深度学习交通图像:大规模交通网络速度预测的卷积神经网络
版权申诉
107 浏览量
更新于2024-07-21
收藏 2.57MB PDF 举报
“Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction”
这篇论文提出了一种基于深度卷积神经网络(CNN)的方法,该方法将交通流量视为图像,用于准确预测大规模交通网络的速度。通过将空间时间交通动态转化为描述性的图像,该模型能够捕获交通流量的复杂模式并进行预测。
交通图像表示:论文的核心思想是将交通数据视为二维图像,这允许研究人员利用计算机视觉领域的技术,特别是CNN,来处理这些数据。在交通监控系统中,大量的传感器数据可以被转换成图像,每个像素代表特定时间和地点的交通速度或流量。
深度卷积神经网络(CNN):CNN是一种强大的机器学习模型,尤其在图像识别和分析任务中表现出色。在这里,CNN被用来学习交通图像中的特征,这些特征可能包括交通流的模式、拥堵的分布以及速度变化的趋势。CNN的多层结构使得它能够自动从原始数据中提取高级抽象特征,从而提高预测的准确性。
大型交通网络速度预测:论文关注的是整个交通网络的速度预测,而不仅仅是单个路口或路段。这对于城市交通管理和规划至关重要,因为它提供了对整体交通状况的全面了解,有助于预防拥堵和优化交通流量。
空间时间动态:交通流量并非孤立的,而是受到空间和时间因素的影响。这种“时空动态”是预测模型的关键考虑因素。将这些动态转化为图像,可以利用CNN的空间和时间滤波能力,有效地捕捉和分析这些复杂的相互作用。
训练与评估:虽然文章没有详细描述训练过程,但通常涉及对历史交通数据的训练,以调整网络参数。预测性能的评估可能包括均方误差(MSE)、平均绝对误差(MAE)等指标,这些指标衡量了模型预测结果与实际交通速度之间的差异。
结论与应用:这种方法为交通工程领域提供了一个新的工具,能够更准确地预测大规模交通网络的速度,有助于交通管理部门实时监控和优化交通流量。潜在的应用可能包括智能交通信号控制、路况预报和导航系统的改进。
这篇论文展示了一种创新的方法,将交通数据转换为图像,利用深度学习技术进行分析,从而提升大规模交通网络的速度预测精度。这一方法对于解决现代城市的交通问题具有重要的理论与实践意义。
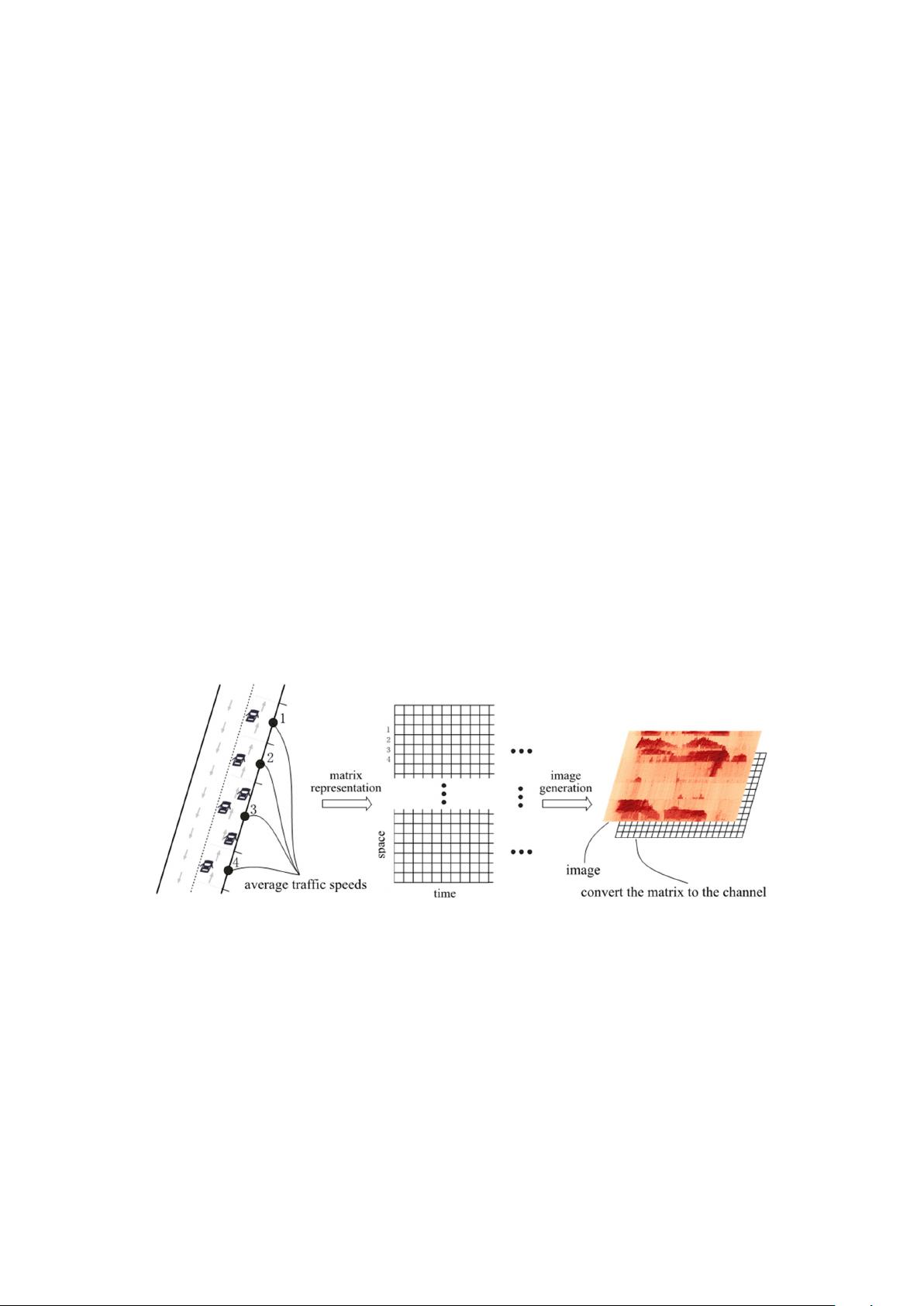
Sensors 2017, 17, 818 4 of 16
traffic information on each road segment can be estimated and integrated further into a time-space
matrix that serves as a time-space image.
In the time dimension, time usually ranges from the beginning to the end of a day, and time intervals,
which are usually 10 s to 5 min, depend on the sampling resolution of the GPS devices. Generally,
narrow intervals, for example 10 s, are meaningless for traffic prediction. Thus, if the sampling
resolution is high, these data may be aggregated to obtain wider intervals, such as several minutes.
In the space dimension, the selected trajectory is viewed as a sequence of dots with inner states,
including vehicle position, average speed, etc. This sequence of dots can be ordered simply and
linearly fitted into the y-axis, but may result in a high dimension and uninformative issues, because
the sequences of dots are redundant and a large number of regions in this sequence are stable and
lack variety. Therefore, to make the y-axis both compact and informative, the dots are grouped into
sections, each representing a similar traffic state. The sections are then ordered spatially with reference
to a predefined start point of a road, and then fitted into the y-axis.
Finally, a time-space matrix can be constructed using time and space dimension information.
Mathematically, we denote the time-space matrix by:
M =
m
11
, m
12
, · · · , m
1N
m
21
, m
22
, · · · , m
2N
.
.
.
.
.
. · · ·
.
.
.
m
Q1
, m
Q2
, · · · , m
QN
(1)
where N is the length of time intervals, Q is the length of road sections; the ith column vector of M is
the traffic speed of the transportation network at time i; and pixel m
ij
is the average traffic speed on
section i at time j. Matrix M forms a channel of the image. Figure 1 illustrates the relations among raw
averaged floating car speeds, time-space matrix, and the final image.
Sensors 2017, 17, 818 4 of 16
traffic information on each road segment can be estimated and integrated further into a time-space
matrix that serves as a time-space image.
In the time dimension, time usually ranges from the beginning to the end of a day, and time
intervals, which are usually 10 s to 5 min, depend on the sampling resolution of the GPS devices.
Generally, narrow intervals, for example 10 s, are meaningless for traffic prediction. Thus, if the
sampling resolution is high, these data may be aggregated to obtain wider intervals, such as several
minutes.
In the space dimension, the selected trajectory is viewed as a sequence of dots with inner states,
including vehicle position, average speed, etc. This sequence of dots can be ordered simply and
linearly fitted into the y-axis, but may result in a high dimension and uninformative issues, because
the sequences of dots are redundant and a large number of regions in this sequence are stable and
lack variety. Therefore, to make the y-axis both compact and informative, the dots are grouped into
sections, each representing a similar traffic state. The sections are then ordered spatially with
reference to a predefined start point of a road, and then fitted into the y-axis.
Finally, a time-space matrix can be constructed using time and space dimension information.
Mathematically, we denote the time-space matrix by:
11 12 1
21 22 2
12
,,,
,,,
,,,
N
N
QQ QN
mm m
mm m
M
mm m
(1)
where N is the length of time intervals, Q is the length of road sections; the ith column vector of M is
the traffic speed of the transportation network at time i; and pixel m
ij
is the average traffic speed on
section i at time j. Matrix M forms a channel of the image. Figure 1 illustrates the relations among raw
averaged floating car speeds, time-space matrix, and the final image.
Figure 1. An illustration of the traffic-to-image conversion on a network.
2.2. CNN for Network Traffic Prediction
2.2.1. CNN Characteristics
The CNN has exhibited a significant learning ability in image understanding because of its
unique method of extracting critical features from images. Compared to other deep learning
architectures, two salient characteristics contribute to the uniqueness of CNN, namely, (a) locally-
connected layers, which means output neurons in the layers are connected only to their local nearby
input neurons, rather than the entire input neurons in fully-connected layers. These layers can extract
features from an image effectively, because every layer attempts to retrieve a different feature
regarding the prediction problem [31]; and (b) a pooling mechanism, which largely reduces the
number of parameters required to train the CNN while guaranteeing that the most important features
are preserved.
Figure 1. An illustration of the traffic-to-image conversion on a network.
2.2. CNN for Network Traffic Prediction
2.2.1. CNN Characteristics
The CNN has exhibited a significant learning ability in image understanding because of its unique
method of extracting critical features from images. Compared to other deep learning architectures,
two salient characteristics contribute to the uniqueness of CNN, namely, (a) locally-connected layers,
which means output neurons in the layers are connected only to their local nearby input neurons,
rather than the entire input neurons in fully-connected layers. These layers can extract features
from an image effectively, because every layer attempts to retrieve a different feature regarding the
prediction problem [
31
]; and (b) a pooling mechanism, which largely reduces the number of parameters
required to train the CNN while guaranteeing that the most important features are preserved.
剩余15页未读,继续阅读
2018-02-07 上传
2021-03-31 上传
2014-06-09 上传
2023-05-17 上传
2023-07-08 上传
2023-03-30 上传
2023-07-08 上传
2023-05-25 上传
2023-06-09 上传
2023-05-18 上传

Fun_He
- 粉丝: 19
- 资源: 104
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
