Spark单词统计实验:从零开始到环境配置
版权申诉
5 浏览量
更新于2024-06-30
收藏 2.76MB PDF 举报
Spark单词统计实验是一个旨在帮助学生理解和应用Spark编程技术的实践项目。该实验的主要目的是通过编写一个SparkWordCount程序,让学生熟悉Scala语言,并掌握基于Spark的数据处理思想。实验的核心目标是让学生能够在Spark的计算框架中实现单词计数功能,同时了解如何在Spark Shell环境中运行代码和分析执行过程。
实验首先要求参与者检查Hadoop集群环境,确保所有Hadoop节点(如hadoop1、hadoop2和hadoop3)都已启动或按照相关教程进行配置。通过在每台节点上执行jps命令来验证Hadoop服务是否正常运行。如果集群未启动或者未完成安装,需要参考第1课的相关内容进行安装或部署。
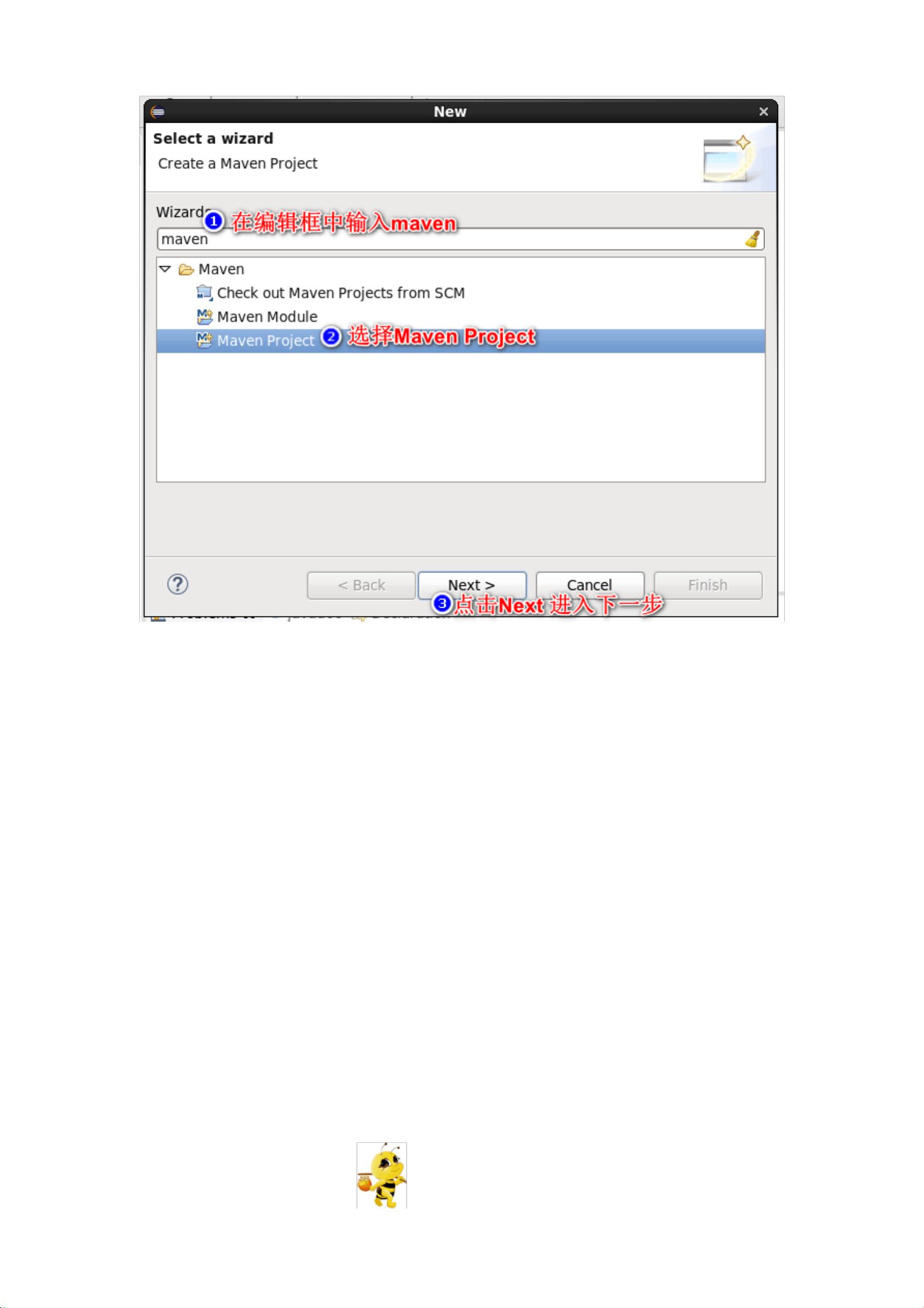
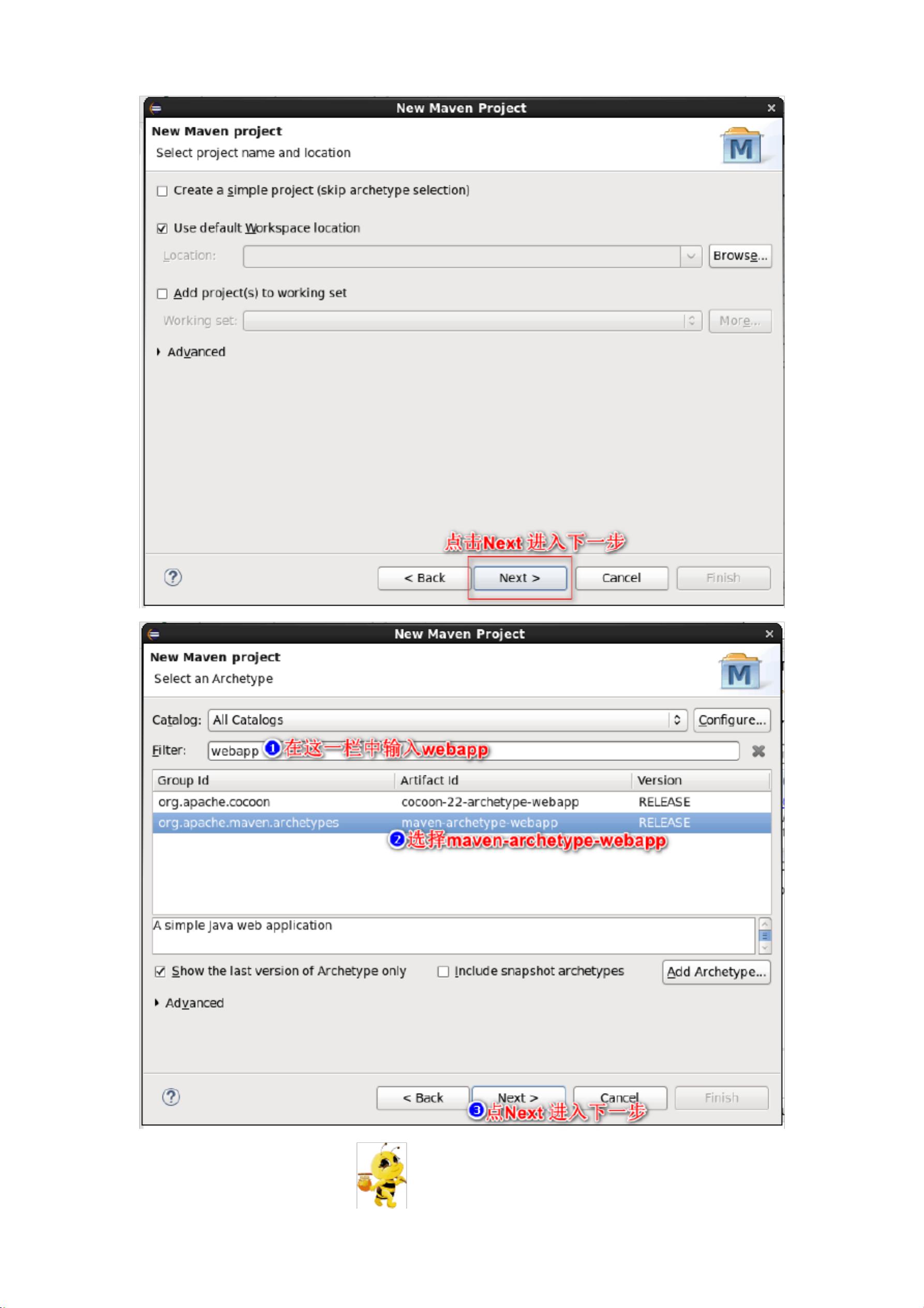
接着,学生需在Hadoop1的主节点上使用Eclipse创建一个新的Java Maven项目。步骤包括新建项目、设置JDK版本以及配置pom.xml文件。在pom.xml文件中,学生需要添加Spark相关的依赖,以便于后续项目的构建和运行。
实验的关键部分是将Spark单词统计的源码(可以从文档中复制)集成到项目中,这涉及到粘贴并替换现有的pom.xml文件中的代码段。源码中应包含基本的Spark应用程序结构,包括输入数据处理、分布式计算和结果输出等环节。
在实验过程中,学生需学会如何在Eclipse中运行代码,并观察SparkShell的执行情况。这可能包括查看任务分发、数据分区、并行计算以及最终结果的输出。通过这个过程,学生能够深入了解Spark的作业调度、数据分区和reduce操作等核心概念。
总结来说,这个Spark单词统计实验不仅锻炼了学生的编程技能,还加深了他们对大数据处理框架Spark的理解,以及如何利用其高效地处理大规模数据集。通过实际操作,学生能够更好地掌握分布式计算的原理和实践,为他们在IT领域进一步发展打下坚实基础。
旗开得胜
6
读万卷书 行万里路
剩余31页未读,继续阅读
2019-05-09 上传
2022-04-04 上传
2020-02-22 上传
2023-06-13 上传
2023-06-13 上传
2024-04-10 上传
2023-09-05 上传
2023-05-28 上传
2023-09-19 上传
2023-06-13 上传

xxpr_ybgg
- 粉丝: 6759
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







