华为云上Scala实践:Spark集群3节点单词计数教程
需积分: 0 24 浏览量
更新于2024-06-30
收藏 2.04MB PDF 举报
实验三:Spark单词计数1
在这个实验中,学生将深入理解大数据处理框架Spark的核心概念和实际应用。首先,学生需要在华为云购买并配置3台服务器,其中一台作为主节点,其他两台作为从节点,构建一个Hadoop-YARN模式的Spark集群。实验目标包括:
1. **服务器配置实践**:学生将学习如何在华为云上购买服务器,选择合适的CPU架构(如鲲鹏计算),配置操作系统(CentOS 7.5)、JDK (1.8.0_131)、Scala (2.11.11)以及集成开发环境(IDEA IC-2017.2.7)。
2. **Scala编程基础**:通过单词计数任务,学生将熟悉如何使用Scala语言编写Spark程序,这有助于理解Spark Core的基本操作,如SparkRDD(Resilient Distributed Dataset,弹性分布式数据集)的工作原理。
3. **Spark集群运行**:实验的核心环节是将编写好的Scala程序部署到Spark集群上运行,这里涉及的是分布式计算技术的实际运用,包括将程序打包并在YARN上提交任务,监控任务进度和结果。
4. **Hadoop生态整合**:Hadoop集群的搭建不仅限于Spark,还包括HDFS(Hadoop Distributed File System)和YARN(Yet Another Resource Negotiator),它们共同支撑着整个大数据处理环境。
实验步骤详细指导了服务器购买、配置网络、操作系统安装、Hadoop集群的搭建流程,特别是YARN的资源管理和MapReduce与Spark的兼容性。通过这个过程,学生不仅能提升实际操作技能,还能加深对分布式计算、数据处理和集群管理的理解。
这个实验旨在通过实践操作,让学生掌握如何在大型分布式环境中使用Spark进行高效的数据处理,并且培养他们的问题解决能力,为后续的大数据分析项目打下坚实的基础。
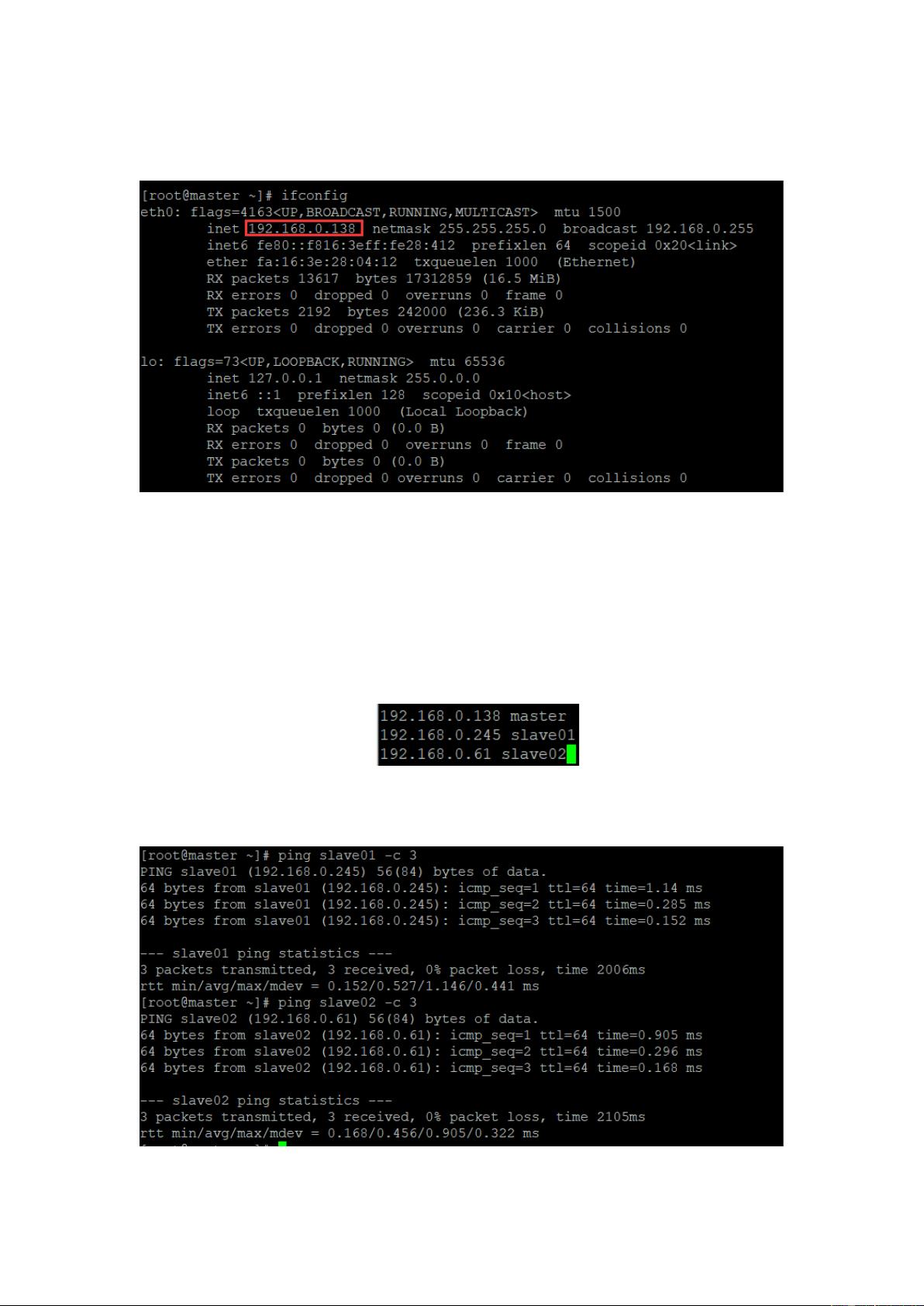
步骤 5:配置 hosts 列表(3 个节点都要配置,可以用 scp 复制到其他节点)
1)3 个节点分别运行 ifconfig 命令,获取当前节点的 ip 地址:
图 13
2)使用 vim /etc/hosts 命令编辑列表文件;
3)将下面三行添加到/etc/hosts 文件中,保存退出。这里 master 节点对应
IP 地址是 192.168.0.138,slave01 对应的 IP 是 192.168.0.245,slave02 对应
的 IP 是 192.168.0.61,而自己在做配置时,需要将 IP 地址改成自己的 master、
slave01 和 slave02 对应的 IP 地址。
图 14
4)测试是否能 ping 通:
图 15
剩余30页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-08 上传
点击了解资源详情
2021-11-24 上传
2024-05-05 上传
2024-04-30 上传
2022-05-12 上传









