华为Sx700交换机配置与报价指南解析
需积分: 9 135 浏览量
更新于2024-07-16
收藏 10.05MB PPTX 举报
"华为Sx700系列交换机配置报价及操作指导"
华为Sx700系列交换机是一款专业级别的网络设备,主要用于企业级的园区网络建设。这款交换机提供了高度灵活的配置选项,以满足不同规模和复杂性的网络需求。在配置和报价过程中,华为提供了两个主要的工具——UniSTAR eCFG和UniSTAR SCT,以帮助用户进行离线和在线的配置与报价。
1. UniSTAR eCFG 是一款专业的离线配置报价工具,它使得技术人员能够详细地定制Sx700交换机的配置,包括选择合适的主机箱、主控板、交换网板、光模块、软件和License等。此外,它还支持集群电缆和安装辅料的配置,确保整个系统的完整性和稳定性。
2. UniSTAR SCT 是一个在线配置报价工具,设计简洁,适合快速生成配置方案。它不仅简化了配置过程,还可以作为下单工具,方便用户直接进行购买。特别地,SCT允许用户在配置时切换不同的机型,适应不同的网络环境需求。
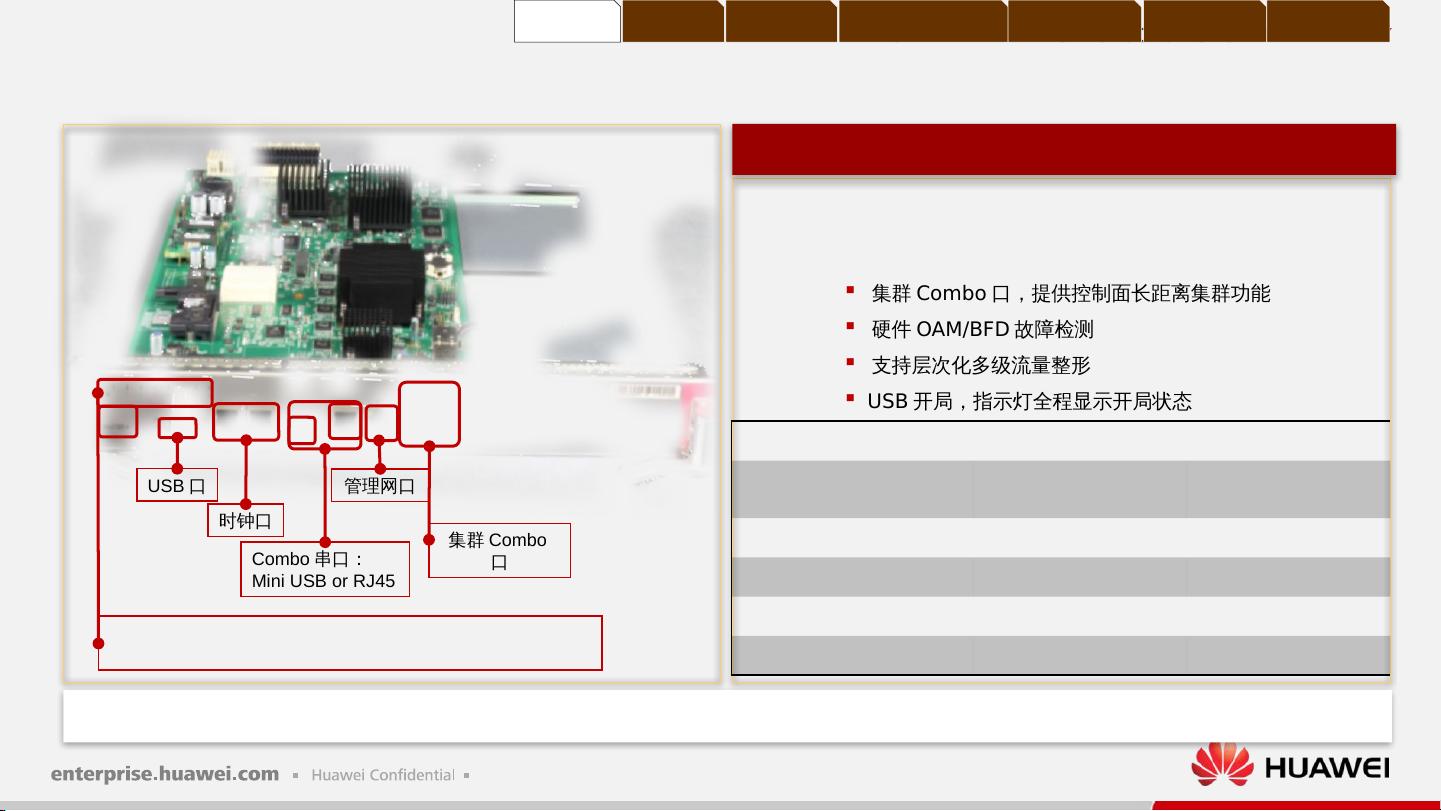
在华为Sx7系列交换机中,S12700是其中的一款框式交换机,具备强大的性能和扩展性。其配置指导涵盖了主机箱、主控板(如MPUA)、交换网板(如SFUA、SFUC、SFUD)以及各种接口模块。例如,MPUA主控板提供了管理网口、集群Combo口、USB开局和时钟口等功能,确保了高效管理和稳定运行。交换网板如SFUA和SFUD则提供了高带宽处理能力,可达到160Gbps至1.28Tbps,且具有集群能力,最大可扩展到1.92Tbps。
集群功能是S12700的一个显著特点,它支持 Combo口的控制面长距离集群,同时硬件OAM/BFD故障检测增强了网络的可靠性。此外,设备还配备了OFL按钮,按下后可安全拔出板卡,避免业务中断。集中监控板(CMU)则负责监控业务板的电源状态、风扇速度、温度等,确保设备的健康运行。
在配置过程中,需要注意的是,不同型号的交换网板有其特定的适用范围,如S12712不支持SFUC网板,而S12708在满配SFUA时有一个黄金槽位,提供480G独立带宽。所有这些细节都需要在配置时仔细考虑,以确保所选配置符合实际需求并达到预期的网络性能。
华为Sx700系列交换机提供了全面的配置工具和详尽的指导材料,以帮助用户根据自身需求构建高效、稳定的企业级网络。无论是对于初次接触的用户还是经验丰富的网络管理员,这些工具和资源都能提供宝贵的协助。
11
集群 Combo 口,提供控制面长距离集群功能
硬件 OAM/BFD 故障检测
支持层次化多级流量整形
USB 开局,指示灯全程显示开局状态
USB 口
Combo 串口:
Mini USB or RJ45
时钟口
MPUA 介绍
管理网口
集群 Combo
口
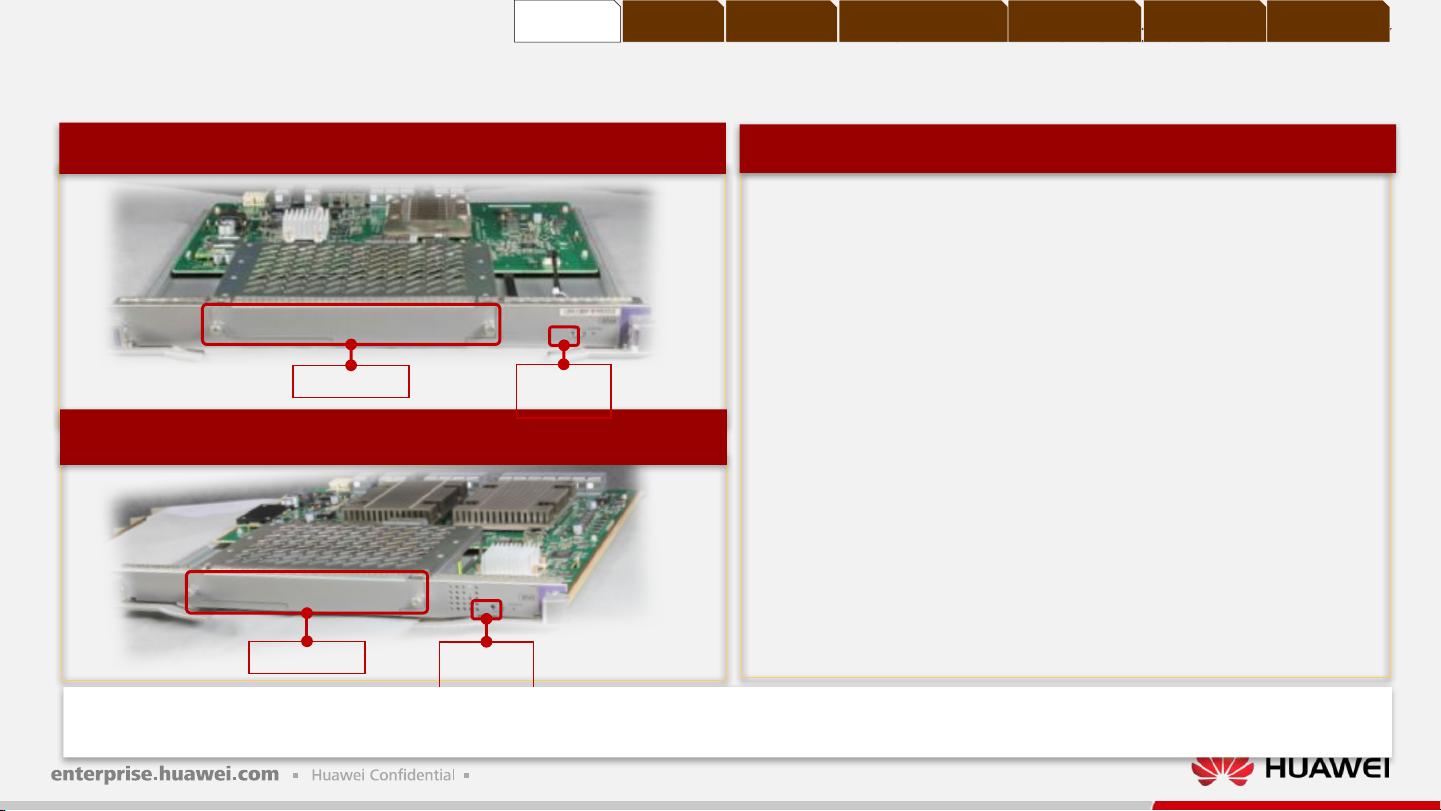
S12700 全系列通用主控单板
功能介绍:
CSS Master 灯:亮表示主,灭表示备
CSS ID :八个指示灯,亮表示该框在集群系统中的集群 ID
功能
S12700
友商
硬件 BFD ( 50ms 检测倒
换)
支持 不支持
集群状态指示灯 支持 不支持
集群 ID 指示灯 支持 不支持
USB 开局 支持 不支持
控制面集群 支持 不支持
全新主控板: MPUA
配置 TIPS :推荐使用“双主控”,可实现主控 1+1 冗余配置实现热备份,提高系统稳定性。
主设备 业务板 光模块
软件和
license
安装辅料 其他需求集群电缆

剩余63页未读,继续阅读
2021-10-11 上传
2021-10-11 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

tomtoshow
- 粉丝: 1
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
