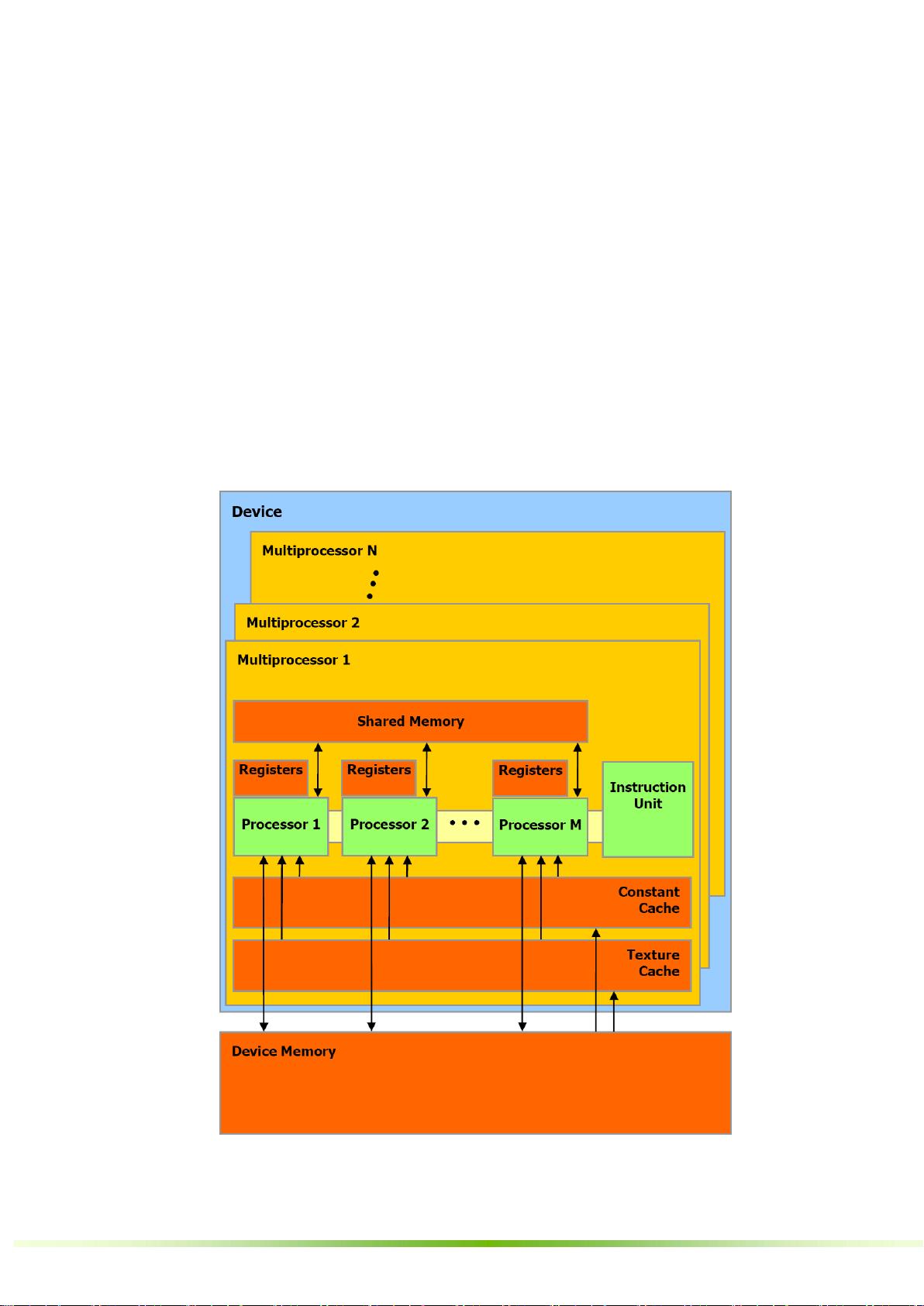
3. **GPU实现**:
- 描述了CUDA架构中的SIMT(Single Instruction Multiple Thread)多处理器,以及它们如何共享芯片内存。
- 讨论了单个GPU设备到多个GPU设备的扩展性,以及程序如何在不同设备间切换执行模式。
4. **应用程序编程接口**:
- CUDA对C语言进行了扩展,引入了特殊的限定符如 `_device_`、 `_global_` 和 `_host_`,以区分在GPU或CPU上运行的代码。
- 详细解释了变量类型限定符,如常量、共享和全局变量的使用规则。
- 计算配置参数如gridDim、blockIdx、blockDim、threadIdx等内置变量,用于指定并行任务的分布和执行环境。
- NVCC编译器的一些特殊选项,如`_noinline_`和`#pragma unroll`,对性能优化的重要性。
此外,指南还介绍了通用运行时组件,如内置向量类型,这些提供了高效的向量化操作支持。这份指南涵盖了CUDA编程的基础概念、架构细节和实用编程技巧,对于想要利用NVIDIA GPU进行并行计算的开发者来说,是不可或缺的参考资源。
CUDA
编程指南,版本
2.0 7
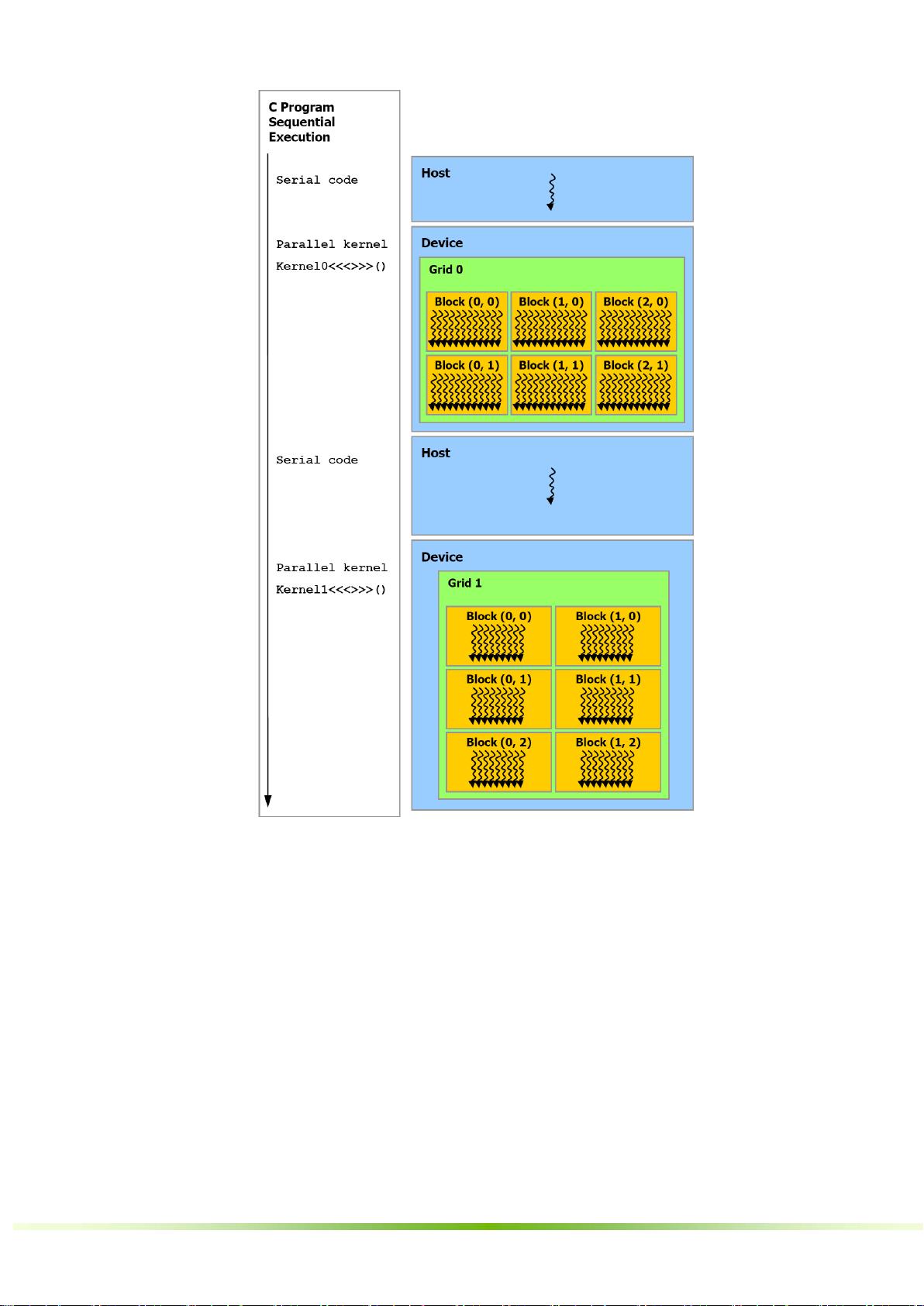
串行代码在主机上执行,而并行代码在设备上执行。
图
2-3.
2-3.
2-3.
2-3.
异构编程
2.4
2.4
2.4
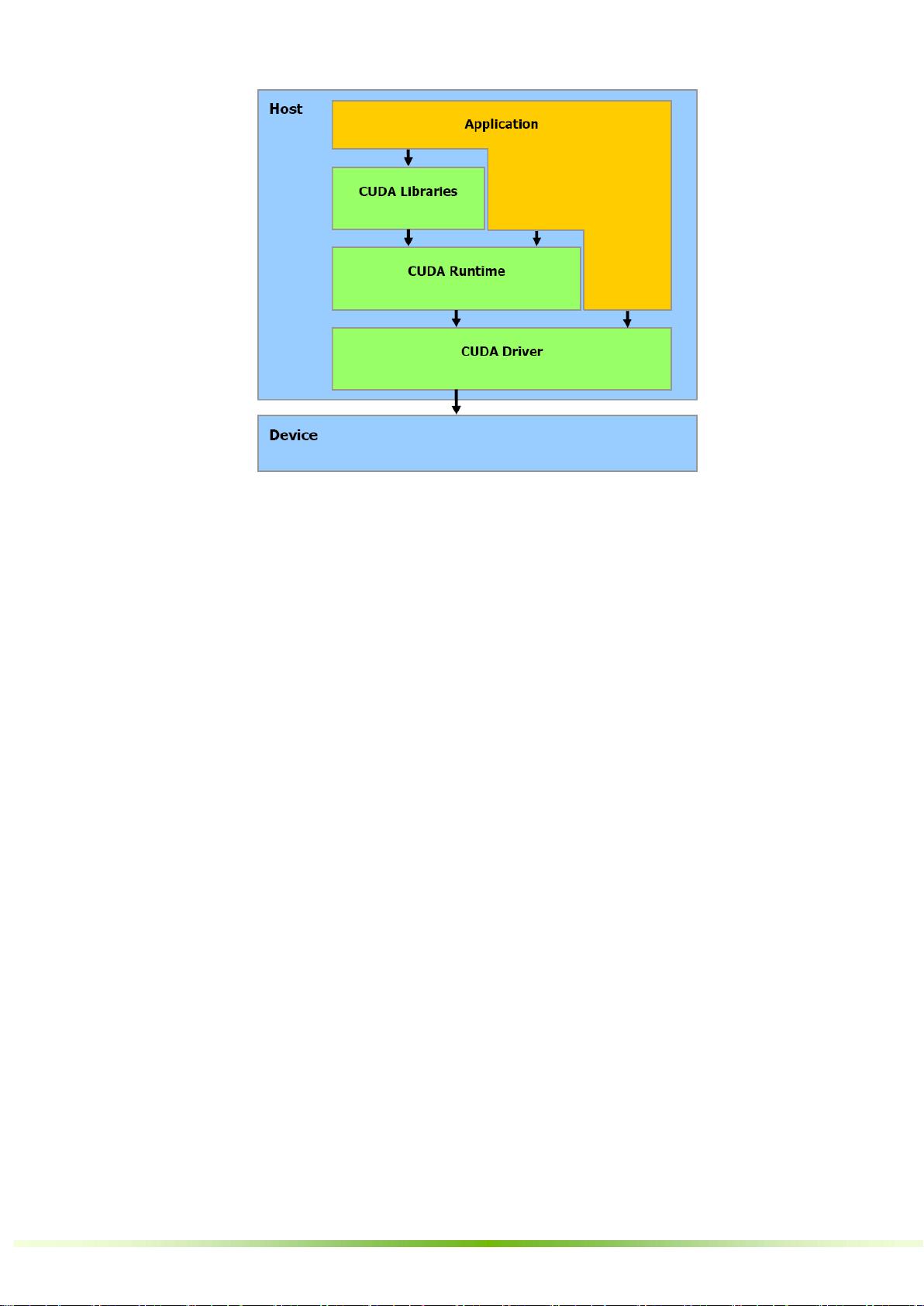
2.4 软件栈
软件栈
软件栈
软件栈
CUDA 软件栈包含多个层 , 如图 2-4 所示 : 设备驱动程序 、 应用程序编程接口 ( API ) 及其运行时 、 两个
较高级别的通用数学库,即 CUFFT 和 CUBLAS ,这些内容均在其他文档中介绍。

剩余76页未读,继续阅读
2011-01-14 上传
2015-12-23 上传
2008-10-14 上传
2008-09-19 上传
2023-08-28 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

码侬
- 粉丝: 50
- 资源: 111
 我的内容管理
展开
我的内容管理
展开







