ReLU激活函数:解决梯度弥散问题的关键
 已收录资源合集
已收录资源合集
需积分: 0 49 浏览量
更新于2024-08-05
收藏 773KB PDF 举报
"这篇简书文章介绍了ReLU(Rectified Linear Units)激活函数,讨论了Sigmoid、Tanh等非线性激活函数的优缺点,并提到了ReLU如何缓解梯度消失问题。文章还提及了生物神经激活函数Softplus与ReLU的联系。"
在深度学习领域,激活函数是神经网络中的关键组成部分,它们引入非线性,使得神经网络能够学习更复杂的特征。ReLu,全称为Rectified Linear Units,是目前广泛使用的激活函数之一,尤其在卷积神经网络(CNNs)中表现优秀。
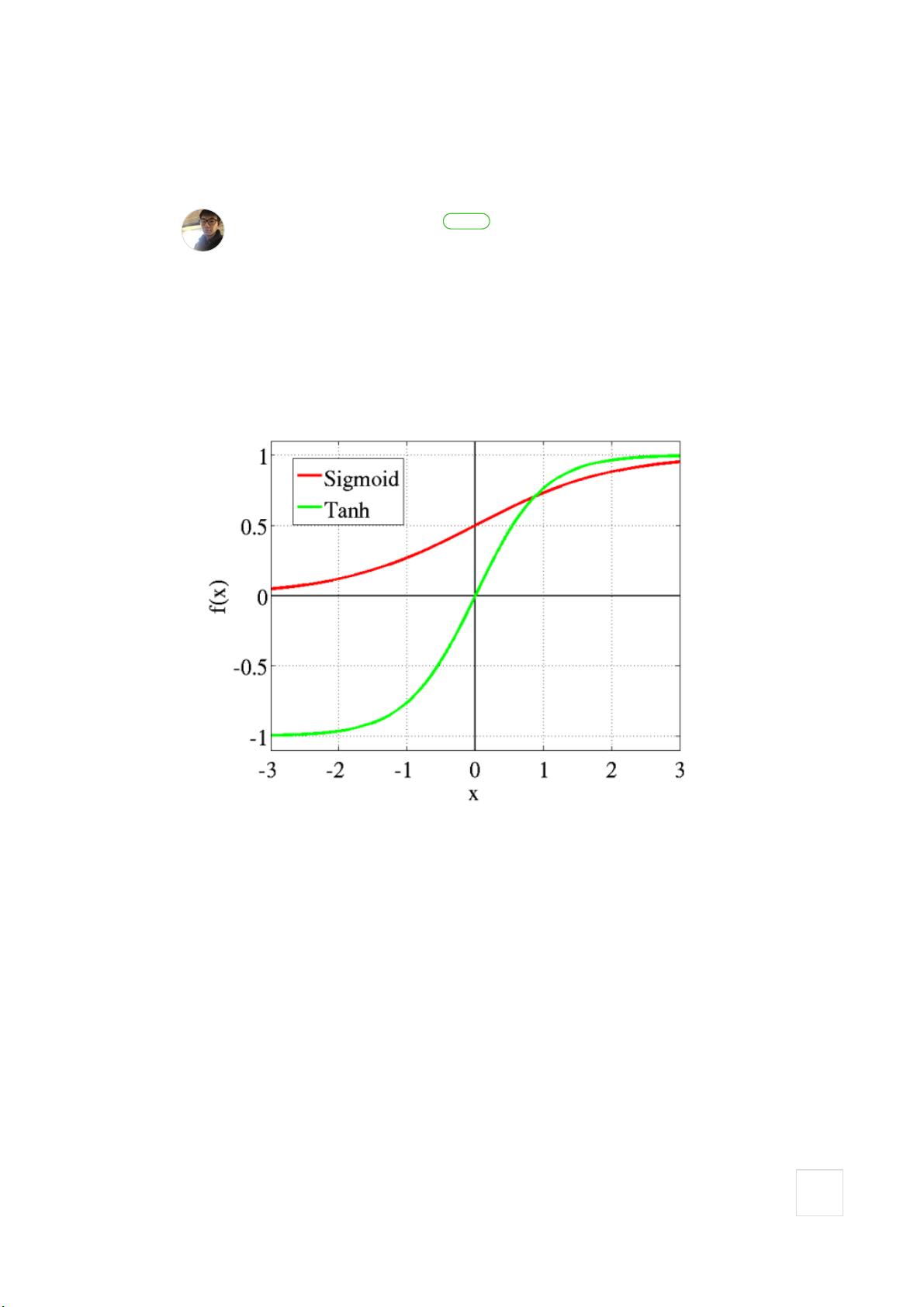
传统的激活函数如Sigmoid和Tanh在早期的神经网络中占据了重要地位。Sigmoid函数的输出值域在0到1之间,模拟了概率输出,且具有非线性特性,有助于特征的区分。然而,随着网络层次的增加,Sigmoid的梯度消失问题愈发严重,即在网络深层,反向传播的梯度值变得非常小,导致权重更新缓慢,训练过程近乎停滞。
相比之下,ReLU激活函数通过简单地将负值置零,保留正值不变,即f(x) = max(0, x),显著改善了梯度消失的问题。ReLU的直截了当使其在正区间内拥有恒定的梯度1,这极大地加快了训练速度。然而,ReLU的一个缺点是可能存在“死亡ReLU”问题,即当输入为负时,梯度为0,导致某些神经元无法更新,可能在训练过程中“死亡”。
此外,为了进一步优化ReLU,出现了Leaky ReLU(LReLU)和Parametric ReLU(PReLU)。LReLU在负区间不完全置零,而是设为一个小的斜率,从而减少了死亡ReLU的发生。PReLU则更进一步,其负区间的斜率是可学习的,可以根据数据动态调整。
Softplus激活函数可以视为ReLU的平滑版本,形式为f(x) = log(1 + e^x),它有一个连续的导数,避免了ReLU的阶跃性质可能导致的问题,但计算上稍复杂。
ReLU及其变体在解决梯度消失问题和提高训练效率方面取得了显著进展,成为了现代神经网络设计的首选激活函数。同时,这些函数的设计灵感来源于对生物神经元工作原理的理解,展现了理论与实践的结合。
2018/10/11 ReLu(Rectified Linear Units)激活函数 - 简书
https://www.jianshu.com/p/68d44a4295d1 1/5
ReLu(Rectified Linear Units)激活函数
(/u/d46138a62446)
牛肉咖喱饭 (/u/d46138a62446)
关注
2017.03.20 20:57* 字数 747 阅读 1248 评论 0 喜欢 2
Sigmoid函数以及传统线性函数
在ReLU激活函数出现之前,神经网络训练都是勇Sigmoid作为激活函数。其中Sigmoid
函数主要分为Logistic-Sigmoid和Tanh-Sigmoid,这两者被视为神经网络的核心所在。
因为Sigmoid函数具有限制性,输出数值在0~1之间,符合概率输出的定义。并且非线性
的Sigmoid函数在信号的特征空间映射上,对信号的中央区的信号增益比较大,对两侧的
信号增益小。从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑
制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧
区。从这点来看Sigmoid函数要比更加早期的线性激活函数(y=x),以及阶梯激活函数
的效果要好上不少。
但是当神经网络层数较多的时候,Sigmoid函数在反向传播中梯度值会逐渐减小,在经过
多层的反向传递之后,梯度值在传递到神经网络的头几层的时候就会变得非常小,这样
的话根据训练数据的反馈来更新神经网络的参数会变得异常缓慢,甚至起不到任何作
用。这种情况我们一般称之为梯度弥散(Gtadient Vanishment),而ReLU函数的出现很
大一部分程度上解决了梯度弥散的问题。
近似生物神经激活函数:Softplus & ReLu
2001年,神经科学家Dayan、Abott从生物学角度,模拟出了脑神经元接受信号更精确的
激活模型。
(/apps/redi
utm_sourc
banner-clic
下载后可阅读完整内容,剩余4页未读,立即下载
2019-12-21 上传
2022-08-03 上传
2023-05-29 上传
2023-05-05 上传
2023-08-02 上传
2023-03-27 上传
2023-06-01 上传
2023-06-09 上传
2023-05-28 上传

KerstinTongxi
- 粉丝: 25
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- RPSL:机器人感知规范语言(RPSL)
- 学生成绩管理系统(java实现).zip
- java11_64_bin.zip jdk11免费下载
- My-FreeCodeCamp-Code:我来自训练营的代码
- eulerian_video_magnification:实现欧拉视频放大并用于心率检测等
- pet-projects.dev-frontend:用于https:dev-pet-projects.github.io的Nuxt.js Buefy前端
- cpp代码-162.4.4.2
- matlab由频域变时域的代码-speaker-recognition:说话人识别
- 【课设警告】每个Java老师都喜欢的学生成绩管理系统.zip
- Amzl_Proto
- JSG202227 2022年江苏省职业院校技能大赛(高职) 电子产品芯片级检测维修与数据恢复 赛项规程.zip
- 9cc:小型C编译器
- yamame1212.github.io
- GAN_model:使用GAN生成3D网格模型
- 差异:用于生成字符串差异的简单gem
- Xshell7个人免费版
