在VMware上配置Linux系统下的Hadoop环境
需积分: 0 21 浏览量
更新于2024-07-24
收藏 2.82MB PDF 举报
"在VMware Workstation Linux系统下设置Hadoop环境"
在本文档中,我们将详细介绍如何在使用Windows操作系统的个人计算机上通过虚拟机(VMware Workstation v9.0.1)搭建Hadoop环境。Hadoop是一个开源的分布式计算框架,广泛用于大数据处理。对于那些主要使用Windows操作系统但希望进行Hadoop学习或开发的人来说,使用虚拟机是一个理想的选择。
**环境配置**
- 本地操作系统:Windows 7
- 虚拟机软件:VMware Workstation v9.0.1
- 虚拟操作系统:CentOS 5.4
**环境结构**
我们的环境由一台主节点(Master)和三台从节点(Slave)组成。无论是物理机还是虚拟机,每台机器都有其独立的IP地址。考虑到环境中可能有8台机器,因此必须确保所有IP地址不重复。
**步骤**
### 设置虚拟机
#### 步骤1:安装VMware
下载VMware的安装包,并像其他Windows应用程序一样进行安装。
#### 步骤2:在VMware上安装Linux系统
1. 启动VMware Workstation。
2. 创建新的虚拟机。选择“文件”->“新建虚拟机”,然后选择自定义(高级)选项并点击下一步。
3. 在“选择虚拟机硬件兼容性”对话框中,选择Workstation 9.0并点击下一步。
接下来的步骤将涉及配置虚拟机的具体硬件设置,如处理器数量、内存大小、网络连接类型(桥接模式、NAT模式或主机仅模式)以及磁盘空间等。通常,为了模拟真实的Hadoop集群,每台虚拟机应至少分配两个CPU核心,2GB以上的内存,并设置足够大的硬盘空间以存储数据和Hadoop日志。
**配置Linux系统**
安装完Linux后,需要进行必要的系统配置,包括用户权限设置、SSH密钥对生成、防火墙规则调整等。此外,还需要安装Java运行环境(JRE或JDK),因为Hadoop依赖Java来运行。
**安装Hadoop**
1. 下载Hadoop的tarball文件,通常是.tgz或.zip格式。
2. 解压缩到Linux系统的某个目录,如 `/usr/local/hadoop`。
3. 配置Hadoop环境变量,编辑 `~/.bashrc` 或 `~/.bash_profile` 文件,添加Hadoop的路径。
4. 使配置生效:`source ~/.bashrc` 或 `source ~/.bash_profile`。
5. 初始化Hadoop配置文件,如 `core-site.xml`, `hdfs-site.xml`, `mapred-site.xml`, `yarn-site.xml`,并根据集群规模和需求进行适当修改。
6. 格式化NameNode:`hdfs namenode -format`。
7. 启动Hadoop服务,包括DataNode、NameNode、ResourceManager、NodeManager等。
**集群配置**
在所有节点上完成Hadoop安装和配置后,需要确保它们能够相互通信。这包括在从节点上复制Master节点的Hadoop配置文件,并启动相同的Hadoop服务。同时,使用SSH无密码登录功能(通过ssh-keygen和ssh-copy-id命令实现)确保节点间可以免密通信。
**测试Hadoop集群**
最后,通过运行简单的MapReduce任务,如WordCount,来验证Hadoop集群是否正确配置和运行。
总结,搭建Hadoop环境涉及多个步骤,包括虚拟机的安装、Linux环境配置、Hadoop的安装与配置以及集群的组建和测试。遵循上述指南,可以在Windows环境下成功创建一个功能齐全的Hadoop集群。
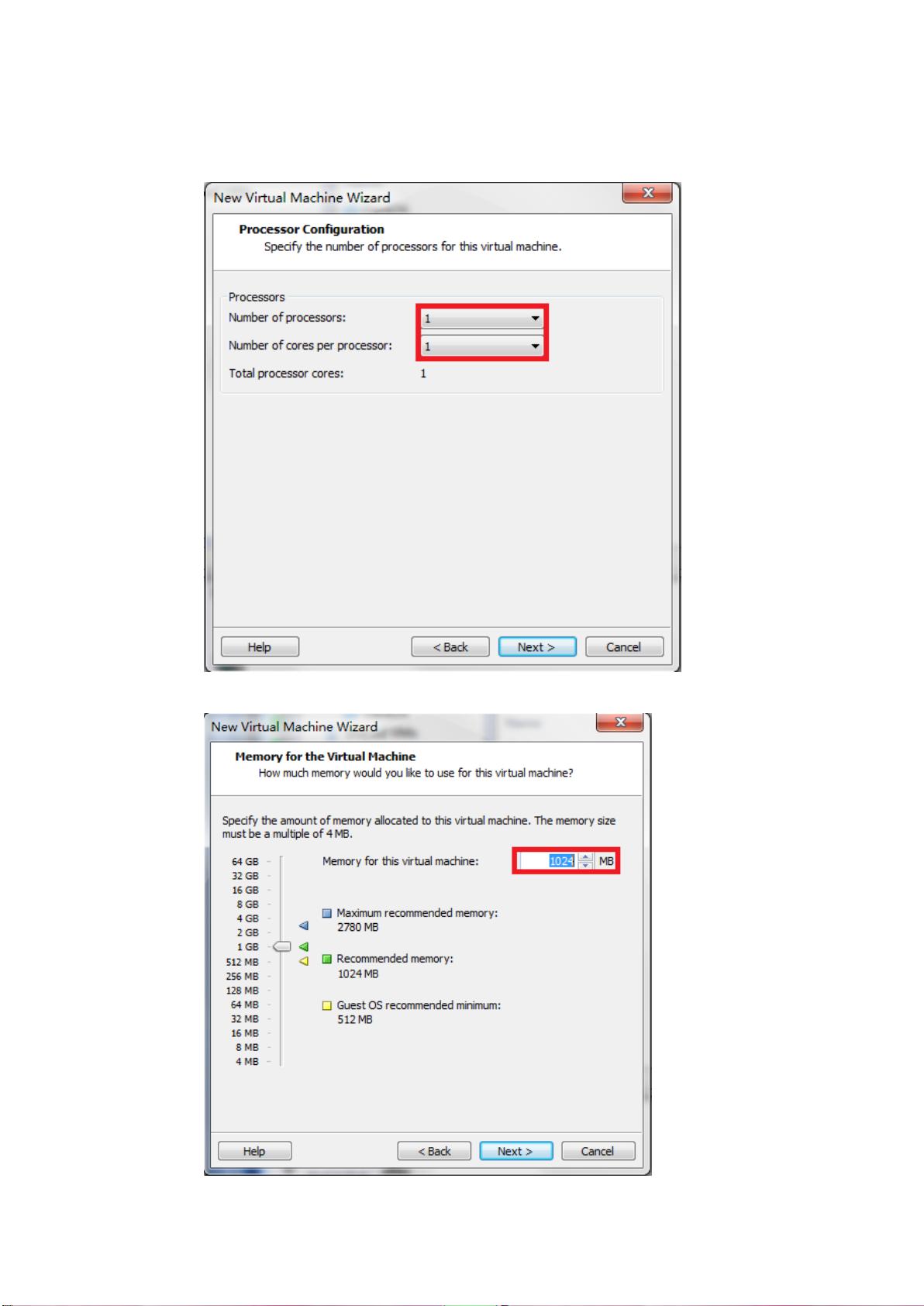
5
- In the “Processor Configuration” dialog window, set Number of processor and Number of
cores per processor be one like here.
- Please select memory size of 1 GB.
剩余22页未读,继续阅读
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

Hongmae1102
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
