探索Hadoop集群架构与网络深度解析
需积分: 10 64 浏览量
更新于2024-07-24
收藏 1.59MB PDF 举报
深入理解Hadoop集群和网络是IT领域中的重要课题,尤其是在云计算的大背景下。Hadoop作为一个开源的大数据处理框架,其高效性和容错性使得它在分布式计算中占据核心地位。本文由经验丰富的数据中心和云网络专家Brad Hedlund撰写,他结合自身实践和Cloudera的培训资料,为读者提供了深入剖析。
首先,Hadoop集群的架构分为三个主要部分:Client机器、主节点(也称为主控节点或NameNode)和从节点(DataNodes)。Client机器负责集群的配置管理,它不参与实际的数据处理,而是作为数据的入口点,负责数据的上传、提交任务描述以及结果的接收。主节点负责Hadoop的核心服务,如Hadoop Distributed File System (HDFS)的命名空间管理和MapReduce任务的调度,即JobTracker。名称节点主要关注文件系统的元数据存储和管理,而数据的存储和计算则主要由从节点执行,它们既是数据存储单元也是与主节点进行通信的守护进程。
在小型集群中,由于资源有限,可能会在一台物理服务器上同时承载JobTracker和名称节点,这可能导致性能瓶颈。然而,在大型生产环境中,通常会采用专门的服务器来处理这些核心任务,避免资源的混合使用,提升性能和稳定性。Hadoop设计初衷是充分利用Linux系统,直接操作底层硬件,这意味着它在虚拟化环境下的表现也相当出色,能够在性能、成本和易用性上达到极高的水平。
网络在Hadoop集群中扮演着至关重要的角色,它不仅连接各个节点进行数据传输,还影响着整个系统的延迟和带宽。优化网络配置,如选择适当的网络协议(如TCP/IP)、调整网络带宽和延迟,以及确保良好的网络拓扑设计,对于提高Hadoop集群的整体效率至关重要。此外,网络故障容错和安全措施也是集群设计时不容忽视的部分。
深入理解Hadoop集群和网络,意味着掌握如何构建一个高效、稳定且可扩展的数据处理平台,其中包括节点角色划分、网络策略、性能调优以及安全性考量。这对于IT专业人士和希望在大数据领域发展的人来说,是一门必不可少的技术知识。
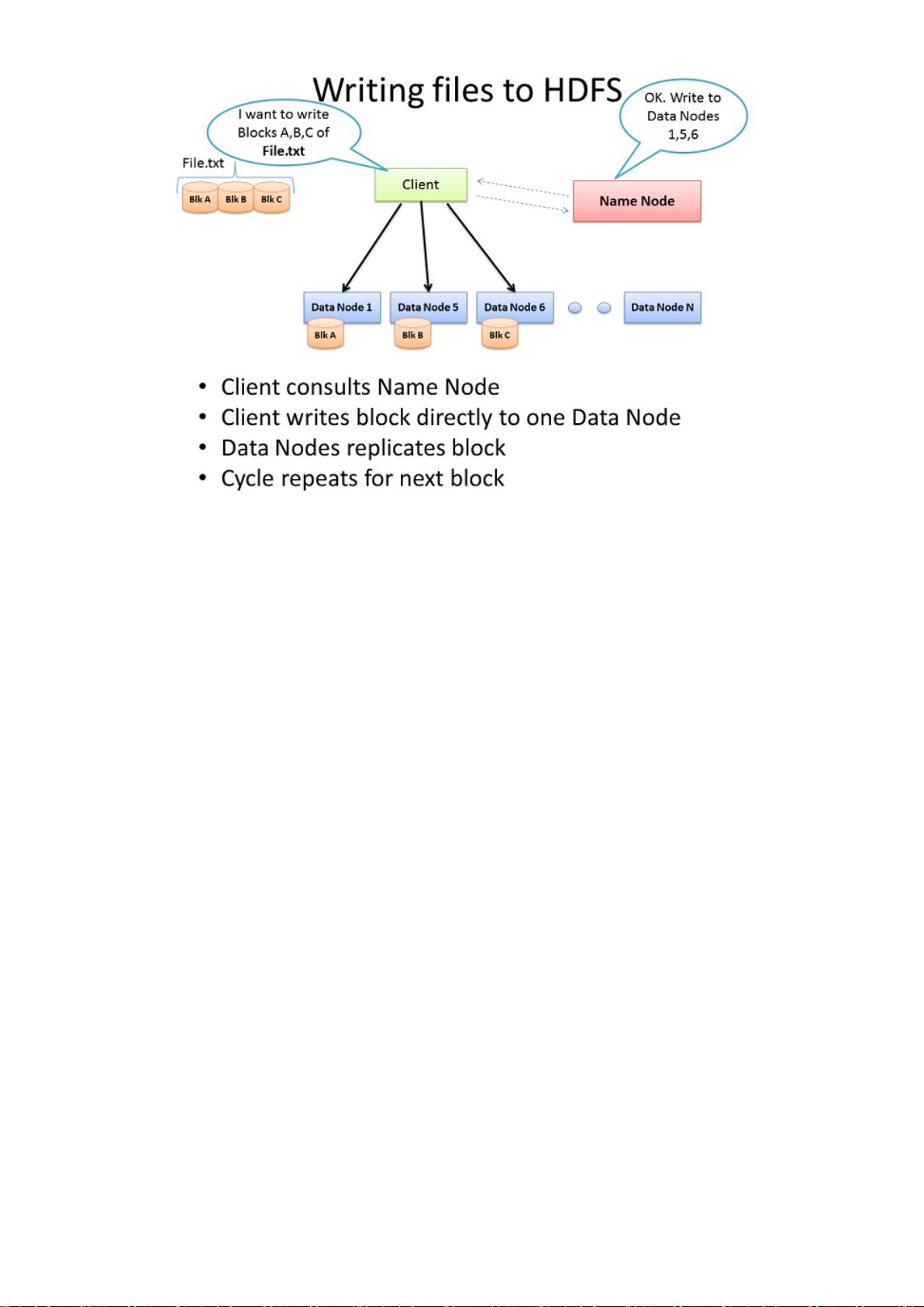
向 HDFS 里写入 File
Hadoop 集群在没有注入数据之前是不起作用的,所以我们先从加载庞大的 File.txt 到集群中开始。首要的目标当然是数据快速的并
行处理。为了实现这个目标,我们需要竟可能多的机器同时工作。最后,Client 将把数据分成更小的模块,然后分到不同的机器上贯
穿整个集群。模块分的越小,做数据并行处理的机器就越多。同时这些机器机器还可能出故障,所以为了避免数据丢失就需要单个数
据同时在不同的机器上处理。所以每块数据都会在集群上被重复的加载。Hadoop 的默认设置是每块数据重复加载 3 次。这个可以通过
hdfs-site.xml 文件中的 dfs.replication 参数来设置。
Client 把 File.txt 文件分成 3 块。Cient 会和名称节点达成协议(通常是 TCP 9000 协议)然后得到将要拷贝数据的 3 个数据节点列
表。然后 Client 将会把每块数据直接写入数据节点中(通常是 TCP 50010 协议)。收到数据的数据节点将会把数据复制到其他数据节
点中,循环只到所有数据节点都完成拷贝为止。名称节点只负责提供数据的位置和数据在族群中的去处(文件系统元数据)。
剩余16页未读,继续阅读
2013-09-24 上传
点击了解资源详情
点击了解资源详情
480 浏览量
点击了解资源详情
点击了解资源详情
139 浏览量
2010-07-12 上传
121 浏览量

chqf518
- 粉丝: 13
- 资源: 218
 我的内容管理
展开
我的内容管理
展开







最新资源
- 红色扁平化商务幻灯片图表PPT模板
- 油漆:大学编程项目。 一个创建和处理.ppm图像文件的程序
- 函数的嵌套_函数的嵌套_
- sortme:角度节点数据排序应用
- Django Example
- 个人博客程序,基于CodeIgniter+Mysql.zip
- Currency-exchange:货币汇率Web App
- cpAPI:一种Flask API,可提供有关各种编码平台上即将举行的比赛的更新
- sf__wordpress_experimental
- object-oriented-[removed]面向对象的 Javascript 类项目
- amnehj.github.io
- valuePal:使用JavaScript,redux和react构建的基本库存分析工具
- FANUC CNC Screen Display funciton 软件.rar
- Yeonlisa-DataStructure
- StoryTeller:在非个人化的Zoom连接已成为常态的时代,我们如何培养社区和创造力? Enter StoryTeller-快节奏的游戏,带出玩家的创造力
- FindStr_FindString_SearchUnicodeString_TheProgram_
