Impala与Hive实时查询性能对比分析
需积分: 9 58 浏览量
更新于2024-09-10
收藏 188KB DOC 举报
"这篇文章主要探讨了Impala与Hive之间的差异,强调了Impala在大数据查询方面的实时性和高效性。作者提到了Impala的架构,包括Impalad、StateStore和CLI组件,以及它们各自的功能。文章还描述了Impalad如何处理查询请求,以及StateStore如何维护集群健康状态。"
在大数据分析领域,Impala和Hive是两种常见的数据查询工具。Impala是由Cloudera开发的,灵感来源于Google的Dremel系统,设计目标是提供实时的交互式SQL查询能力,避免Hive使用MapReduce带来的延迟问题。与Hive相比,Impala通过使用类似于传统并行关系数据库的分布式查询引擎,显著提高了查询速度。
Impala的架构主要由三个核心组件构成:Impalad、StateStore和CLI。Impalad是运行在DataNode上的进程,它负责接收和执行客户端的查询请求。作为查询协调器,它解析SQL,生成执行计划,并将任务分配给其他拥有所需数据的Impalad。每个Impalad还与StateStore保持连接,以获取集群健康信息和任务分配。
StateStore是监控和管理Impalad状态的关键组件。它维护所有Impalad的心跳信息,确保故障检测和恢复。如果StateStore暂时离线,Impalad仍能继续工作,但由于无法更新状态信息,可能会导致某些节点的故障无法被及时识别。
CLI(命令行接口)允许用户直接与Impalad交互,执行SQL查询。此外,Impalad还运行着多个ThriftServer,如beeswax_server、hs2_server和be_server,分别用于不同目的,如连接客户端、利用Hive元数据以及内部通信。
Impala通过其优化的架构和组件设计,提供了比Hive更快的查询性能,更适合需要实时分析和快速响应的场景。而Hive则更倾向于批处理作业,适合长时间运行的复杂分析任务。理解这两者的区别对于选择合适的大数据分析工具至关重要。
Impala
与
Hive
的比较
Posted by
jzou
on 2013 年 7 月 12 日
Tweet 35
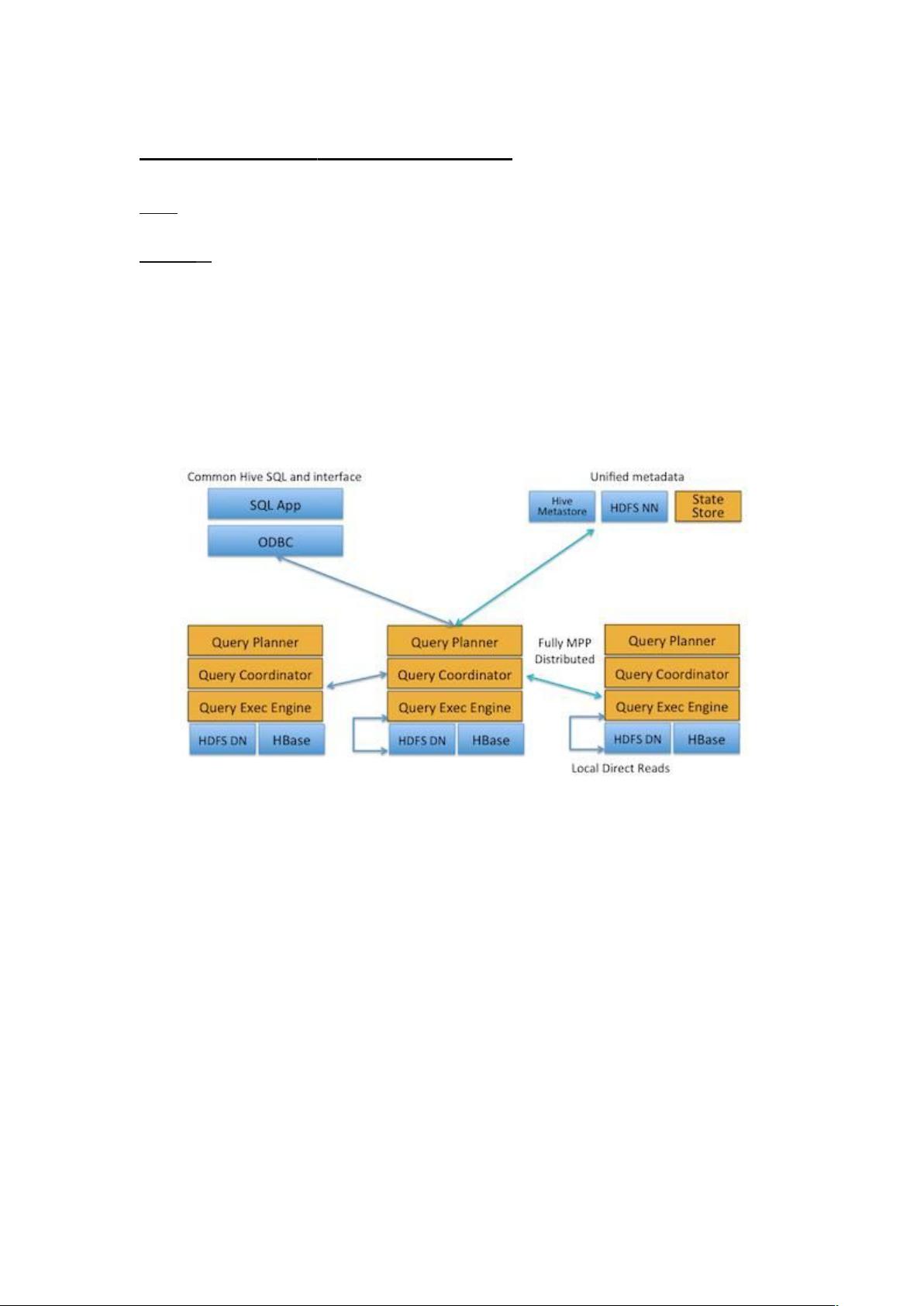
1. Impala 架构
Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互 SQL
大数据查询工具,Impala 没有再使用缓慢的 Hive+MapReduce 批处理,而是通
过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query
Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直
接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了
延迟。其架构如图 1 所示,Impala 主要由 Impalad, State Store 和 CLI 组成。
图 1
Impalad: 与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接
收客户端的查询请求(接收查询请求的 Impalad 为 Coordinator,Coordinator
通过 JNI 调用 java 前端解释 SQL 查询语句,生成查询计划树,再通过调度器把执
行计划分发给具有相应数据的其它 Impalad 进行执行),读写数据,并行执行查
询,并把结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客
户端。同时 Impalad 也与 State Store 保持连接,用于确定哪个 Impalad 是健康
和可以接受新的工作。在 Impalad 中启动三个 ThriftServer:
beeswax_server(连接客户端),hs2_server(借用 Hive 元数据),
be_server(Impalad 内部使用)和一个 ImpalaServer 服务。
Impala State Store: 跟踪集群中的 Impalad 的健康状态及位置信息,
由 statestored 进程表示,它通过创建多个线程来处理 Impalad 的注册订阅和与
各 Impalad 保持心跳连接,各 Impalad 都会缓存一份 State Store 中的信息,当
State Store 离线后(Impalad 发现 State Store 处于离线时,会进入 recovery
模式,反复注册,当 State Store 重新加入集群后,自动恢复正常,更新缓存数
下载后可阅读完整内容,剩余6页未读,立即下载
2014-08-23 上传
2017-04-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

xinbl0829
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- spring security 2.0.x 中文版参考手册
- spring security 2.0.x reference documentation
- Java2参考大全(第四版)
- 设计模式-英文版(Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides)
- JSR179 开发指南 MIDP_Location_API-Developers_Guide_v2_0_en.pdf
- Vss项目管理工具安装-使用
- blazeds_devguide.pdf
- C语言全本,不错的资料
- Boost.Thread
- Sharepoint2007单点登录
- 编程优秀数据推荐,绝对经典!
- Microsoft Visual C# 2008 Step by Step.pdf(E文)
- Office+SharePoint+Server+2007+部署图示指南
- ASP.NET 2.0入门经典-2
- JSF in Action 中文版
- IBM COGNOS CONFIGURATION 用户指南
