阿里搜索:HBase的10年演进与4000万QPS实战
181 浏览量
更新于2024-08-29
收藏 377KB PDF 举报
HBase在阿里搜索中的应用实践深入探讨了其在阿里巴巴庞大体系中的关键作用和实践经验。自2010年起,随着十余个版本的迭代,阿里搜索逐渐建立起对HBase的深度依赖。早期版本中,1.1.2版本存在明显的性能问题,但后续的1.1.3及以后版本经过了大量优化,提供了更稳定的性能。
阿里搜索的HBase集群规模庞大,单是在阿里搜索内部,就有超过3000个节点,最大集群更是超过了1500个,整个阿里集团的节点数量远超此规模。这种大规模集群使得HBase在处理高并发场景下表现出色,例如在去年双11期间,离线集群的每秒访问量能够超过4000万次,单机吞吐量高达10万次,即使在CPU使用率高达70%的情况下,仍能支持8000+QPS,充分体现了其高效的数据处理能力。
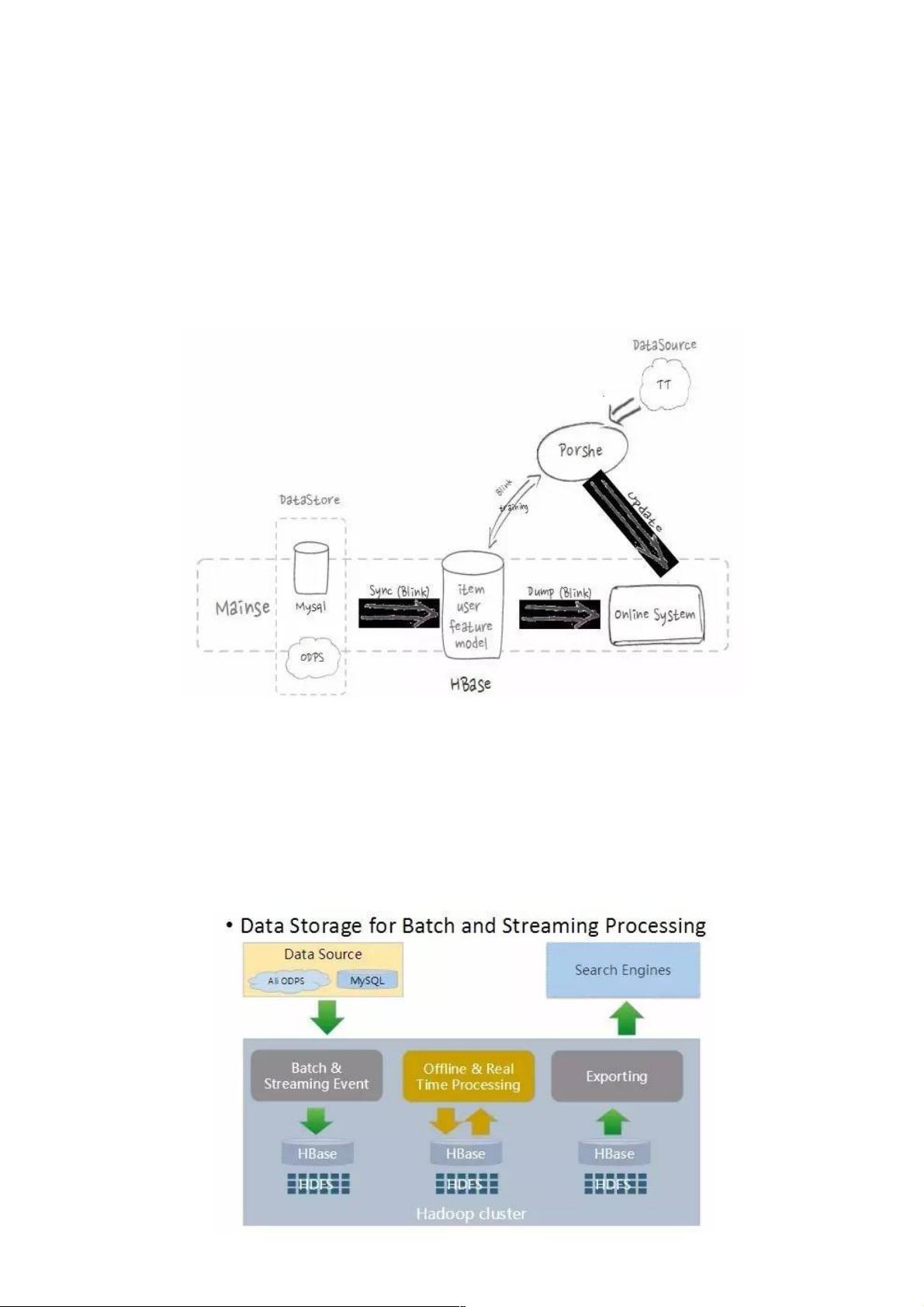
HBase在阿里搜索中扮演核心存储系统的角色,与计算引擎紧密协作,主要服务于搜索和推荐两大业务领域。索引构建过程中,HBase负责接收来自MySQL等在线数据库的商品和用户数据,通过流式处理实时导入并构建索引,确保搜索结果的实时性和准确性。对于推荐系统,Porshe机器学习平台将模型和特征数据存储在HBase中,实时用户行为数据也同步更新,从而不断优化推荐算法,提升用户体验。
另一个关键应用场景是机器学习。例如,在用户购物过程中,如果未找到满意的产品,HBase支持根据用户的搜索条件和历史行为,结合机器学习模型,实时调整搜索结果排序,让相关产品更优先出现在用户眼前,增强了个性化推荐的效果。
总结来说,HBase在阿里搜索中的应用涉及数据处理、实时分析和机器学习等多个层面,它不仅是存储和检索数据的基石,也是驱动搜索和推荐算法优化的重要组件。通过与高性能计算资源的集成,HBase确保了阿里搜索在面对海量数据和高并发请求时的稳定性和响应速度,对提升整体业务效率起到了至关重要的作用。
HBase在阿里搜索中的应用实践在阿里搜索中的应用实践
HBase 在阿里搜索的历史、规模和服务能力
历史:阿里搜索于 2010 年开始使用 HBase,从最早到目前已经有十余个版本。目前使用的版本是在社区版本的基础上经过大
量优化而成。社区版本建议不要使用 1.1.2版本,有较严重的性能问题,1.1.3 以后的版本体验会好很多。
集群规模:目前,仅在阿里搜索节点数就超过 3000 个,最大集群超过 1500 个。阿里集团节点数远远超过这个数量。
服务能力:去年双11,阿里搜索离线集群的吞吐峰值一秒钟访问超过 4000 万次,单机一秒钟吞吐峰值达到 10 万次。还有在
CPU 使用量超过 70% 的情况下,单 cpu core 还可支撑 8000+ QPS。
HBase 在阿里搜索的角色和主要应用场景
角色:HBase 是阿里搜索的核心存储系统,它和计算引擎紧密结合,主要服务搜索和推荐的业务。
上图是 HBase 在搜索和推荐的应用流程。在索引构建流程中,会从线上 MySQL 等数据库中存储的商品和用户产生的所有线
上数据,通过流式的方式导入到 HBase 中,并提供给搜索引擎构建索引。
在推荐流程中,机器学习平台 Porshe 会将模型和特征数据存储在 HBase 里,并将用户点击数据实时的存入 HBase,通过在
线 training 更新模型,提高线上推荐的准确度和效果。
应用场景一
索引构建
淘宝和天猫有各种各样的的线上数据源,这取决于淘宝有非常多不同的线上店铺和各种用户访问。
下载后可阅读完整内容,剩余6页未读,立即下载
2018-03-18 上传
2012-07-15 上传
2019-08-28 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-12-23 上传
点击了解资源详情
点击了解资源详情

weixin_38641366
- 粉丝: 4
- 资源: 893
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
