深度学习中的目标检测算法详解
需积分: 0 18 浏览量
更新于2024-07-01
1
收藏 7.18MB PDF 举报
"08_第八章_目标检测1 - 深入介绍SPPnets及其在目标检测中的应用,特别是其共享特征映射的计算,以及如何根据对象提议在共享特征映射上进行操作。本资源涵盖了目标检测的基本概念、TwoStage和OneStage算法、人脸检测方法以及常用的数据集和标注工具。"
在计算机视觉领域,目标检测是一项关键任务,它涉及到识别和定位图像中的特定物体。这一章深入讲解了目标检测的概念、技术及其应用。首先,定义了目标检测是识别并框定图像中的对象,解决的问题包括准确地定位物体并分类它们。目标检测算法通常分为两类:TwoStage和OneStage。
TwoStage算法,如R-CNN、Fast R-CNN、Faster R-CNN、R-FCN和FPN(Feature Pyramid Network),先生成候选区域,再进行细化的分类和定位。R-CNN使用Selective Search生成候选框,然后送入预训练的CNN进行特征提取,最后用SVM或线性分类器进行分类。Fast R-CNN改进了R-CNN,通过RoIPooling层直接在全卷积网络的特征图上进行操作,提高了速度。Faster R-CNN进一步引入了Region Proposal Network (RPN),使其成为端到端可训练的系统。R-FCN则尝试消除RoIPooling,直接对全卷积网络的输出进行分类。FPN利用多尺度信息生成特征金字塔,提升了小目标检测性能。
OneStage算法,如SSD(Single Shot MultiBox Detector)、DSSD、YOLO系列(YOLOv1、YOLOv2、YOLOv3、YOLO9000)和RetinaNet、RFBNet、M2Det等,尝试直接从特征图预测边界框和类别,简化了流程,提高了速度。例如,SSD通过不同大小和形状的锚框来覆盖不同尺度的目标,而YOLO系列以其实时性能和简洁架构著名,YOLOv3则引入了空间金字塔池化(SPP),解决了不同尺度目标检测的挑战。RetinaNet则通过Focal Loss解决了类别不平衡问题。
在人脸检测方面,有多种方法,如级联卷积神经网络(Cascade CNN)、多任务卷积神经网络(MTCNN)、Facebox等。级联CNN通过一系列弱分类器逐步排除非人脸区域,提高检测精度。MTCNN则同时进行人脸检测、对齐和关键点检测,实现高效的人脸处理。Facebox是一种快速且准确的人脸检测算法,结合了深度学习和传统方法的优点。
目标检测的常用数据集包括PASCAL VOC(提供20个类别)、MS COCO(涵盖80个类别)、Google Open Image和ImageNet。这些数据集用于训练和评估各种目标检测模型。此外,高效的标注工具如LabelImg、labelme、Labelbox、RectLabel、CVAT和VIA等,帮助研究人员和开发者方便快捷地创建标注数据。
目标检测是一个复杂而重要的任务,涉及到多阶段和单阶段的算法设计,以及在人脸检测等特定场景的应用。随着深度学习技术的发展,这一领域的研究和实践持续取得突破,为自动驾驶、智能监控、图像分析等领域提供了强大的支持。

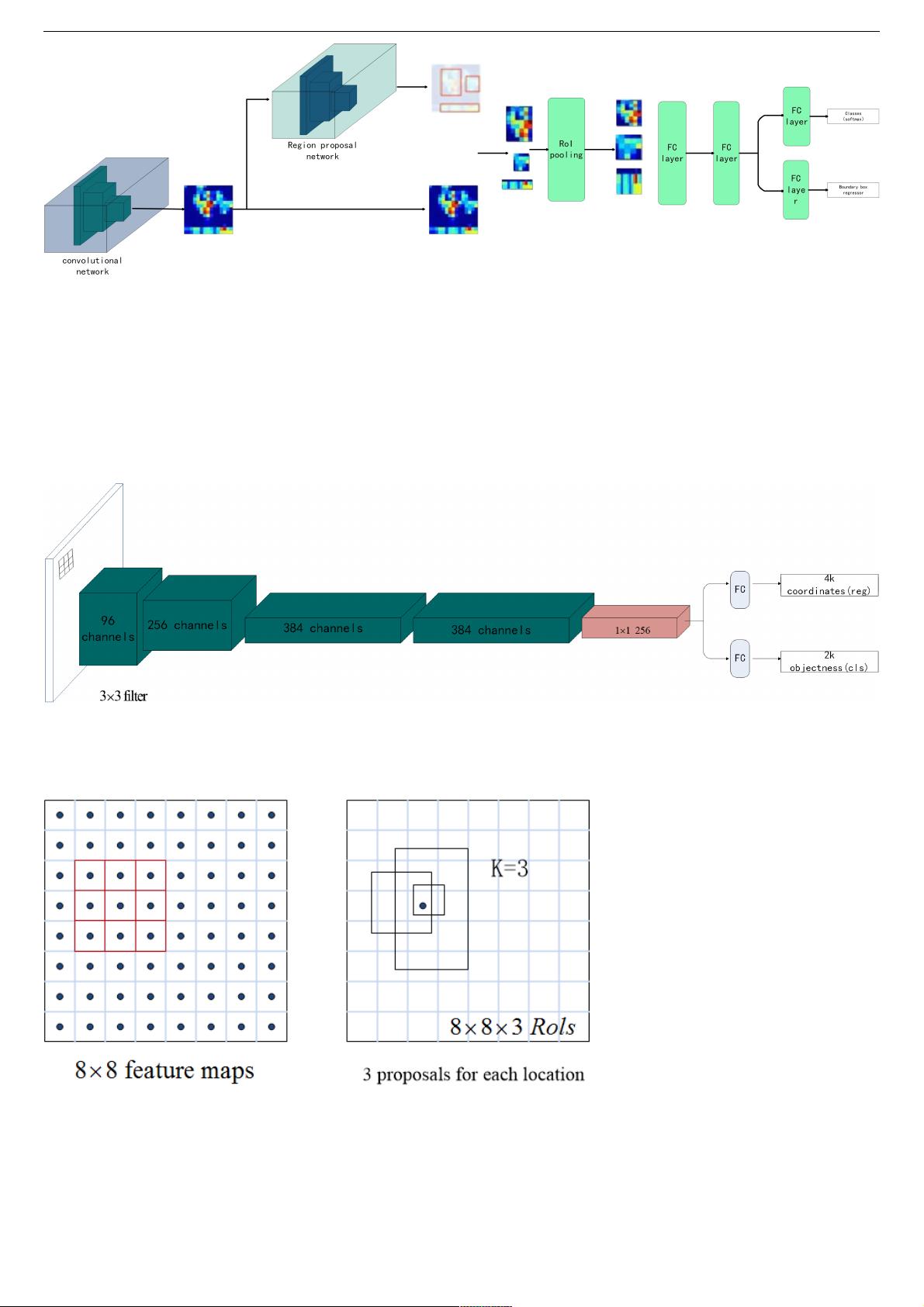
8.2.3 Faster R-CNN
Faster R-CNN有哪些创新点?有哪些创新点?
Fast R-CNN依赖于外部候选区域⽅法,如选择性搜索。但这些算法在CPU上运⾏且速度很慢。在测试中,Fast R-CNN需要
2.3秒来进⾏预测,其中2秒⽤于⽣成2000个ROI。Fast er R-CNN采⽤与Fast R-CNN相同的设计,只是它⽤内部深层⽹络代
替了候选区域⽅法。新的候选区域⽹络(RPN)在⽣成ROI时效率更⾼,并且以每幅图像10毫秒的速度运⾏。
图8.1.13 Faster R-CNN的流程图
Faster R-CNN的流程图与Fast R-CNN相同,采⽤外部候选区域⽅法代替了内部深层⽹络。
第⼋章 ⽬标检测
7/52
剩余54页未读,继续阅读
2023-08-23 上传
2020-07-27 上传
2022-08-03 上传
2023-05-19 上传
2023-09-03 上传
2023-05-18 上传
2023-05-30 上传
2023-05-29 上传
2023-02-18 上传

KerstinTongxi
- 粉丝: 25
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
