
一、 实验介绍
题目链接:https://tianchi.aliyun.com/competition/entrance/231784/submission
本实验以预测二手车的交易价格为任务,本次实验的数据集包括 15 万条训练数据集,
5 万条测试集用于模型测试。作为大作业前的最后一次实验,目的是让大家对数据挖掘的完
整流程有一个基本的了解。以下是实验相关介绍:
train.csv:训练集,包含 31 列变量信息,其中 15 列为匿名变量,每辆车都有其二手
交易价格。
test.csv:测试集,包含 31 列变量特征,其中 15 列为匿名变量,每辆车的二手价格
是模型需要预测输出的,最后将预测结果以 submit.csv 文件格式输出,在提交结果处上传
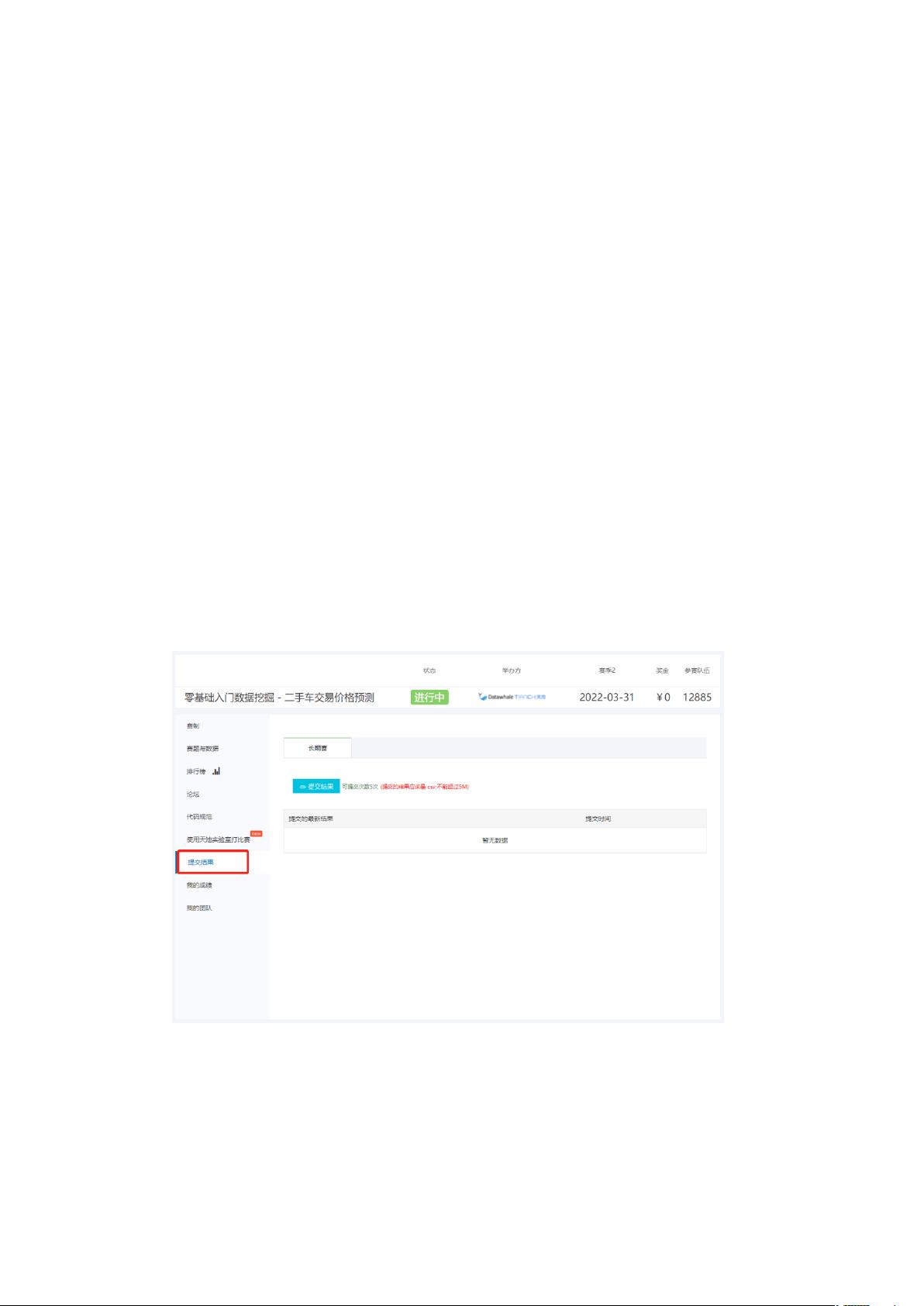
submit.csv 文件,如下图所示,网站会对你的提交进行验证,计算模型的性能指标,每天
可以提交三次测试。
下载后可阅读完整内容,剩余4页未读,立即下载

好运爆棚
- 粉丝: 31
- 资源: 342
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


