
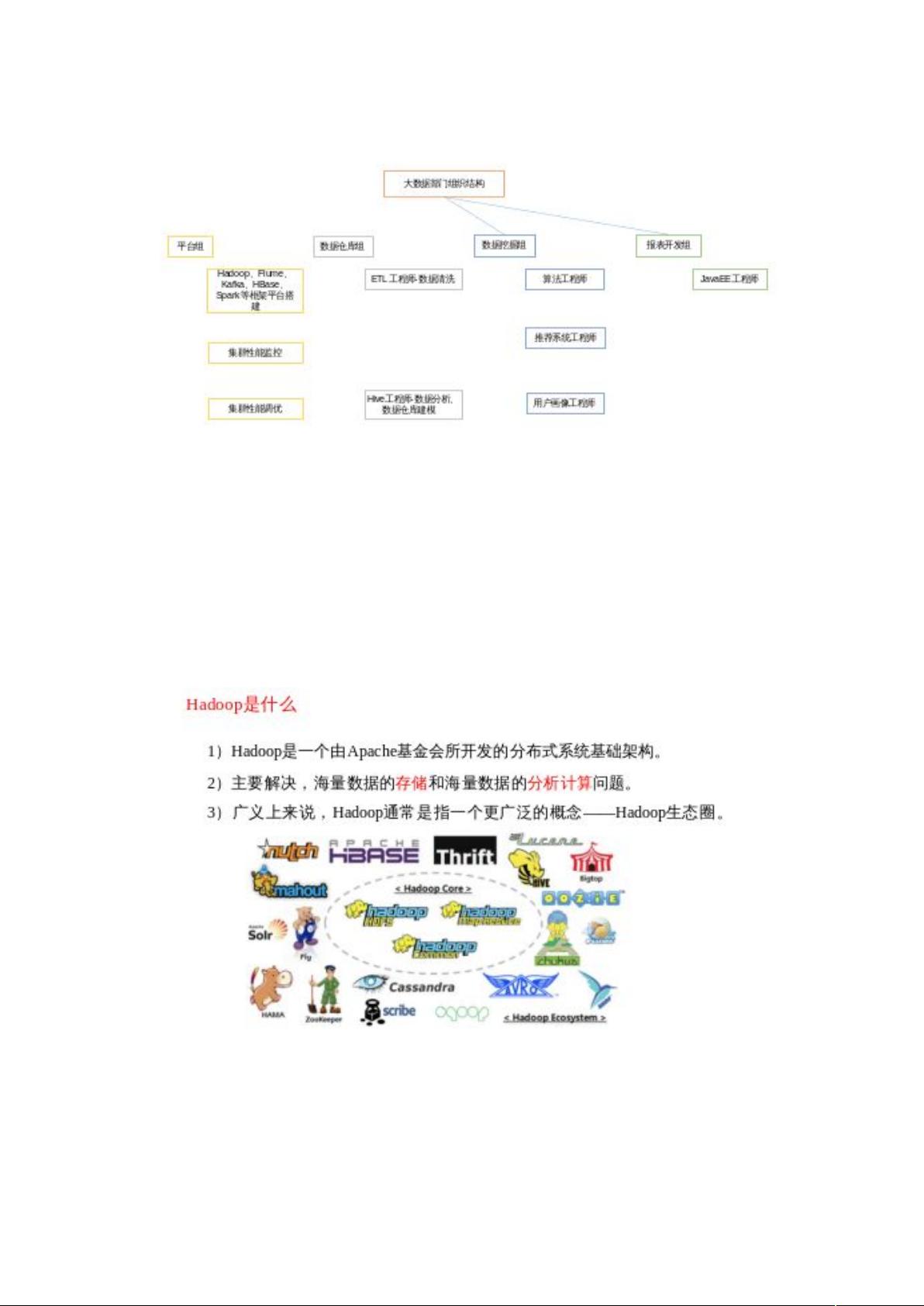
图 2-18 大数据部门组织结构
第 2 章 从 Hadoop 框架讨论大数据生态
2.1 Hadoop 是什么

剩余39页未读,继续阅读

呆痞ys
- 粉丝: 49
- 资源: 45
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 电力电子系统建模与控制入门
- SQL数据库基础入门:发展历程与关键概念
- DC/DC变换器动态建模与控制方法解析
- 市***专有云IaaS服务:云主机与数据库解决方案
- 紫鸟数据魔方:跨境电商选品神器,助力爆款打造
- 电力电子技术:DC-DC变换器动态模型与控制
- 视觉与实用并重:跨境电商产品开发的六重价值策略
- VB.NET三层架构下的数据库应用程序开发
- 跨境电商产品开发:关键词策略与用户痛点挖掘
- VC-MFC数据库编程技巧与实现
- 亚马逊新品开发策略:选品与市场研究
- 数据库基础知识:从数据到Visual FoxPro应用
- 计算机专业实习经验与项目总结
- Sparkle家族轻量级加密与哈希:提升IoT设备数据安全性
- SQL数据库期末考试精选题与答案解析
- H3C规模数据融合:技术探讨与应用案例解析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


