Impala与Hive实时查询性能对比
10 浏览量
更新于2024-08-27
收藏 266KB PDF 举报
"Impala与Hive的比较"
在大数据处理领域,Impala和Hive都是广泛使用的工具,但它们在设计和性能上有显著区别。Impala是由Cloudera基于Google的Dremel理念开发的实时交互式SQL查询系统,而Hive则是Facebook开源的一个基于Hadoop的数据仓库工具,最初设计用于批处理分析。
1. 架构对比
- Impala架构强调低延迟和高性能。它的核心组件包括Impalad、StateStore和CLI。Impalad是Impala的主要工作进程,与Hadoop DataNode一起运行,负责处理客户端查询请求,执行并返回结果。它包含三个ThriftServer,分别用于客户端连接、Hive元数据支持和内部通信。StateStore则监控Impalad的健康状态和位置信息,确保集群的高可用性。
- Hive则依赖于MapReduce进行计算,这使得查询响应时间较长,适合离线批量处理。Hive架构中,HiveServer2处理客户端请求,Metastore服务存储元数据,而HiveQL是其SQL方言。
2. 查询处理
- Impala采用与传统并行数据库相似的分布式查询引擎,包括QueryPlanner、QueryCoordinator和QueryExecEngine,可以避免Hive的MapReduce开销,直接在数据存储层执行查询,提高了查询速度。
- Hive通过HQL解析SQL,转换为MapReduce任务执行,这增加了额外的转换时间,不适合实时查询。
3. 性能与延迟
- Impala由于其设计,能够在亚秒级别完成查询,适合实时分析和交互式查询。
- Hive的延迟较高,通常需要几分钟甚至更长时间,更适合批量数据处理和报告生成。
4. 兼容性与扩展性
- Impala可以直接读取HDFS和HBase,提供了更多的数据源选择。
- Hive对Hadoop生态系统有很好的集成,可以处理多种数据格式,包括ORC和Parquet,且与Pig、Spark等工具兼容良好。
5. 使用场景
- Impala适用于需要快速响应的业务智能、实时分析和数据探索场景。
- Hive则更适合离线数据分析、ETL流程和大数据批处理任务。
6. CLI与接口
- Impala的CLI提供了命令行查询接口,方便用户直接操作。
- Hive也有自己的CLI,同时支持ODBC和JDBC,允许与各种BI工具集成。
总结来说,Impala和Hive在大数据查询和分析上有各自的专长和适用场景。Impala以实时交互和低延迟见长,而Hive则以批处理和广泛的数据生态支持著称。选择哪一个工具取决于具体的应用需求和性能要求。
Impala与与Hive的比较的比较
1. Impala架构
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的
Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query
Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数
据,从而大大降低了延迟。其架构如图 1所示,Impala主要由Impalad, State Store和CLI组成。
图 1
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为
Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给
具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给
Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可
以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数
据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处
理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线
后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复
正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据
无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC
使用接口。
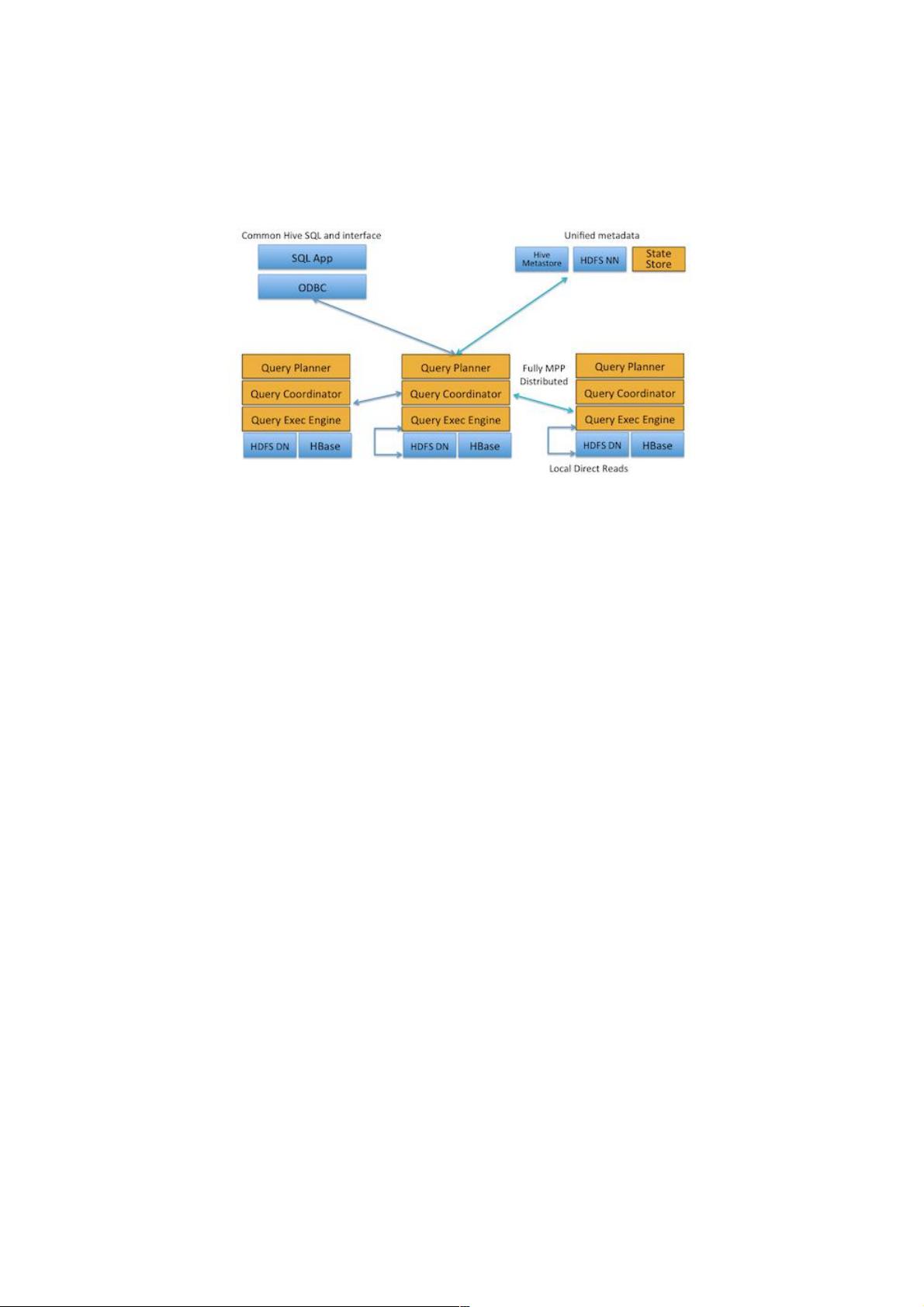
2. 与Hive的关系
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很
多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在
Hadoop中的关系如图 2所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给
数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在
Hive处理后的结果数据集上进行快速的数据分析。
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2016-05-09 上传
2022-08-08 上传
2018-05-23 上传
点击了解资源详情
点击了解资源详情
2023-10-28 上传

weixin_38685694
- 粉丝: 4
- 资源: 899
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网络通信 组播技术白皮书
- 用友软件公司内部《编程规范》
- Javascript题目
- hibernate经典书籍
- Struts中文手册详解.pdf
- Good Features to Track.pdf
- checkstyle standard
- arm7中文技术参考 高清pdf
- IPv6 Advanced Protocols Implementation
- 常用ARM指令集及汇编 pdf
- c#聊天系统加解密.txt
- KMP 字符串模式匹配详解
- i3(internet indirection infrastructure).pdf
- 中国联通互联网短信网关协意
- JDBC API 数据库编程 实作教程
- c语言学习教程--高质量c编程指南
