"Hadoop源代码分析,主要集中在MapTask类及其相关辅助类的解析,包括MapTask的成员变量、run方法、Mapper的执行以及错误恢复策略。"
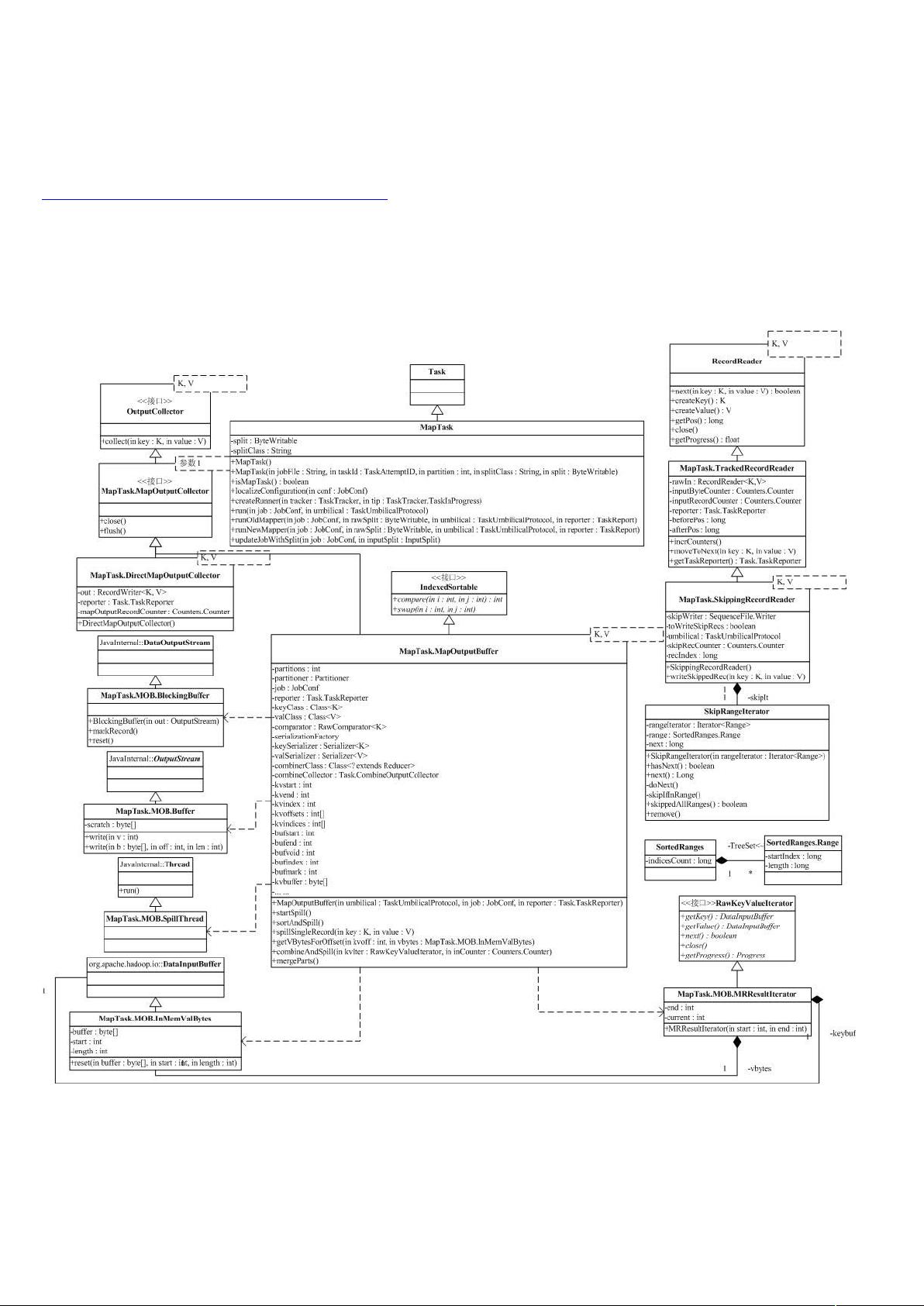
在Hadoop框架中,MapTask是处理Map阶段任务的核心类。MapTask的工作流程涉及到多个组件和步骤,这些在源代码中体现得尤为明显。MapTask的结构相对简洁,主要包含split和splitClass两个关键成员变量。split是BytesWritable类型,存储了InputSplit子类串行化的结果,用于表示数据集的一个分割部分。splitClass则是InputSplit子类的类名,允许通过反射机制动态实例化具体的InputSplit对象,以处理不同的数据输入格式。
MapTask的核心运行逻辑在其`run`方法中,首先配置TaskReporter,然后根据任务状态执行相应的设置和清理任务,最后执行Mapper。由于Hadoop同时维护了旧版和新版的API,因此MapTask需要同时支持`runNewMapper`和`runOldMapper`。这两个方法分别对应新旧API下的Mapper执行逻辑,执行完毕后,MapTask会调用父类的`done`方法来标记任务完成。
`runOldMapper`方法是Mapper执行的核心,首先它会根据InputSplit来构造Mapper处理的数据输入,更新任务配置。Mapper的输入通常由RecordReader类处理,RecordReader读取输入数据并转化为键值对供Mapper处理。在`runOldMapper`中,RecordReader有两种实现:正常的TrackedRecordReader和用于错误恢复的SkippingRecordReader。
错误恢复策略是MapReduce的重要特性,特别是在处理大规模数据时。当Map阶段遇到部分错误数据,为了避免整个任务失败,系统可能会选择跳过这些错误记录,继续处理其他数据。SkippingRecordReader在这种情况下发挥作用,它能够跳过一定数量的错误记录,确保任务可以继续进行,而不影响整体结果的准确性。
Hadoop的MapTask源代码分析涉及了任务执行流程、输入处理、错误恢复等多个关键点,对于理解Hadoop MapReduce的工作原理具有重要意义。通过深入源代码,开发者可以更好地优化任务性能,调试问题,以及定制适合特定场景的解决方案。


 我的内容管理
展开
我的内容管理
展开









